* 본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
1. Introduction
이 논문은 단안 RGB 이미지로부터 정확하고 강력한 3D 손 자세 복원을 목표로 합니다. 이 문제는 손의 높은 관절 자유도, 깊이의 모호성, 가림 현상 등으로 인해 매우 어렵습니다. 기존의 방법들은 파라메트릭과 비파라메트릭 방법으로 나뉩니다. 파라메트릭 방법은 손 모델을 통해 낮은 차원의 파라미터를 추정하는 방식으로, 모델의 사전 지식을 통해 그럴듯한 손 자세를 보장하지만 비선형 회귀와 공간 정보 손실로 인해 정확도가 떨어집니다. 비파라메트릭 방식은 이미지에서 직접 키포인트나 메쉬 좌표를 추정하여 더 높은 정확도를 제공하지만, 안정성이 부족할 수 있습니다.이 논문에서는 두 방법의 장점을 결합하여 전역 모델링과 국부 정밀화라는 단계적 과정을 제안합니다. 먼저 전역 특징을 통해 초기 예측을 수행하고, 그 후 다중 해상도 맥락적 특징을 통합하여 픽셀 수준에서 정밀한 정보 추출을 가능하게 합니다. 또한, 약지도 학습(weakly-supervised learning) 방식을 통해 소수의 자세 주석만으로도 손 자세와 메쉬를 복원할 수 있는 가능성을 제시하며, 실험을 통해 제안된 방법의 성능을 입증합니다 .
2. Related Work
논문은 3D 손 자세 복원에서 사용되는 두 가지 주요 방법인 Non-parametric method 과 Parametric method 방법을 다룹니다.
Non-parametric method:
비파라메트릭 방법은 크게 회귀 기반과 탐지 기반 방법으로 나눌 수 있습니다. 초기 회귀 기반 방법은 이미지로부터 손 메쉬 또는 자세를 직접 예측했습니다. 하지만 손의 높은 자유도(DoF) 때문에 회귀 기반 방법은 정확도가 떨어졌습니다. 이후 연구에서는 손의 생체 역학적 제약을 도입하여 성능을 개선하거나 그래프 컨볼루션 네트워크(GCN)를 사용하여 손의 구조를 추적하는 방식이 제안되었습니다. 예를 들어, GCN 기반 방법은 손의 각 지점을 그래프로 표현하고, 이를 통해 공간 정보를 보존하면서 손의 자세와 메쉬를 더 정확하게 예측할 수 있습니다. 또한 탐지 기반 방법은 주로 2D 또는 2.5D 표현(예: 히트맵)을 예측하여 손의 자세와 메쉬를 복원합니다.
Parametric method:
파라메트릭 방법은 미리 정의된 손 모델을 사용하여 손의 저차원 파라미터를 예측합니다. 이 방법은 손 모델의 사전 지식을 사용하여 그럴듯한 손 자세를 보장하지만, 비선형 회귀와 공간 정보 손실로 인해 정확도에 한계가 있습니다. 최근 연구에서는 이러한 단점을 보완하기 위해 전역 특징과 국부적인 시각적 특징을 결합한 방식을 사용하고 있습니다.
* 탐지 기반 방법에서 말하는 "탐지"는 주로 2D 히트맵(heatmap)이나 확률 맵을 예측하는 방식을 의미.
Hybrid method:
많은 연구에서는 두 방법의 장점을 결합하는 방식이 주목받고 있습니다. 구체적으로, 일부 방법들은 2D 관절 위치 또는 2.5D 히트맵 같은 시각적 단서를 사용하여 파라메트릭 모델의 성능을 향상시키고자 합니다. 이러한 방법들은 주로 전역-국부 결합 프레임워크에서 진행되며, 이로써 해결 공간을 효율적으로 탐색하고 성능을 향상시킵니다 .
3. Method
3.1. Preliminary
Hand Model
이 논문에서는 MANO 모델을 사용하여 손의 초기 자세를 예측합니다. MANO 모델은 다음과 같이 정의됩니다:
\[
M = W(\beta, \theta)
\]
여기서 \( W \)는 선형 블렌딩 스키닝(linear blend skinning)을 나타내며, \( \beta \)는 손의 모양 파라미터, \( \theta \)는 손의 자세 파라미터를 의미합니다. 그 후, 3D 관절 좌표 \( P_{3D} \)는 미리 정의된 리그레서를 통해 다음과 같이 계산됩니다:
\[
P_{3D} = J M
\]
또한 2D 좌표 \( P_{2D} \)는 이미지 평면에서 다음과 같이 계산됩니다:
\[
P_{2D} = s(P_{3D}) + t
\]
여기서 \( s \)와 \( t \)는 약한 원근 카메라 모델에서의 스케일과 이동을 나타냅니다.
Graph Convolution Network (GCN)
GCN은 손 자세 추정에서 널리 사용되며, 장거리 종속성을 모델링하는 데 효과적입니다. GCN 연산은 다음과 같이 표현됩니다:
\[
F' = \mathcal{G}(F) = \sigma(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} F W)
\]
여기서 \( F \)는 입력 노드 특징, \( W \)는 학습 가능한 가중치 행렬, \( \tilde{A} \)는 그래프의 인접 행렬(자기 연결 포함), \( \sigma \)는 활성화 함수, \( \tilde{D} \)는 인접 행렬의 차수 행렬입니다.

3.2. Overview
이 논문은 전역 정보와 국부 공간 인식을 통합한 방식으로 3D 손 자세 복원을 목표로 합니다. 이를 위해 복원 과정을 전역 모델링과 국부 정밀화로 분리하고, coarse-to-fine 방식으로 수행합니다.
방법 개요:
- 보조 작업 사전학습: 다중 해상도의 시각적 및 보조 특징을 생성하여 맥락적 정보를 제공합니다. 이를 통해 손 복원 작업의 해 공간을 줄이고, 정확성을 높입니다.
- 전역 모델링: 전역 특징을 활용하여 손의 초기 자세를 예측하며, 이는 전역적인 사전 정보를 제공합니다.
- 국부 정밀화: 초기 예측을 기반으로 국부적인 픽셀 단위의 정렬을 수행하여 세밀한 정보를 추출하고, 이를 통해 정밀한 손 자세 복원이 가능합니다.
이 과정은 약지도 학습으로 확장될 수 있으며, 적은 주석 데이터만으로도 손 자세와 메쉬를 정확하게 복원할 수 있음을 실험으로 입증합니다 .
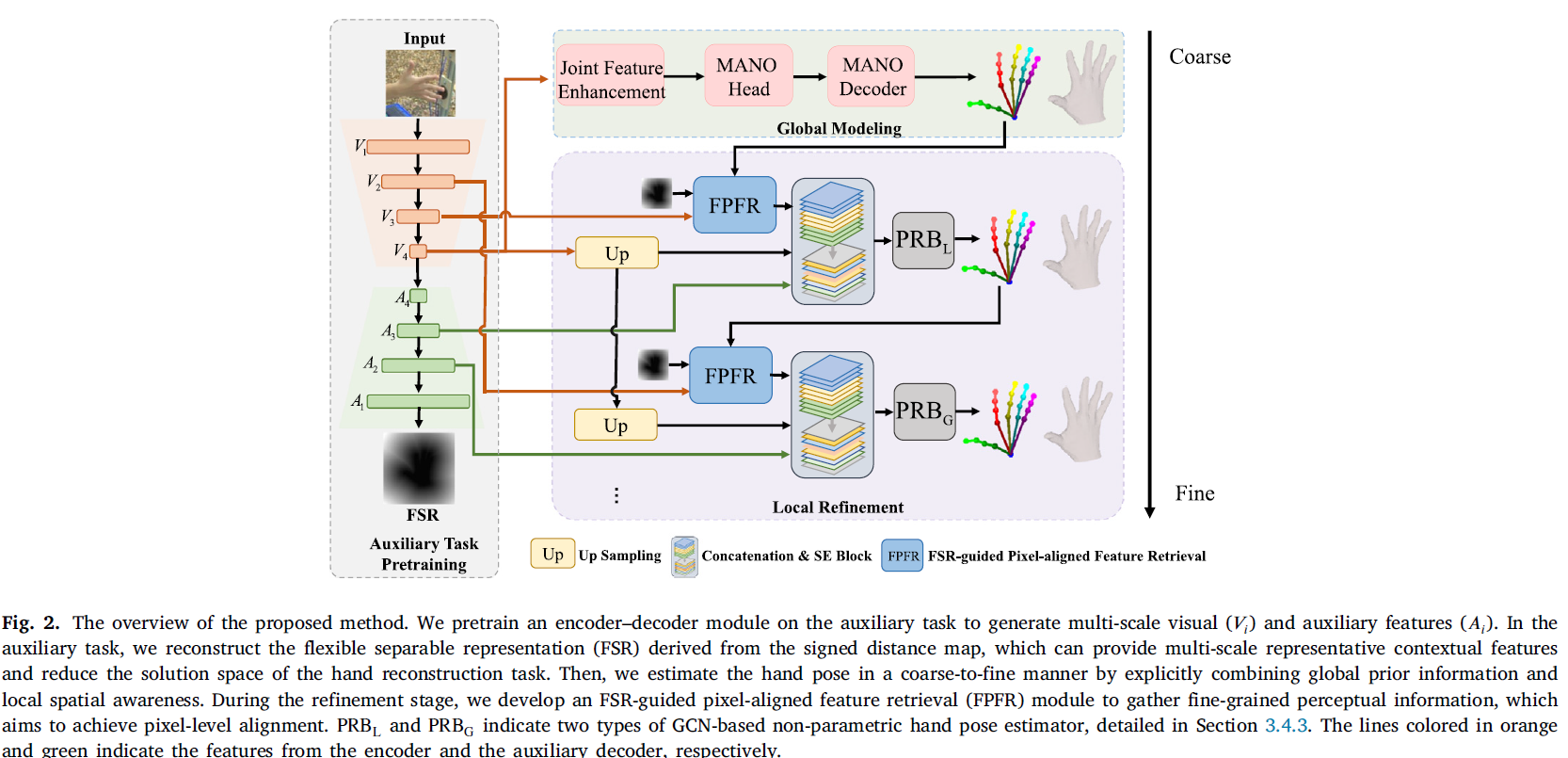
3.3. Auxiliary task pretraining
손 자세 복원에서 보조 작업(auxiliary task)은 해결 공간을 줄이기 위해 중간 특징(예: 손 세분화 및 밀집 대응 맵)을 제공하도록 설계됩니다. 이 논문에서는 FSR (Flexible Separable Representation)을 제안하며, 이는 손 경계에 대한 픽셀 수준의 상관성을 반영합니다. 이 FSR은 다음과 같은 수식으로 계산됩니다:
\[
\mathcal{T}(x) =
\begin{cases}
+ \min_{y \in \partial S} \| x - y \|_2, & x \in S_{in} \\
0, & x \in \partial S \\
- \min_{y \in \partial S} \| x - y \|_2, & x \in S_{out}
\end{cases}
\]
여기서 \( x \)와 \( y \)는 이미지 내의 두 점을 나타내며, \( \partial S \)는 손 영역의 경계, \( S_{in} \)과 \( S_{out} \)은 각각 손 영역의 내부와 외부를 나타냅니다. FSR을 사용하면 현재 손 자세와 관련된 픽셀 수준의 상관성을 이용해 모델이 손 자세 복원 작업의 해결 공간을 줄이도록 돕습니다.
이러한 픽셀 단위 정보를 통해 FSR은 자세 세밀화 중 픽셀 정렬 보정을 수행할 수 있습니다. 또한, 다중 해상도의 맥락적 특징을 추출하기 위해 보조 작업을 사전 학습합니다.
3.4. Coarse-to-fine pose reconstruction
손의 높은 자유도(DoF)로 인해 손 자세를 직접 예측하는 것은 어렵습니다. 따라서, 본 논문에서는 정확하고 강력한 손 자세 복원을 위해 coarse-to-fine전략을 구현합니다.
1) 초기 손 자세 예측:먼저, 파라메트릭 손 모델을 통해 초기 손 자세 \( P_J^I \)를 예측하여 손에 대한 사전 지식을 제공합니다.
2) 전역 및 국부 정보 통합:초기 예측된 자세를 기반으로 전역 표현과 국부 표현을 명시적으로 결합하여 자세를 정교화합니다. 이를 위해 FPFR(FSR-guided pixel-aligned feature retrieval) 모듈을 설계하여 픽셀 단위에서의 정렬을 수행하고, 전역 및 국부 정보가 더 잘 협력할 수 있도록 개선합니다.
\[
F_J = \mathcal{G}(\phi(F_I))
\]
여기서 \( \phi \)는 이미지 특징 \( F_I \in \mathbb{R}^{B \times C \times H \times W} \)를 관절 특징 \( F_J \in \mathbb{R}^{B \times D \times H*W} \)로 변환하는 함수이며, \( B \)는 배치 크기, \( D \)는 관절 수, \( C \), \( H \), \( W \)는 채널 및 공간 해상도를 나타냅니다.
3) GCN을 통한 정밀화:이후, GCN 기반 예측기를 통해 국부 정밀화를 수행하며, 파라미터 \( \{ \beta, \theta \} \in \mathbb{R}^{58} \)와 약한 원근 카메라 파라미터 \( \{ s, t \} \in \mathbb{R}^{3} \)를 추정합니다. 이를 통해 손 구조의 합리성을 개선하고, 후속 정밀화에 필요한 사전 정보를 제공합니다.
3.4.1. Coarse estimation from hand model
이 단계에서는 MANO 손 모델을 사용하여 초기 손 자세를 예측합니다. 이를 위해 전역적인 이미지 특징을 활용하여 MANO의 파라미터를 회귀합니다. 이러한 회귀에는 세 가지 주요 구성 요소가 있습니다:
1. Joint Feature Enhancement (JFE): 여러 GCN 연산자를 통해 관절 단위 특징을 강화합니다.
2. MANO Head
3. MANO Decoder
GCN 연산은 다음과 같이 표현됩니다:
\[
F_J = \mathcal{G}(\phi(F_I)), \quad \phi: F_I \in \mathbb{R}^{B \times C \times H \times W} \rightarrow F_J \in \mathbb{R}^{B \times D \times H \ast W}
\]
여기서:
- \( F_I \)는 이미지 특징,
- \( \phi \)는 전이 함수로, 이미지 특징을 관절 특징으로 변환합니다.
- \( B \)는 배치 크기,
- \( D \)는 관절 수,
- \( C \)는 채널 수,
- \( H \times W \)는 공간 해상도를 나타냅니다.
관절 단위 특징을 추출한 후, MLP(Multi-layer Perceptron)를 통해 \( \{ \beta, \theta \} \in \mathbb{R}^{58} \)와 약한 원근 카메라 파라미터 \( \{ s, t \} \in \mathbb{R}^{3} \)를 회귀하여 초기 손 자세를 예측합니다. 이 초기화는 후속 정밀화를 위한 사전 정보를 제공합니다.
3.4.2. FSR-guided pixel-aligned feature retrieval
초기 예측을 생성한 후, 기존 방법들은 주로 전역 정보에만 의존하여 자세 정렬 특징 샘플링(pose-aligned feature sampling)을 수행하지만, 이는 픽셀 단위의 인식을 고려하지 못합니다. 이를 해결하기 위해, 우리는 FPFR(FSR-guided pixel-aligned feature retrieval) 모듈을 설계하여 FSR(Flexible Separable Representation)을 사용해 픽셀 단위에서 동적 보정을 수행합니다.
FPFR 모듈은 다음과 같이 원래의 추출된 특징 \( F \)를 보정합니다:
\[
F =
\begin{cases}
\Gamma(F), & \Pi(F) < 0 \\
F, & \text{otherwise}
\end{cases}
\]
여기서 \( \Pi(F) < 0 \)는 추정된 자세가 손 경계를 벗어났음을 나타내고, \( \Gamma(F) \)는 손 경계와 가장 가까운 점을 찾아 동적으로 보정하는 함수입니다. FSR은 픽셀 단위의 표현이므로, FPFR은 단순한 로컬 검색을 통해 픽셀 수준의 정밀한 보정을 수행할 수 있습니다.
3.4.3. Local refinement
초기 예측 이후, 모델은 국부 정밀화를 통해 더 나은 성능을 달성합니다. 이를 위해 두 가지 주요 모듈을 사용합니다:
- PRBL (Pose Refinement by Bone Length): 손의 뼈 길이를 기반으로 자세를 정밀하게 조정합니다.
- PRBG (Pose Refinement by GCN): GCN을 사용하여 관절 간의 장거리 종속성을 모델링하고 정밀한 자세를 예측합니다.
GCN 연산은 다음과 같이 정의됩니다:
\[
F' = \mathcal{G}(F) = \sigma(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} F W)
\]
여기서 \( F \)는 입력 노드 특징, \( W \)는 학습 가능한 가중치 행렬, \( \tilde{A} \)는 그래프의 인접 행렬, \( \tilde{D} \)는 차수 행렬, \( \sigma \)는 활성화 함수입니다. 이 과정을 통해 손의 세밀한 자세와 메쉬를 더욱 정교하게 복원합니다.

3.5 Loss Functions
제안된 방법은 손 자세와 메쉬 복원을 위한 여러 손실 함수들을 결합하여 사용합니다.
- Auxiliary Loss: 보조 작업 학습을 위한 MSE (Mean Squared Error) 손실을 사용하여 FSR(Flexible Separable Representation)을 복원합니다:
\[
L_{\text{FSR}} = (Y_{\text{FSR}} - \hat{Y}_{\text{FSR}})^2
\]
여기서 \( Y_{\text{FSR}} \)는 실제값이고, \( \hat{Y}_{\text{FSR}} \)는 예측값입니다. - Target Loss: 자세 및 메쉬 예측을 위한 손실로는 L1 손실을 사용하여 실제값과 예측값 사이의 차이를 최소화합니다:
\[
L_{\text{mesh}} = \|Y_m - \hat{Y}_m\|_1
\]
\[
L_{\text{pose}} = \|Y_p - \hat{Y}_p\|_1
\] - MANO Parameters Loss: 손의 모양 \( \beta \)와 자세 \( \theta \)를 예측하기 위한 L1 손실도 사용됩니다:
\[
L_{\beta} = \|\beta - \hat{\beta}\|_1
\] - Mesh Smoothness Loss: 메쉬의 부드러움을 유지하기 위해 normal 손실과 edge 손실을 추가로 사용합니다:
\[L_{\text{norm}} = \sum_{\mathcal{C}} \sum_{(i,j) \subset \mathcal{C}} \left| \|Y_i^m - Y_j^m\|_2 - \|\hat{Y}_i^m - \hat{Y}_j^m\|_2 \right|\]
\[L_{\text{edge}} = \sum_{\mathcal{C}} \sum_{(i,j) \subset \mathcal{C}} \left| \|Y_i^m - Y_j^m\|_2 - \|\hat{Y}_i^m - \hat{Y}_j^m\|_2 \right|\] - Total Loss: 전체 손실은 여러 항목들의 가중합으로 표현됩니다:
\[L_{\text{total}} = \lambda_1 L_{\text{FSR}} + L_{\text{mesh}} + L_{\text{pose}} + \lambda_2 L_{\beta} + \lambda_3 L_{\text{norm}} + L_{\text{edge}}\]
여기서 \( \lambda_1, \lambda_2, \lambda_3 \)는 서로 다른 손실 항목들 간의 가중치를 조정하는 계수입니다.
3.6. Weakly-supervised mesh reconstruction
대부분의 연구는 손 메쉬 복원을 완전 지도 학습(fully-supervised learning)방식으로 수행합니다. 하지만 현실적인 환경에서 손 메쉬에 대한 정확한 주석을 생성하는 것은 매우 어렵습니다. 본 연구에서는 손 자세 주석만을 사용하여 약지도 학습(weakly-supervised learning)방식으로 손 메쉬 복원을 확장합니다.
먼저, MANO 모델을 사용하여 손 메쉬의 초기값을 생성하고, 이를 후속 예측 과정에서 Pseudo label로 활용하여 손의 해부학적 구조에 대한 사전 지식을 제공합니다.
이를 위해 파라메트릭(global modeling)과 비파라메트릭(local refinement) 부분의 예측 간의 일관성 손실(mesh consistency loss)을 추가합니다. 다음과 같은 손실 함수를 사용합니다:
\[
L_{\text{Consist}}^{\text{norm}} \quad \text{및} \quad L_{\text{Consist}}^{\text{edge}}
\]
또한, 예측된 MANO 자세 파라미터 \( \theta \)와 모양 파라미터 \( \beta \)에 대한 사전 규제 손실(prior regularization loss)을 적용합니다:
\[
L_{\text{prior}} = \|\theta\|_1 + \|\beta\|_1
\]
따라서 약지도 학습을 위한 총 손실 함수는 다음과 같이 정의됩니다:
\[
L_{\text{total}} = \lambda_1 L_{\text{FSR}} + \lambda_2 L_{\text{Consist}}^{\text{norm}} + \lambda_3 L_{\text{Consist}}^{\text{edge}} + L_{\text{pose}} + \lambda_4 L_{\text{prior}}
\]
여기서 \( \lambda_1 \) 및 \( \lambda_4 \)는 0.1로 설정되고, \( \lambda_2 \)와 \( \lambda_3 \)는 0.01로 설정됩니다.
4. Experimental results
4.1. Datasets and metrics
이 논문에서는 제안한 방법을 평가하기 위해 FreiHAND와 HO3D라는 두 개의 주요 데이터셋을 사용합니다.
- FreiHAND:
- 이 데이터셋에는 30,240개의 훈련 이미지와 3,960개의 평가 이미지가 포함되어 있습니다. 각 이미지는 224×224 해상도를 가지며, 녹색 화면과 함께 캡처된 후 세 가지 유형의 합성 배경으로 증강됩니다.
- 이 데이터셋은 3D 자세와 3D 메쉬 좌표로 주석이 달려 있습니다.
- FreiHAND 데이터셋은 훈련과 평가 환경이 달라 어려운 문제를 제시합니다. 평가 세트는 실제 시나리오에서 캡처되며, 손-물체 상호작용에 의한 가림 현상이 발생하여 자세 추정의 난이도가 증가합니다.
- HO3D:
- 66,034개의 훈련 이미지와 11,524개의 테스트 이미지를 포함하며, 해상도는 640×480입니다.
- 10명의 사용자가 10개의 다른 물체 중 하나를 쥐고 있는 68개의 시퀀스로 이루어져 있습니다.
- 이 데이터셋의 물체들은 FreiHAND에 비해 크기가 커서 손 가림이 더 많이 발생하며, 훈련과 테스트 세트 간에 사용된 물체가 다르기 때문에 예측의 난이도를 증가시킵니다.
평가 지표:
- PA-MPJPE/MPVPE: Procrustes 분석을 사용하여 관절/버텍스 간의 유클리드 거리를 측정하여 예측과 수동 주석 사이의 오차를 계산합니다.
- F-score: 두 메쉬 간의 주어진 오차 임계값에서 recall과 precision의 조화 평균을 계산하며, F@5 mm 및 F@15 mm를 사용합니다.
- AUC: PCK (percentage of correct keypoints)와 오차 임계값의 곡선 아래 면적을 측정합니다.
- Param 및 FPS: 모델의 매개변수 수와 초당 프레임(FPS) 속도를 평가합니다.
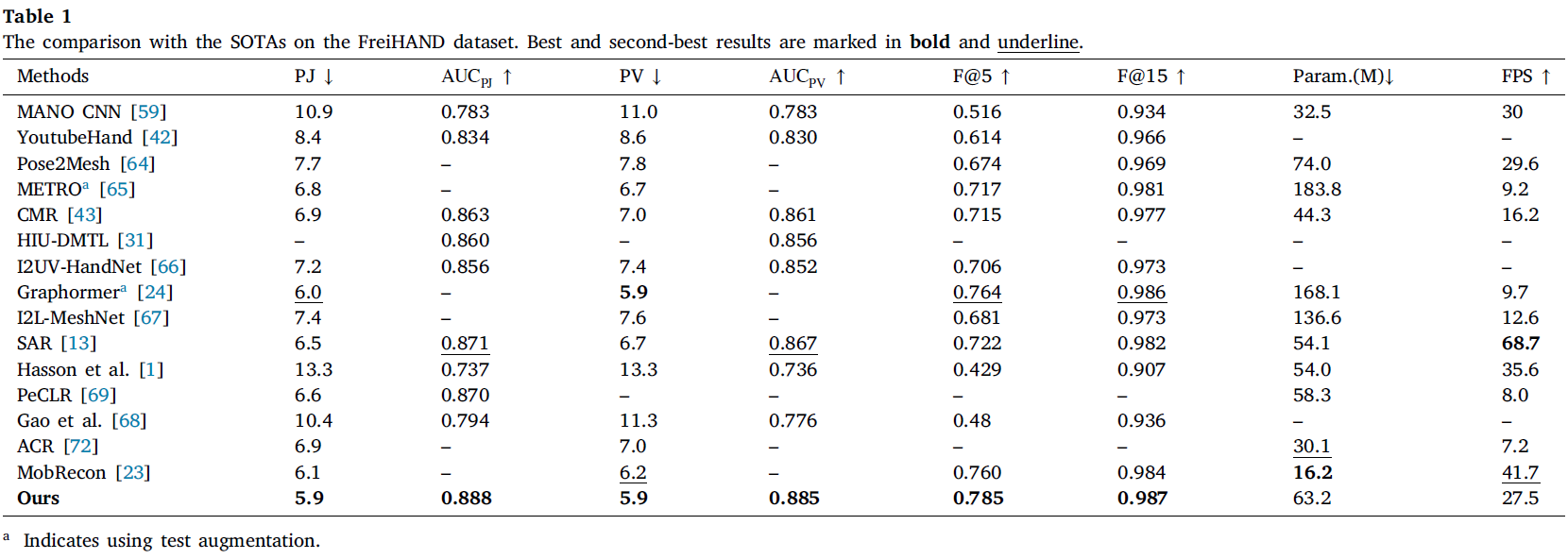
4.2. Implementation details
- 프레임워크 및 하드웨어:
- 전체 프레임워크는 PyTorch를 사용해 구현되었습니다.
- 모델은 NVIDIA GTX 3090Ti GPU에서 학습 및 테스트되었습니다.
- 최적화 기법:
- 최적화 알고리즘으로 AdamW를 사용하였습니다.
- 학습 설정:
- 학습 에폭: 50
- 배치 크기: 64
- 초기 학습률: 3e−4 (학습률 조정은 코사인 감쇠 스케줄(cosine decay schedule)을 사용)
- 입력 해상도:
- 입력 이미지의 해상도는 256 × 256으로 설정되었습니다.
- 데이터 전처리:
- FreiHAND 데이터셋: 이미지의 중심에서 손을 잘라서 사용합니다.
- HO3D 데이터셋: 학습 시 2D 키포인트를 사용하여 손 영역을 자르고, 테스트 시에는 제공된 2D 바운딩 박스를 사용해 손을 잘라냅니다.
이 구현 세부 사항은 모델의 학습 및 테스트에 사용된 환경과 설정을 구체적으로 설명합니다.
4.3. Comparisons with the SOTAs
이 장에서는 두 개의 3D 손 자세 추정 데이터셋인 FreiHAND와 HO3D에서 최신 기법들과 제안된 방법의 성능을 비교했습니다. 비교 대상에는 MANO CNN, YoutubeHand, Pose2Mesh, METRO, CMR, HIU-DMTL 등 다양한 기법이 포함되었습니다.
- FreiHAND 데이터셋에서, 제안된 방법은 모든 평가 지표에서 대부분의 기존 연구들보다 우수한 성능을 보였습니다. 특히, Graphormer와 비교했을 때 F@5와 F@15 점수에서 더 높은 성능을 기록했습니다. 제안된 방식은 전역 사전 정보와 국부적 픽셀 정렬을 통해 더 나은 성능을 달성했습니다.
- HO3D 데이터셋에서도 제안된 방법은 SOTA 기법들과 비교하여 뛰어난 성능을 보였으며, 전역 정보와 국부 정보의 결합이 성능 향상에 기여했습니다.
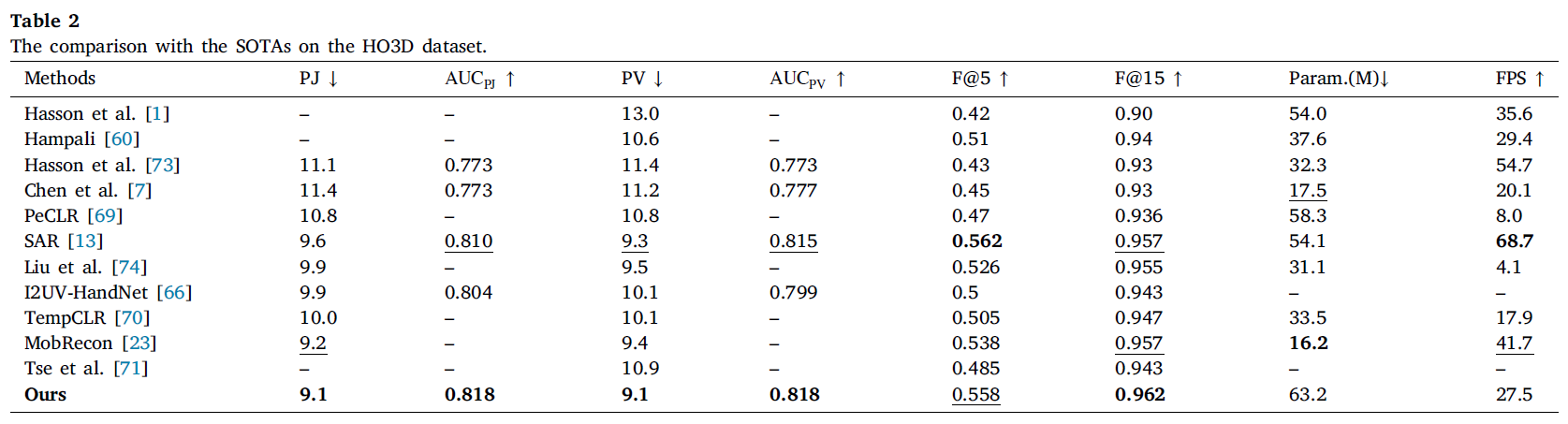

SAR 방법은 coarse-to-fine 구조를 사용하여 손 자세를 복원했지만, 제안된 방법은 추가적으로 coarse estimation을 통해 시각적 특징을 향상시켜, 성능이 더 우수했습니다.
4.4. Ablation study
Ablation 연구는 제안된 프레임워크의 각 모듈의 효율성을 평가하는 데 초점을 맞추고 있습니다. 모든 실험은 FreiHAND 데이터셋에서 수행되었습니다.
- MANO 회귀기 성능 평가:
- 먼저, JFE(Joint Feature Enhancement) 모듈의 역할을 평가하였습니다. 이미지 특징을 MANO 파라미터로 직접 투영하는 것은 매우 비선형적 문제입니다.
- JFE 모듈을 결합함으로써 메쉬 예측 오류가 약 37% 감소하고, F@15 점수는 6.3% 향상되었습니다. 이는 손 그래프의 구성으로 인해 성능이 개선되었음을 나타냅니다.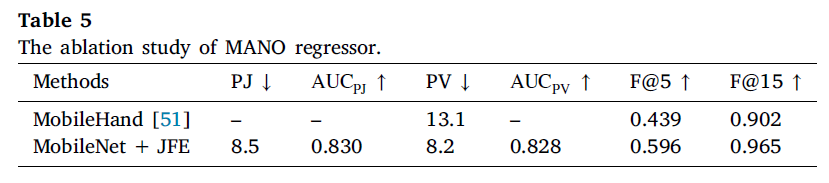
- 모듈별 성능 비교:
- 5개의 서로 다른 모듈을 대상으로 자체 비교 실험을 수행하였으며, 이는 Table 6에 나와 있습니다.
- 기본 모델로는 ResNet50과 MANO 회귀기를 사용하였습니다.
- ATP(Auxiliary Task Pretraining)를 결합했을 때, 자세 및 메쉬 오류는 각각 6.8mm 및 6.9mm로 감소하였습니다.
- PRBL 및 PRBG 모듈을 추가하면 자세 및 메쉬 오류는 각각 8% 감소하였습니다.
- 마지막으로, FPFR(FSR-guided Pixel-Aligned Feature Retrieval)을 추가하여 자세 및 메쉬 오류가 6.1mm에서 5.9mm로 감소하였습니다. 이는 픽셀 수준의 인식이 전역 사전 정보의 효율성을 크게 향상시키는 것을 보여줍니다.
총괄적으로, 각 모듈은 성능 개선에 중요한 역할을 하며, 특히 FPFR 모듈이 세밀한 픽셀 단위의 인식을 통해 글로벌 정보의 활용도를 높였습니다.

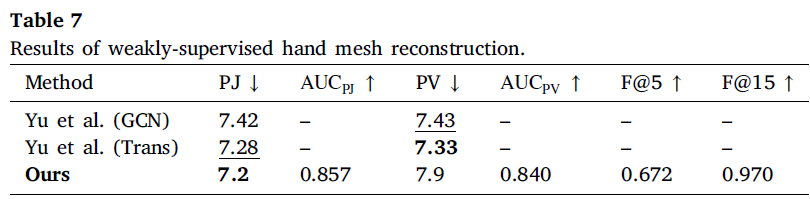
4.5. Weakly-supervised mesh estimation
이 장에서는 FreiHAND 데이터셋에서 약지도 학습(weakly-supervised learning)을 통해 제안된 방법의 일반화 성능을 평가하였습니다. VAE 기반 방법과 비교한 결과:
- 우리의 방법은 관절 재구성(joint reconstruction)에서 더 나은 성능을 보였으나, VAE 기반 방법은 손 자세와 메쉬 재구성 간의 일관성을 더 잘 유지했습니다.
- VAE 기반 방법은 MANO 모델을 사용하여 손 메쉬를 직접 생성하는 반면, 제안된 방법은 MANO 출력을 pseudo label로 사용하여 최종 손 메쉬를 지도하고, 비파라메트릭 모델을 통해 국부적인 정밀화를 목표로 합니다.
- 약지도 학습 환경에서는 메쉬와 자세 예측 간의 성능 격차가 존재합니다.
- 그림 8에서는 제안된 방법을 완전 지도 학습과 약지도 학습 방식에서 시각적으로 비교하였고, 제안된 프레임워크는 약지도 학습에서도 비교적 정확한 자세를 재현하지만, 국부적인 회전 및 이동에서 성능이 저하되는 모습을 보였습니다.
5. Conclusion
이 논문에서는 매개변수적 방법과 비매개변수적 방법의 장점을 결합하여 정확하고 강력한 손 자세 복원 기법을 제안하였습니다. 제안된 방법은 전역 모델링과 국부 정밀화로 손 자세 복원을 분리하며, coarse-to-fine 구조에서 이를 수행하였습니다.
- 제안된 픽셀 정렬 특징 추출 모듈(pixel-aligned feature retrieval module)은 전역 사전 정보와 국부 공간 인식을 시각적 특징 공간에서 더 효과적으로 통합하여 현재의 SOTA 방법들과 비교했을 때 우수한 성능을 보였습니다.
- 약지도 학습(weakly-supervised mesh reconstruction)에서도 제안된 방법의 일반화 성능이 입증되었습니다.
- 정량적 및 정성적 결과 모두에서, 완전 지도 학습과 약지도 학습 실험이 제안된 방법의 효과성과 강건성을 보여주었습니다.
이 방법은 픽셀 수준의 정렬과 메쉬 주석이 부족한 상황에서도 유망한 성능을 나타냅니다.
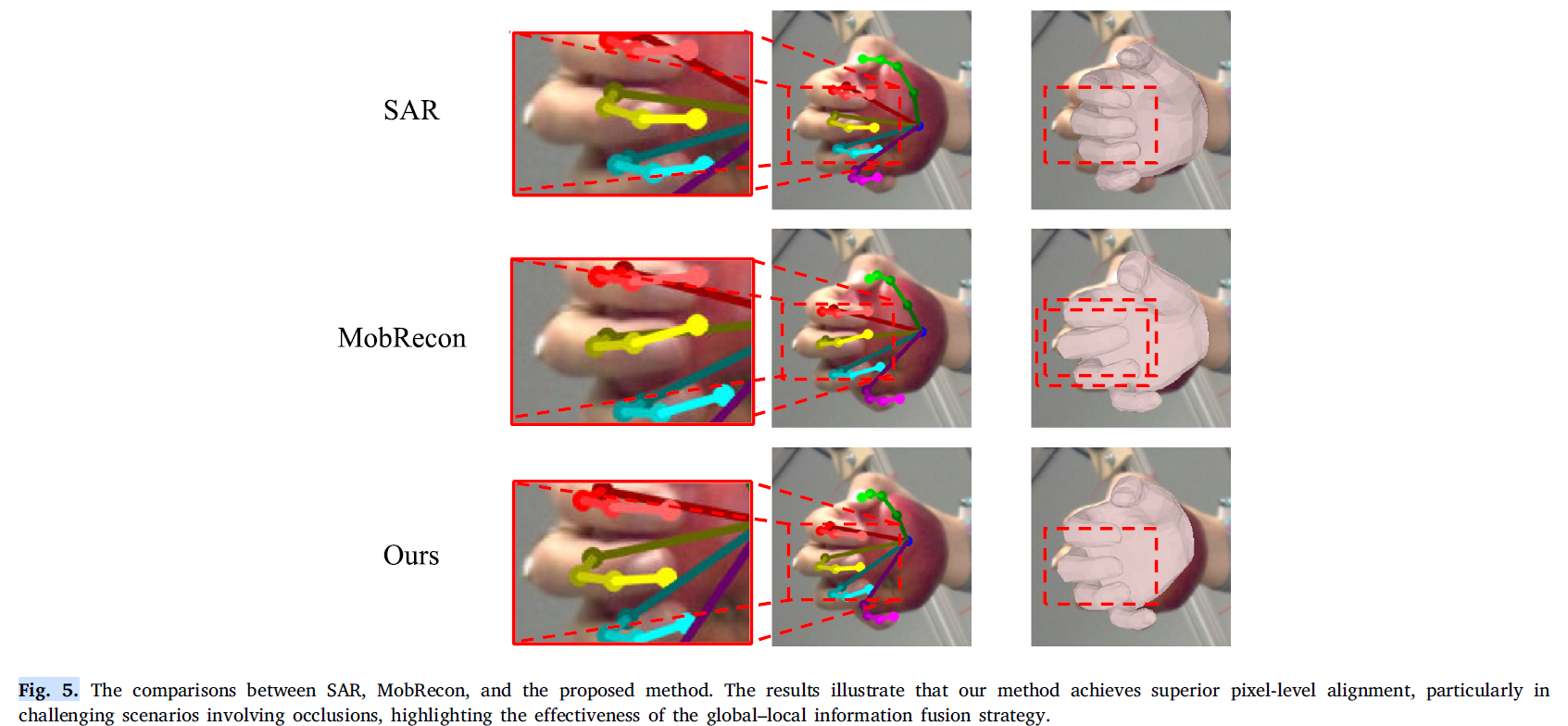
Figure 2 설명
1. 보조 작업 사전학습 (Auxiliary Task Pretraining):
- 먼저 FSR (Flexible Separable Representation) 모듈을 사용하여 다중 해상도 시각적 특징 \( V_i \)와 보조 특징 \( A_i \)를 생성합니다.
- 이 보조 작업은 손의 경계에 따른 픽셀 수준의 상관성을 나타내며, 이후 손 복원 작업의 해 공간을 줄이는 데 도움을 줍니다.
2. 전역 모델링 (Global Modeling):
- 전역 특징을 활용하여 초기 손 자세 \( P_J^I \)와 메쉬 \( P_V^I \)를 예측합니다.
- 전역 정보는 손의 구조에 대한 사전 지식을 제공하며, 전반적인 복원의 정확도를 높입니다.
3. 국부 정밀화 (Local Refinement):
- 이후 FSR 가이드를 통해 FPFR (Pixel-Aligned Feature Retrieval) 모듈을 사용하여 픽셀 수준에서 정밀한 특징을 추출합니다.
- 추출된 특징을 기반으로, PRBL 및 PRBG 모듈을 통해 손 메쉬와 자세를 더욱 세밀하게 정교화합니다.
- PRBL은 손 관절의 국부적 정보를 추출하고, PRBG는 관절 간의 관계를 모델링하여 복원의 품질을 높입니다.
이 과정은 coarse-to-fine 방식으로 전역적인 초기 예측을 수행한 후, 국부적인 픽셀 정렬을 통해 세밀한 복원 작업을 수행하는 것을 시각적으로 설명합니다.