* 본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
Abstract
이 논문은 다중 뷰에서 3D 인간 자세를 추정하는 문제를 다룹니다. 특히, 시야가 제한되거나 가려진 경우의 문제를 해결하기 위해 새로운 인코더-디코더 트랜스포머 아키텍처를 제안합니다. 인코더는 여러 시점에서 감지된 2D 관절을 다루며, 기하학적 관계를 활용한 주의 메커니즘을 적용하여 뷰 간의 정보를 통합합니다. 디코더는 이를 기반으로 3D 자세를 예측합니다. 다양한 데이터셋에서 실험한 결과, 이 방식이 가려진 장면이나 카메라가 적은 경우에도 기존 방법보다 뛰어난 성능을 보였습니다.
I. INTRODUCTION
3D 인간 포즈 추정은 스포츠 분석, 로봇 공학, 가상 현실 및 캐릭터 애니메이션 등 여러 분야에서 중요한 문제로, 인간의 움직임과 상호작용을 이해하는 데 필수적입니다. 최근 단안 이미지나 비디오를 통한 추정 방법이 발전했지만, 깊이 모호성과 가려짐 문제로 인해 단일 시점에서의 3D 포즈 추정은 여전히 도전적입니다.
이러한 한계를 극복하기 위해 다중 카메라 시점에서 3D 포즈를 추정하는 방법이 사용되며, 일반적으로 2D 포즈를 추정한 후 삼각측량을 통해 3D 포즈를 재구성합니다. 그러나 대부분의 공개 데이터셋은 중앙 캡처 영역에서 가려짐이 없는 상황을 기반으로 하며, 실제 환경에서는 여러 제약으로 인해 가려짐과 넓은 기준선 설정이 발생할 수 있습니다.
본 연구에서는 다중 뷰에서 단일 인물의 3D 포즈를 회귀 문제로 접근하고, 새로운 인코더-디코더 Transformer 아키텍처를 제안합니다. 이 모델은 2D 관절을 개별 토큰으로 처리하고, 글로벌 자기 어텐션을 통해 다중 뷰와 시간 정보를 융합합니다. 기하학적 관계를 활용하는 어텐션 메커니즘과 2D 포즈 감지기의 신뢰 점수를 사용하여 인코더의 어텐션을 개선합니다.
주요 기여는 다음과 같습니다:
- 다중 뷰 단일 인물 3D 포즈 재구성을 위한 새로운 방법 제안.
- 신뢰도와 기하학적 편향을 통한 어텐션 메커니즘 개선.
- 일반화 능력을 높이기 위한 장면 중심화, 합성 뷰 및 토큰 드롭아웃 기법 제안.
- 가려짐 장면과 겹치는 뷰가 적은 상황에서 성능 향상 입증.
논문은 이전 연구 논의, 제안된 방법의 세부사항, 실험 결과 및 향후 연구 방향을 포함하여 구성되어 있습니다.
이 논문의 주요 기여는 다음과 같습니다:
- 다중 시점과 시간 정보를 융합하는 새로운 트랜스포머 기반 3D 자세 재구성 방법 제안.
- 신뢰도와 기하학적 정보를 활용하여 인코더의 주의 메커니즘을 개선.
- 장면 중심화, 합성 뷰, 토큰 드롭아웃을 도입하여 모델의 일반화 성능 강화.
- 다양한 실험을 통해 제안한 방법이 기존 방법보다 우수한 성능을 보임을 입증.
2. RELATED WORK
3D 인간 포즈 추정
- 많은 3D 인간 포즈 추정 연구는 단안 이미지나 비디오에 초점을 맞추지만, 깊이 모호성과 가려짐 문제로 어려움이 있다.
- 여러 뷰에서 3D 포즈를 추정하는 방법이 자연스러운 해결책으로, 두 단계로 이루어진다: 1) 각 뷰에서 2D 키포인트 독립 추출, 2) 삼각측량을 통해 3D 포즈 재구성.
- 재구성의 정확도는 키포인트 품질에 의존하며, 최근 연구들은 뷰 간 정보를 융합하여 2D 포즈 검출을 정제하는 데 주력한다.
- Qiu et al.은 고정된 어텐션 매트릭스를 사용하여 2D 뷰에서 3D 포즈를 검색하였지만, 카메라 구성이 변경되면 재훈련이 필요하다.
- Iskakov et al.은 2D 감지기와 미분 가능한 삼각측량을 통해 다중 뷰 3D 재구성 문제를 해결하였다.
- AdaFuse는 적응형 융합 가중치를 학습하여 가려짐 문제를 해결하였으나, 에피폴라 라인 밖의 정보를 무시하고 각 관절을 독립적으로 처리한다.
Transformers를 이용한 3D 포즈 추정
- Transformer는 다양한 분야에서 강력한 아키텍처로 입증되었다.
- 여러 연구자들이 Transformer를 2D 인간 포즈 추정에 적용하였다.
- Metro는 단안 이미지에서 3D 포즈와 메쉬를 직접 회귀하고, MixSTE는 비디오에서 공간적 및 시간적 어텐션을 번갈아 사용하여 3D 포즈를 추정한다.
- 최근에는 다중 뷰 3D 포즈 추정에 Transformer가 활용되고 있다.
- He et al.은 에피폴라 Transformer를 제안하여 이웃 뷰의 특징을 활용하고, TransFusion은 전역 어텐션을 통해 뷰 간 융합을 수행한다.
- Ma et al.은 키포인트 쿼리의 어텐션 점수를 기반으로 시각적 토큰을 잘라내는 방법을 제안하였다.
- 본 연구에서는 2D 관절 좌표와 관련된 신뢰 점수를 입력으로 사용하는 인코더-디코더 Transformer 모델을 제시한다.
3. METHOD
a. overview
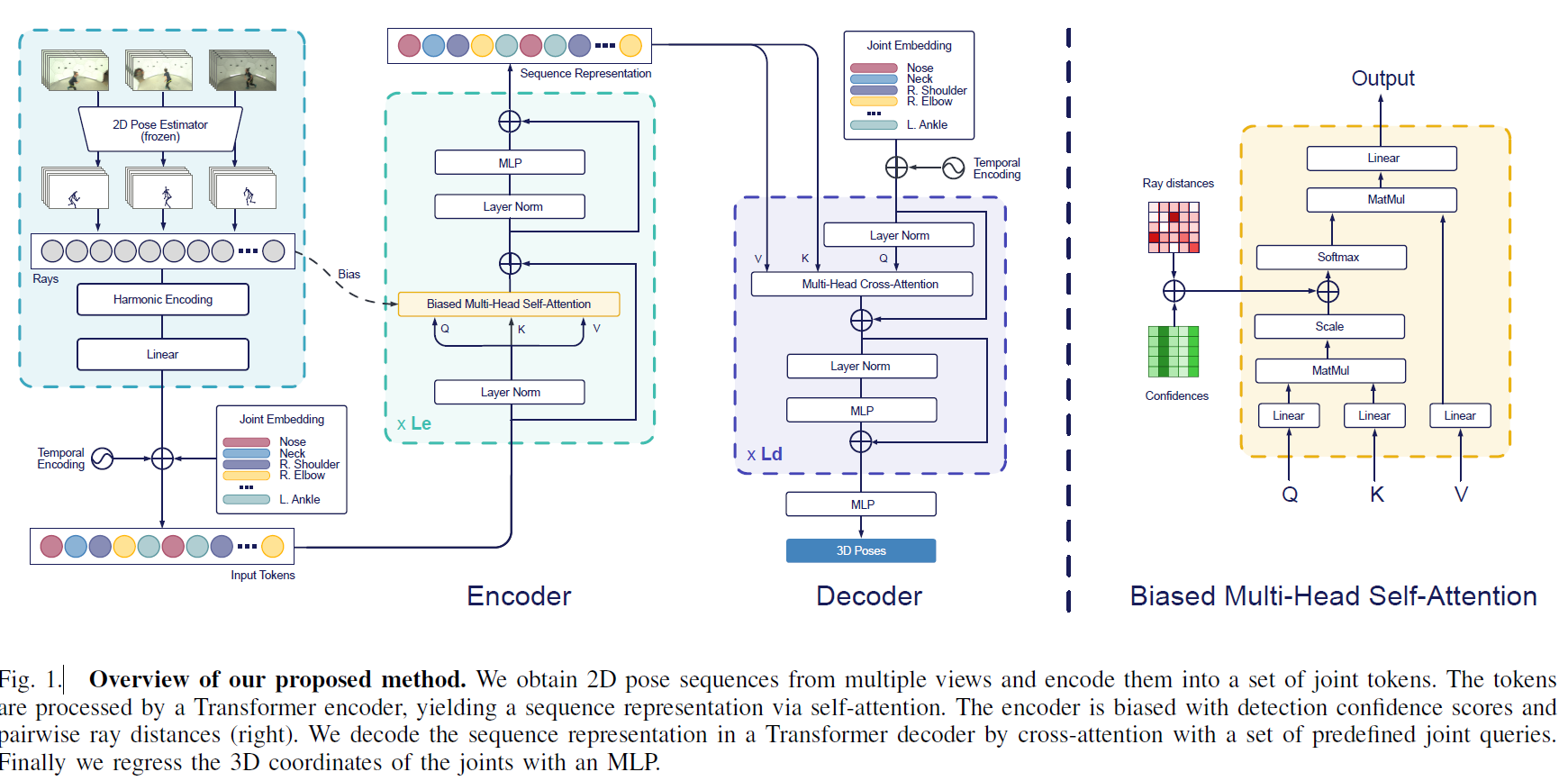
그림 1은 제안된 다중 뷰 3D 인간 포즈 재구성 방법의 개요를 제공합니다. 우리는 상용 2D 인간 포즈 감지기를 사용하여 다양한 시점에서 장면을 캡처한 다중 뷰 이미지 시퀀스에서 2D 골격을 추출합니다. 이 포즈를 개별 관절 집합으로 평탄화한 후, 각 2D 관절 감지 및 해당 카메라 중심을 통과하는 3D ray로 변환합니다. ray는 독립적으로 고차원 특징으로 투영되며, 이 특징 벡터 집합은 Transformer 인코더에서 자기 어텐션을 통해 정제되어 전체 시퀀스에 대한 전역 집합 잠재 표현을 생성합니다. 우리는 기하학 및 감지 점수에 대한 사전 지식을 사용하여 인코더의 어텐션 레이어를 안내합니다. 마지막으로, Transformer 디코더를 통해 시퀀스 인코딩을 디코딩할 포인트의 의미를 설명하는 목표 특징 벡터 집합으로 쿼리하여 3D 포즈를 예측합니다.
b. Ray Encoding
우리 모델은 다중 뷰 시퀀스의 2D 포즈와 관련된 신뢰 점수 \( S \in \mathbb{R}^{T_{in} \times C \times J \times 3} \)를 입력으로 받습니다. 여기서 \( C \)는 카메라 수, \( T_{in} \)은 시간 프레임 수, \( J \)는 감지된 포즈의 키포인트 수입니다. 또한 외적 카메라 매트릭스 \(\{ E_c = [R_c | t_c] \in SE(3) \}_{c=1}^{C}\)와 내적 파라미터 \(\{ K_c \in \mathbb{R}^{3 \times 3} \}_{c=1}^{C}\)를 사용합니다.
우리는 시퀀스를 개별 관절 집합으로 평탄화한 후, 카메라 매트릭스를 사용하여 추정된 2D 관절과 해당 카메라 중심을 통과하는 3D ray로 변환합니다. 완벽한 카메라 보정과 완벽한 감지가 이루어진 경우, 이러한 ray는 해당하는 3D 관절도 통과합니다. 우리는 ray에 대해 Plücker 표현을 사용합니다. 이 표현은 ray 좌표를 카메라 중심의 위치와 분리하여 새로운 카메라 구성에 대한 일반화를 촉진합니다.
특히, 카메라 \( c \)에서 픽셀 좌표 \((u, v)\)를 가진 관절 \( j \)에 대해 ray의 Plücker 좌표 \( r_{j,c} \in \mathbb{R}^6 \)를 다음과 같이 계산합니다:
\[r_{j,c} = (d_{j,c}, m_{j,c}) = \left( \tilde{d}_{j,c}, t_c \times \tilde{d}_{j,c} \right) / \|\tilde{d}_{j,c}\|, \]
여기서 \(\tilde{d}_{j,c}\)는 ray 방향입니다:
\[\tilde{d}_{j,c} = R_c^{-1} K_c^{-1} \begin{pmatrix} u \\ v \\ 1 \end{pmatrix}.\]
마지막으로, ray 임베딩은 다음과 같이 형성됩니다:
\[f_{j,c} = W_r(h(r_{j,c})),\]
여기서 \( h(\cdot) \)는 조화 임베딩을 나타내며, \( W_r \)는 선형 프로젝션 레이어입니다.
C. Biased Transformer Encoder
우리는 ray 임베딩을 처리하기 위해 Le 레이어로 구성된 Transformer 인코더를 사용합니다. 이 인코더는 전역 다중 헤드 자기 어텐션(global multi-head self-attention)을 포함하여, 몸 관절 간의 관계를 동시에 모델링하고, 다양한 뷰와 시간 차원에 걸쳐 전역 문맥을 각 토큰에 제공합니다. Transformer는 순열 불변성이 있기 때문에, 토큰에 학습된 몸 관절 임베딩과 현재 시간 단계의 관찰 상대 타임스탬프를 기반으로 한 조화적 시간 인코딩을 추가하여 시간적 및 신체 구조 정보를 유지합니다.
Transformer 아키텍처의 핵심에서, 어텐션 메커니즘은 특정 쿼리에 대한 관련성에 따라 토큰 집합의 가중 합을 계산합니다. 특히, 스케일된 점곱 어텐션은 각 키 \( K \)에 대한 쿼리 \( Q \)의 관련성 점수를 계산합니다:
\[
\text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) V,
\]
여기서 \( Q, K, V \)는 입력 토큰의 프로젝션이며 \( d_k \)는 특징 벡터의 차원입니다.
우리 문제는 알려진 구조를 가지고 있으며, 이를 통해 자기 어텐션 중에 Transformer를 안내할 수 있습니다. 먼저, 포즈 감지기는 예측된 좌표의 신뢰성을 나타내는 신뢰 점수(confidence scores)를 제공합니다. 직관적으로, 어텐션 행렬을 계산할 때 높은 신뢰 점수를 가진 관절에 해당하는 토큰에 더 많은 가중치를 부여해야 합니다. 관절 신뢰성에 대한 지식을 포함하기 위해, 우리는 신뢰 점수 행렬 \( M_{conf} \)를 추가하여 어텐션 행렬을 편향합니다. 이 행렬은 키의 감지 신뢰성 점수의 행 벡터를 \( q \)번 행으로 반복하여 얻습니다. 각 쿼리에 대해, 이는 높은 신뢰 점수를 가진 관절에 해당하는 키의 어텐션 점수를 증가시킵니다.
우리는 또한 특정 토큰이 서로 다른 카메라에서 관찰된 동일한 몸 관절에 해당하는 토큰과 동일한 시점에서 관찰된 다른 몸 관절에 해당하는 토큰에 더 많은 주목을 해야 한다고 가정합니다. 이는 3D 공간에서 가까운 ray를 의미합니다. [35]와 유사하게, 우리는 ray 간의 쌍 거리 행렬 \( M_{dist} \)를 형성하고 이를 어텐션 맵에 대한 기하학적 편향으로 사용합니다. 두 개의 ray \( r_q = (d_q, m_q) \), \( r_k = (d_k, m_k) \)가 단위 방향 \( d_q \)와 \( d_k \)를 가질 때, 이들의 거리는 다음과 같이 정의됩니다:
\[
d(r_q, r_k) =
\begin{cases}
\frac{|d_q \cdot m_k + d_k \cdot m_q|}{\|d_q \times d_k\|}, & d_q \times d_k \neq 0 \\
\|d_q \times (m_q - m_k)\|, & \text{otherwise}.
\end{cases}
\]
우리는 거리 행렬에 각 인코더 레이어에 대해 독립적으로 학습된 음수 계수를 곱합니다. 따라서 쿼리 ray에 대해 거리가 큰 ray는 패널티를 부여받고, 동일한 카메라에서 나온 교차 ray는 쌍 거리 0을 가지며 패널티를 부여받지 않습니다. 동일한 시간에 동일 관절의 서로 다른 뷰에 해당하는 ray는 일반적으로 작은 쌍 거리를 가지지만, 이상치는 동일 관절의 다른 관찰에서 더 멀리 떨어져 패널티를 받습니다. 이는 기하학적 편향을 에피폴라 기하학과 관련지으며, 어텐션 점수는 쿼리 관절의 에피폴라 라인에 따라 높은 점수를 받습니다.
따라서 인코더의 각 레이어 \( l \)에서 다음과 같은 편향된 어텐션 맵을 계산합니다:
\[
A_l = \text{softmax} \left( \frac{Q K^T}{\sqrt{d_k}} + \eta_l^2 M_{conf} - \gamma_l^2 M_{dist} \right),
\]
여기서 \( \eta_l \)와 \( \gamma_l \)는 각 레이어에 대해 학습 가능한 파라미터입니다.
D. 3D pose sequence decoding
인코더의 출력은 전체 포즈 시퀀스를 나타내는 특징 벡터 집합입니다. 특정 시간에 대한 특정 관절 정보를 추출하기 위해 미리 정의된 쿼리를 구성하여 디코딩할 포인트의 의미를 제공합니다. 이 쿼리는 각 인간 키포인트에 해당하는 \( J \)개의 학습된 임베딩 벡터로 구성되며, 원하는 시간 범위인 \( T_{out} \)만큼 반복됩니다. 각 포인트의 타이밍을 지정하기 위해 조화적 시간 인코딩을 추가합니다.
3D 포즈 시퀀스는 Transformer 디코더를 사용하여 디코딩되며, 이 디코더는 미리 정의된 쿼리와 함께 여러 레이어의 다중 헤드 크로스 어텐션을 통해 특징 벡터 집합에 주목합니다. 마지막으로, 디코딩된 토큰을 사용하여 관절의 3D 세계 좌표를 회귀하기 위해 다층 퍼셉트론(MLP)을 사용합니다.
쿼리는 입력과 동일한 수의 프레임으로 구성될 필요는 없으며, 훈련과 추론 중에 입력 및 출력 프레임의 수를 다르게 선택할 수 있습니다.
E. Training and Inference
모델은 평균 제곱 오차(Mean Squared Error, MSE)를 최소화하여 훈련됩니다. MSE는 다음과 같이 정의됩니다:
\[
L = \frac{1}{NT_{out}J} \sum_{i=1}^{N} \sum_{t=1}^{T_{out}} \sum_{j=1}^{J} \| P_{itj} - \hat{P}_{itj} \|^2,
\]
여기서 \(N\)은 데이터셋의 포즈 수, \(P_{itj}\)는 실제 3D 관절, \(\hat{P}_{itj}\)는 해당 예측값입니다. 모델은 길이 \(T_{out} = T_{in}\)의 전체 시퀀스를 재구성하도록 훈련됩니다. 추론 중에는 \(T_{in}\) 프레임의 관찰값(즉, 최신 관찰 및 \(T_{in} - 1\)개의 과거 관찰)을 입력하지만, 최신 프레임만 재구성하는 데 관심이 있습니다. 따라서 \(T_{out} = 1\)로 설정되며, 이는 모델이 완전한 인과 예측을 수행하고 실시간 추론에 적합함을 의미합니다.
F. Promoting Generalization
3D 주석이 있는 다중 뷰 포즈 데이터셋은 상대적으로 작고, 일반적으로 고정된 캡처 영역, 적은 카메라 포즈 및 가려짐이 없는 제어된 환경에서 수집됩니다. 본 연구에서는 모델이 보지 않은 장면과 카메라 구성을 처리할 수 있도록 다음과 같은 방법을 도입했습니다.
1. 중심화(Centering): 모델이 임의의 차원을 가진 장면에 일반화할 수 있도록, 훈련 및 추론 중에 장면을 주위 주체를 중심으로 대략적으로 배치합니다. 입력 시퀀스의 길이가 \( T_{in} \)일 때, 시간 \( t \)에서 랜덤한 실제 포즈를 선택하고 목 관절을 바닥에 투영합니다. 이 투영에 랜덤 노이즈를 추가하고, 모든 관찰 레이 및 시퀀스의 실제 포즈를 이 지점을 중심으로 하는 좌표계로 변환합니다. 마지막으로, 수직 축 주위로 임의의 각도로 장면을 회전합니다. 추론 중 첫 번째 시간 단계에서는 3D 레이가 관측값을 삼각측량하여 얻은 지점을 중심으로 하며, 장면을 회전하지 않습니다. 이후 시간 단계에서는 좌표계가 이전 시간 단계에서 예측된 3D 포즈를 중심으로 설정됩니다. 이러한 몸 중심 좌표계로 장면을 변환함으로써, 모델은 보지 않은 차원에 더 잘 일반화할 수 있습니다.
2. 합성 뷰(Synthetic Views): 기존의 다중 뷰 데이터셋은 고정된 제한된 카메라 포즈 구성을 가지고 있어, 학습 기반 포즈 재구성 방법의 일반화 능력을 제한할 수 있습니다. 이 문제를 완화하기 위해 합성 데이터를 사용합니다. 훈련 중, 데이터셋에서 제공되는 관찰과 함께 합성 2D 포즈를 생성하며, 랜덤 카메라 위치를 샘플링하고 이 위치와 실제 3D 포즈의 각 관절을 통과하는 레이를 계산합니다.
3. 토큰 드롭아웃(Token Dropout): 모델이 누락된 데이터에 강인하게 만들기 위해, 훈련 중 입력 토큰의 20%를 랜덤으로 제거합니다. 이로 인해 특정 관절이 시퀀스 전체에서 모든 뷰에서 보이지 않거나, 특정 시간에 전체 신체가 사라질 수 있습니다. 이는 모델이 전체 신체 및 시간 프레임 간의 정보를 집계하도록 유도합니다. 토큰 드롭아웃은 훈련 중 계산 및 메모리 요구 사항을 줄이는 부수적인 효과도 있습니다.
4. EXPERIMENTS
A. Datasets and Evaluation Metrics
Human 3.6M 데이터셋은 11명의 주제가 다양한 활동을 수행하는 360만 개의 이미지로 구성되어 있으며, 각 이미지에는 해당하는 3D 포즈가 포함되어 있습니다. 이미지는 4개의 동기화된 카메라로 50Hz로 캡처되며, 마커 기반 모션 캡처 시스템을 통해 3D 포즈 주석이 생성됩니다. 본 연구에서는 5명의 주제를 훈련에 사용하고, 2명의 주제를 테스트에 사용합니다. 'S9' 주제의 일부 시퀀스는 오류가 있는 3D 주석이 있어 평가에서 무시되었습니다.
H36M-Occl 데이터셋은 occlusion 시나리오를 시뮬레이션하기 위해 2D 관절에 흰색 사각형 마스크를 랜덤으로 배치하여 생성되었습니다. CMU Panoptic 데이터셋은 다양한 활동을 수행하는 여러 장면의 이미지로 구성되어 있으며, 수백 개의 VGA 카메라와 31개의 HD 카메라로 촬영되었습니다. 3D 포즈 주석은 모든 카메라 뷰를 사용하여 삼각측량을 통해 생성됩니다.
Occlusion-Person 데이터셋은 UnrealCV로 렌더링된 합성 데이터셋으로, CMU 모션 캡처 데이터베이스의 모션 시퀀스에 의해 구동되는 13개의 인간 모델이 8개의 카메라로 캡처된 9개의 장면에 배치됩니다.
평가 메트릭으로는 절대 평균 관절 위치 오류(MPJPE)를 사용하여 각 관절의 예측과 실제 값 간의 L2 거리의 평균을 밀리미터 단위로 측정합니다. 3D 포즈는 정렬 없이 평가됩니다.
B. Implementation Details
본 연구에서는 데이터셋과 함께 제공된 카메라 파라미터를 사용하여 이미지를 왜곡 제거하고, 사전 학습된 포즈 감지기를 통해 2D 포즈를 추출했습니다. 특별히 언급되지 않는 한, COCO에서 훈련된 HRNet-W32를 사용하며, YoloX 박스 제안을 활용합니다. 조화 임베딩 h에는 15개의 주파수를 사용하고, 트랜스포머 인코더는 3층, 디코더는 2층으로 구성하며, 두 구성 모두 6개의 헤드를 가지고 있습니다. 훈련 중에는 9개의 시간 프레임과 2개의 무작위 샘플 뷰를 입력하고, 9개의 프레임을 출력합니다. 평가 시에는 9개의 시간 프레임을 입력하고 최신 관측에 해당하는 1개의 프레임만 출력합니다. 모델은 Adam 옵티마이저를 사용하여 256의 미니 배치 크기로 300,000 iterations 동안 훈련되며, 초기 학습률은 \(10^{-4}\) 입니다. 학습은 10,000 스텝의 웜업 후에 점진적으로 감소하며, 단일 Nvidia RTX 4090에서 약 5시간 소요됩니다.
C. Impact of Varying Number of Views
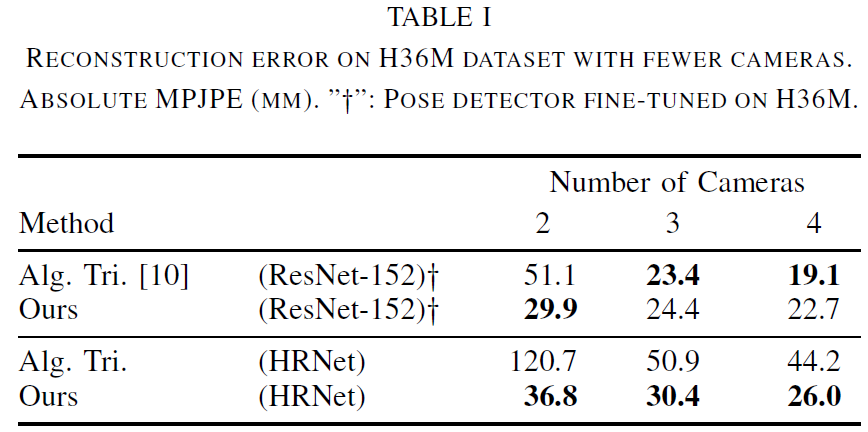
본 연구에서는 H36M 데이터셋에서 카메라 뷰 수가 적을 때의 성능을 측정했습니다. [10]의 대수적 삼각측량 방법과 비교하기 위해 Iskakov et al.의 ResNet-152 감지기를 통해 제공된 2D 포즈로 네트워크를 학습하고 테스트했습니다. 또한 HRNet 포즈에 적용된 대수적 삼각측량 방법과 비교했습니다. 다양한 입력 뷰 수로 모든 방법을 테스트하고 평균 오류를 제시했습니다. 결과는 표 I에 나타나 있으며, 고품질 ResNet-152 포즈를 사용할 때 3개 및 4개 뷰에서 대수적 삼각측량이 우수한 결과를 보였으나, 2개 뷰일 경우 재구성 정확도가 크게 떨어졌습니다. 반면, 본 연구 방법은 2개 뷰만 사용할 때 정확도가 크게 저하되지 않았습니다. 상용 감지기를 통해 추출한 포즈를 사용할 경우, 본 방법은 뷰 수와 관계없이 일관되게 낮은 재구성 오류를 기록했습니다.
D. Occlusion Handling
본 연구에서는 H36M-Occl 테스트 데이터셋에서 occlusion 처리 능력을 평가했습니다. 원래 H36M 훈련 세트로 학습된 모델을 사용하여, ResNet-152 감지기를 적용했을 때, 카메라 수가 충분할 경우 삼각측량이 가장 좋은 결과를 보였습니다. 그러나 카메라 수가 네 대 미만일 경우 본 연구 방법이 상당히 더 나은 결과를 제공합니다. HRNet 포즈 감지기를 사용할 때도, 카메라 수와 관계없이 본 방법이 기준선보다 우수한 성과를 보였습니다.
Occlusion-Person 데이터셋에 대해서는 Adafuse와 본 연구 방법을 비교했습니다. Adafuse의 모든 방법은 삼각측량을 사용하여 3D 관절을 독립적으로 재구성하므로, 최소 두 개의 뷰에서 보이는 관절에 대한 오류만 계산했습니다. 반면, 본 연구 방법은 모든 관절, 즉 어떤 뷰에서도 보이지 않는 관절에 대한 오류도 제시했습니다. 모든 카메라 뷰를 사용할 때 본 방법은 경쟁력 있는 결과를 달성했으며, 카메라 뷰 수가 줄어들수록 가장 작은 재구성 오류를 기록하여 occlusion 처리 능력을 더욱 부각시켰습니다.


E. Generalization Between Datasets
제안한 접근 방식의 일반화 능력을 평가하기 위해 CMU Panoptic 데이터셋에서 모델을 학습하고 H36M에서 테스트했습니다. 표 IV에서 보듯이, 본 연구 방법은 기준선보다 낮은 오류를 나타내어, 본 모델이 보지 않은 카메라 설정 및 위치에 일반화할 수 있는 능력을 입증합니다. 그러나 앉아 있는 시퀀스에서는 정확한 포즈 재구성에 어려움을 겪어, 본 방법의 한계가 드러났습니다.

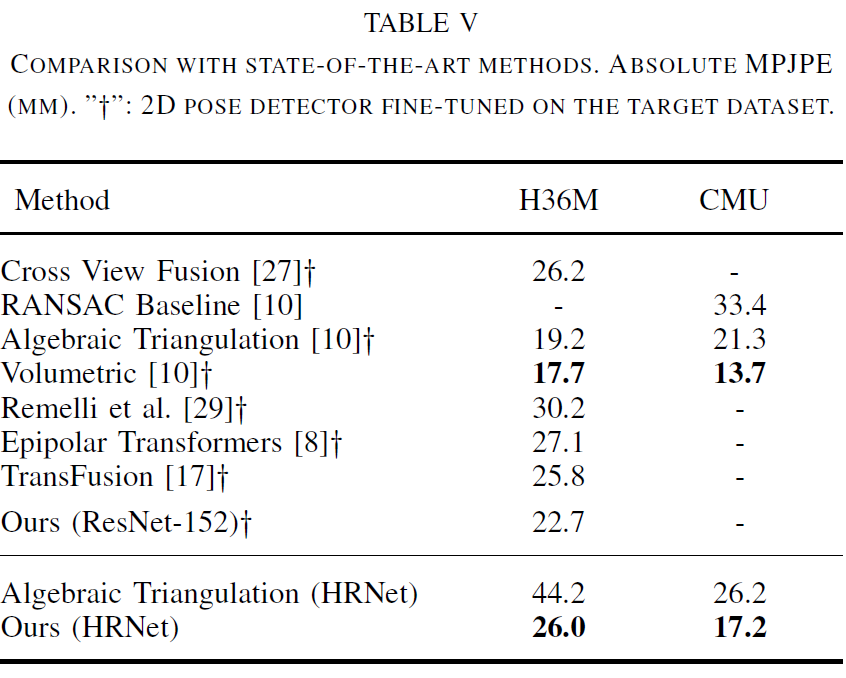
F. Comparison with Other Methods
표 V에서는 H36M 및 CMU Panoptic 데이터셋에서 본 연구 방법과 이전 연구를 비교합니다. 다른 방법들은 목표 데이터셋에 맞게 미세 조정된 2D 포즈 감지기를 사용합니다. 공정한 비교를 위해, 본 연구에서는 의 감지기를 통해 얻은 2D 포즈로 모델을 학습했습니다. 이 설정에서 경쟁력 있는 결과를 얻었습니다. 보다 현실적인 시나리오를 고려하기 위해, 상용 알고리즘을 사용하여 인간의 바운딩 박스를 감지하고 2D 포즈를 추출했습니다. 상용 감지기를 이용한 절대 포즈 재구성 결과를 제공하는 다른 방법이 없는 것으로 알고 있기 때문에, HRNet 감지기에 의 대수적 삼각측량 방법을 적용하고 본 연구 방법과 비교했습니다. 여기서 본 연구 접근법이 기준선보다 우수한 결과를 달성했습니다.
G. Ablation Studies
이 논문에서는 제안된 방법의 구성 요소들을 하나씩 제거하면서 그 유용성을 평가했습니다. 기하학적 바이어스와 신뢰도 바이어스를 제거하면 재구성 정확도가 떨어지는 것이 확인되었습니다. 데이터셋 간의 일반화를 평가할 때는 합성 뷰와 센터링이 성능을 크게 향상시켰지만, 동일한 데이터셋 내 평가에서는 그 효과가 명확하지 않았습니다. 이는 H36M과 CMU 데이터셋의 촬영 영역 크기가 상당히 다르기 때문으로 추정됩니다.
또한, 입력 시퀀스의 시간 프레임 수가 성능에 미치는 영향을 연구했습니다. H36M과 H36M-Occl 데이터셋에서 HRNet 2D 탐지 결과와 4개의 뷰를 입력으로 사용한 결과, 입력 시퀀스 길이가 길어질수록 재구성 정확도가 향상되었습니다. 특히, 가림이 있을 때 시간 정보는 매우 중요하며, 이전 시간 프레임 하나만 추가해도 큰 성능 향상이 나타났습니다.

5. CONCLUSION
이 논문에서는 여러 시점에서 얻은 2D 포즈 데이터를 이용해 Transformer 기반 인코더-디코더 아키텍처를 사용한 3D 인간 포즈 재구성 방법을 제안했습니다. 이 방법은 편향된 self-attention을 활용하여 2D 포즈 검출 네트워크와 쉽게 통합될 수 있고, 광각 배치 및 실시간 시스템에 적합합니다. 세 개의 대규모 데이터셋 실험 결과, 제안된 방법이 가림이 심하거나 입력 뷰가 적을 때에도 기존 삼각측량 기반 방법보다 일관되게 우수한 성능을 보였습니다. 그러나 새로운 인간 포즈를 재구성하는 데 어려움이 있는 점이 주요 한계로 지적되었으며, 이를 해결하기 위해 대규모 3D 모션 캡처 데이터셋으로 사전 학습하거나 자기 지도 학습을 탐색하는 방법이 제안되었습니다. 또한, 향후 연구로는 잠재 공간 크기를 입력 수와 분리하는 방법과 다중 인물 설정으로 확장하는 방향이 제시되었습니다.
1. 에피폴라 기하학
에피폴라 기하학은 두 개의 서로 다른 시점에서 동일한 3D 물체를 촬영한 이미지를 기반으로, 해당 물체의 3D 위치와 관계를 설명하는 기하학적 개념입니다. 주로 스테레오 비전 또는 다중 시점 카메라 시스템에서 사용됩니다.
- 에피폴라 평면: 두 카메라의 광학 중심과 3D 점을 연결한 평면을 말합니다. 이 평면이 각 카메라 이미지에서 형성하는 선을 에피폴라 선이라고 합니다.
- 에피폴라 선: 한 카메라에서 찍은 특정 점이 다른 카메라 이미지에서 어디에 있을지를 나타내는 선입니다. 두 시점에서 동일한 3D 점을 보았을 때, 이 점이 각 카메라의 이미지에서 에피폴라 선 위에 위치하게 됩니다.
에피폴라 기하학은 두 이미지 간의 관계를 수학적으로 표현하여 깊이 정보를 추정하는 데 중요한 역할을 합니다. 특히, 삼각측량(triangulation)을 통해 3D 재구성을 할 때 필수적으로 사용됩니다.

에피폴라 기하학을 좀 더 쉽게 설명하자면, 두 개의 카메라가 각각 3D 물체를 서로 다른 각도에서 2D 이미지로 찍었을 때, 이 두 이미지에서 얻은 정보를 이용해 3D 물체의 위치나 형태를 알아낼 수 있다는 것입니다.
예를 들어, 첫 번째 카메라에서 찍힌 이미지에서 어떤 물체의 특정 점을 보게 되면, 그 점은 실제로 3D 공간에서 여러 위치에 있을 수 있습니다. 하지만 두 번째 카메라가 그 점을 다른 각도에서 찍었기 때문에, 그 점의 정확한 3D 위치를 두 이미지 사이의 관계를 통해 계산할 수 있게 됩니다. 두 카메라에서 동일한 점을 찍은 정보를 서로 대조해서, 그 점이 실제로 3D 공간의 어디에 있는지를 알 수 있게 되는 것이죠.
쉽게 말해, 두 개의 2D 이미지를 비교해서 물체의 3D 위치를 재구성할 수 있는 기술이 바로 에피폴라 기하학입니다.
2. 조화 임베딩(harmonic embedding)
조화 임베딩(harmonic embedding)은 주파수 정보를 사용하여 시간적 또는 공간적 데이터를 표현하는 기법입니다. 여기서 "15 frequencies"라는 표현은 다음과 같은 의미를 갖습니다:
- 주파수의 개념: 주파수는 시간이나 공간에 따른 반복적인 패턴을 나타냅니다. 예를 들어, 음악에서 다양한 음이 각기 다른 주파수를 갖는 것처럼, 조화 임베딩에서도 서로 다른 주파수의 변화를 통해 정보를 표현합니다.
- 15개의 주파수 사용: 본 연구에서는 조화 임베딩을 만들기 위해 15개의 서로 다른 주파수를 선택했습니다. 이는 모델이 다양한 주파수의 변화를 캡처할 수 있도록 하여, 시간적인 변화나 신호의 특징을 더 잘 학습할 수 있게 합니다.
- 임베딩의 목적: 이러한 주파수를 사용함으로써 모델은 데이터를 더 풍부하게 표현할 수 있으며, 특히 시계열 데이터나 동적 상황에서의 패턴을 잘 포착할 수 있습니다. 주파수가 높을수록 빠른 변화, 낮을수록 느린 변화를 나타내는 데 도움을 줍니다.
결국, 15개의 주파수를 사용하여 모델이 시간적 또는 공간적 데이터의 복잡한 패턴을 더 잘 이해하고 학습할 수 있도록 하는 것입니다. 이러한 방식은 주로 신호 처리나 머신 러닝에서 데이터의 표현력을 높이기 위해 활용됩니다.