* 본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
abstract
이 논문은 RGB 영상을 사용하여 다른 센서 없이 인체 포즈를 추정하는 방법을 제안하며, 이는 비용 절감 및 사용 편의성 측면에서 중요한 연구입니다. 최근 다양한 분야(예: HCI, 로봇 공학, 비디오 분석, 메타버스)에서 3D 인체 포즈 추정에 대한 요구가 증가하고 있습니다. 단일 시점의 RGB 영상만으로 3D 인체 포즈를 추정하는 기존 연구들은 깊이 모호성, 객체 폐색, 배경 혼란, 학습 데이터 부족과 같은 어려움을 겪고 있습니다. 본 연구에서는 MoveNet을 기반으로 하여 폐색이 없는 데이터에서 빠르게 3D 인체 포즈를 추정할 수 있는 모델을 제안하였습니다. 또한, 3D 포즈 추정을 위해 하이퍼파라미터를 최적화하고, 단일 RGB 영상만을 사용한 상태에서 기존 최신 연구들과 성능을 비교하였습니다.
Ⅰ. 서 론
이 논문의 서론에서는 COVID-19 팬데믹으로 인해 전 세계적으로 이동과 활동이 제한되면서 운동 부족과 같은 건강 문제가 대두되었다고 설명합니다. 이에 대한 해결책으로 비대면 홈 트레이닝 플랫폼의 개발이 가속화되고 있으며, 이러한 플랫폼에서 3D 인체 포즈 추정 기술의 중요성이 강조되고 있습니다. 특히, 단일 시점의 RGB 영상만으로 3D 인체 포즈를 정확하게 추정하는 기술이 필요합니다.
기존 연구들은 단일 시점의 RGB 이미지를 이용하여 3D 포즈를 추정하는 데 깊이의 모호성, 객체의 폐색, 복잡한 배경, 학습 데이터 부족 등의 문제를 겪어왔습니다. 이 논문에서는 이러한 문제를 해결하기 위해 MoveNet 기반의 확장 모델을 제안하며, 하이퍼파라미터 최적화를 통해 기존의 방법들과 비교하여 성능을 평가합니다.
Ⅱ. 배경지식 및 관련 연구
이 논문에서는 2D 인체 자세 추정과 3D 인체 자세 추정에 관한 기존 연구들을 배경으로 소개합니다. 2D 인체 자세 추정은 이미지나 비디오 프레임에서 인체의 주요 관절을 식별하고 좌표를 추출하는 과정을 설명하며, 최근 딥러닝 기술의 발전으로 인해 이러한 추정의 정확도가 크게 향상되었음을 강조합니다. 이를 통해 감시, 행동 분석, 자율주행 등의 다양한 응용 분야에서 인체 움직임을 분석할 수 있습니다.
또한, 3D 인체 자세 추정에 대해서는 세 가지 주요 접근 방법을 소개합니다:
- 프레임 간 추적 기반 방식: 프레임 간의 연속적인 추적을 통해 3D 자세를 추정하는 초기 접근법입니다.
- 2D-3D 포즈 리프팅: 2D 이미지에서 키포인트를 검출한 후 이를 기반으로 3D 포즈로 변환하는 방식입니다.
- 직접 회귀 분석: 이미지의 픽셀 데이터를 직접 사용하여 3D 자세를 유추하는 방식입니다.
기존 연구들은 주로 폐색 문제와 학습 데이터 부족을 해결하기 위해 노력해 왔으며, 본 논문에서는 MoveNet을 기반으로 이러한 문제를 개선하고 폐색 없는 데이터에서 정확한 3D 포즈 추정을 목표로 하는 모델을 제안합니다.
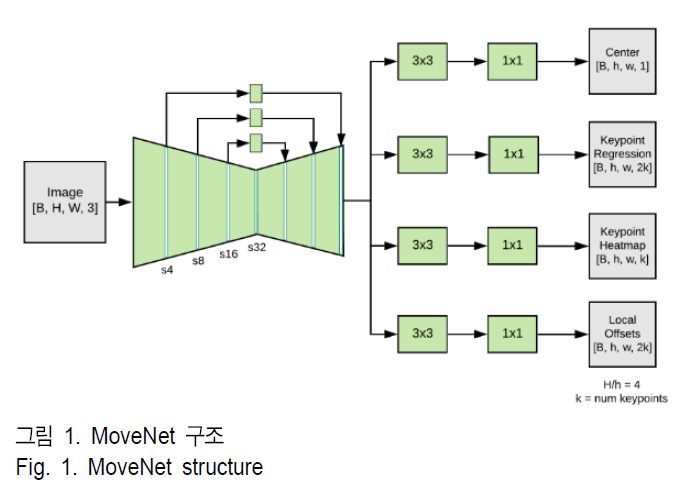
Ⅲ. 3D 휴먼 키포인트 추정기
본 장에서는 3D 휴먼 키포인트 추정기의 구조와 동작 방식을 설명합니다. MoveNet의 2D 키포인트 추정 모델을 확장하여 3D 키포인트를 추정하는 방식으로 구성됩니다. 제안된 모델은 AI-Hub의 피트니스 데이터셋을 기반으로 하여 학습되었습니다.
1. 데이터 전처리 및 3D 월드 좌표 변환
- 5개의 카메라에서 촬영된 다각도 영상을 사용하여 각 이미지에서 2D 픽셀 좌표와 해당하는 3D 월드 좌표를 얻습니다.
- 3D 월드 좌표를 2D 픽셀 좌표로 변환하기 위해 회전, 크기 변환, 평행 이동 등의 과정을 거칩니다. 이 과정에서 3D 키포인트의 X축을 고정하여 180도 회전하고, Y축을 기준으로 \( \theta \)도 회전합니다.
[검토] 이 글을 작성한 시점(2024년 10월 8일) 기준으로, AI-Hub에서 제공하는 피트니스 데이터셋에는 3D 월드 좌표가 포함된 별도의 파일(3d.json)이 존재하여, 2D 픽셀 좌표와 함께 제공되고 있습니다. 해당 3D 좌표는 다각도 카메라로 수집된 2D 좌표를 이용해 계산된 것으로, 이를 통해 데이터가 연구에 적합한 형식으로 잘 구축되어 있음을 확인할 수 있었습니다. 보다 자세한 내용은 [참조 2]에서 확인할 수 있습니다.
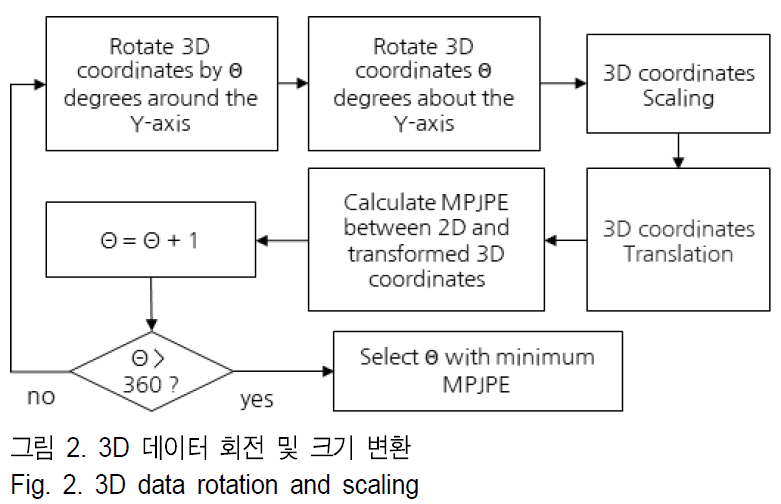
2. 2D JPE 계산
- 변환된 3D 키포인트와 2D 픽셀 좌표의 차이를 계산하여 2D JPE(Joint Position Error)를 측정합니다. 이는 다음과 같은 식으로 정의됩니다:
\[\text{2D JPE} = \sum_{j} \sqrt{(x_j - \hat{x}_j)^2 + (y_j - \hat{y}_j)^2}\]
여기서 \( (x_j, y_j) \)는 2D 픽셀 좌표이고, \( (\hat{x}_j, \hat{y}_j) \)는 변환된 3D 좌표의 투영 값입니다.
3. 손실 함수 정의
- 모델 학습 시, 예측된 키포인트와 실제 키포인트 간의 차이를 절대값으로 취하는 L1 손실 함수를 사용하여 학습합니다. 이 손실 함수는 다음과 같이 표현됩니다:
\[\text{RegLoss} = \frac{1}{J} \sum_{j=1}^{J} \lvert Y_j - \hat{Y}_j \rvert\]
여기서 \( J \)는 키포인트의 개수, \( Y_j \)는 실제 키포인트, \( \hat{Y}_j \)는 예측된 키포인트입니다.
4. 클리핑 함수 적용
- 히트맵의 활성화 값을 제한하기 위해 클리핑 함수를 적용합니다. 기존 2D MoveNet에서는 임계값을 0.1로 설정했지만, 3D 추정의 경우 출력 차원이 확대되어 활성화 영향을 줄이기 위해 0.001로 설정합니다:
\[\text{clip}(x) = \begin{cases} x & \text{if } x > \text{threshold} \\ 0 & \text{if } x \leq \text{threshold}\end{cases}\]
여기서 threshold는 0.001로 설정되어 있습니다.
5. 모델 아키텍처 및 출력
- 입력은 \( 192 \times 192 \times 3 \)의 컬러 이미지이며, MobileNetV2를 통해 특징 맵을 추출합니다. 이 특징 맵은 48×48×48 크기의 히트맵으로 변환됩니다.
- 최종적으로 회귀 필드를 통해 키포인트를 예측하며, 히트맵과 로컬 오프셋을 결합하여 3D 좌표를 산출합니다.

6. MPJPE (Mean Per Joint Position Error)
- MPJPE는 예측된 키포인트와 실제 키포인트 간의 평균 유클리드 거리를 측정하여 모델의 성능을 평가합니다:
\[\text{MPJPE} = \frac{1}{N} \sum_{i=1}^{N} \sqrt{(X_i - \hat{X}_i)^2 + (Y_i - \hat{Y}_i)^2 + (Z_i - \hat{Z}_i)^2}\]
여기서 \( (X_i, Y_i, Z_i) \)는 실제 3D 키포인트이고, \( (\hat{X}_i, \hat{Y}_i, \hat{Z}_i) \)는 예측된 3D 키포인트입니다.
이렇게 구성된 3D 휴먼 키포인트 추정기는 AI-Hub의 피트니스 데이터셋을 활용하여 성능을 검증하였으며, 다양한 실험을 통해 기존 모델 대비 높은 정확도를 보였습니다.
Ⅳ. 3D 휴먼 키포인트 추정기 실험
1. 실험 환경
실험은 Windows 10 운영체제와 RTX-3090 GPU, Ryzen 7 5800X CPU (3.8GHz) 환경에서 진행되었습니다. 이 실험 환경은 단일 시점의 RGB 이미지를 입력으로 하여 모델의 성능을 평가하기 위해 구성되었습니다. Python 3.9와 CUDA v11.6이 사용되었으며, 96GB RAM이 제공되었습니다.
2. 실험 결과 및 분석
실험은 MPJPE (Mean Per Joint Position Error)를 사용하여 성능을 평가하였으며, 이는 추정된 키포인트와 실제 키포인트 사이의 유클리드 거리의 평균값으로 정의됩니다. MPJPE가 낮을수록 모델의 예측이 정확함을 나타냅니다.
3. 모델 비교 및 성능
테스트 데이터셋에 대한 MPJPE는 다른 최신 연구들과 비교되었습니다. 제안된 모델의 MPJPE는 41.9로, 기존 모델들에 비해 더 낮은 값을 기록하며 더 정확한 3D 키포인트 추정 성능을 입증했습니다.
4. 하이퍼파라미터 최적화
히트맵의 활성화 임계값을 조정하여 모델의 성능을 최적화했습니다. 기존의 MoveNet에서는 임계값을 0.1로 설정했으나, 3D 출력의 크기가 커짐에 따라 0.001로 낮추어 학습을 진행했습니다. 이러한 조정은 모델의 초기 학습 단계에서 성능을 개선하는 데 중요한 역할을 했습니다.
5. 클리핑 및 검증 정확도
클리핑 임계값에 따른 검증 실험을 통해, 초기 학습 단계에서는 낮은 임계값이 도움이 되지만, 학습이 진행됨에 따라 임계값을 높이는 것이 필요하다는 결론에 도달했습니다. 최종적으로 최적의 임계값을 통해 학습된 모델은 82% 이상의 정확도를 보였습니다.
Ⅴ. 결 론
이 논문에서는 단일 RGB 영상을 사용하여 3D 인체 포즈를 추정할 수 있는 시스템을 제안하였습니다. 기존의 2D 인체 포즈 추정 모델인 MoveNet을 확장하여, 3D 키포인트를 예측하는 모델을 설계했습니다. 제안된 모델은 AI-Hub 피트니스 데이터셋을 기반으로, 3D 월드 좌표를 2D 픽셀 좌표로 변환하여 학습에 활용하였으며, 데이터를 정밀하게 가공하여 학습 효율성을 높였습니다.
성능 평가 결과, 제안된 모델은 기존 연구들보다 낮은 MPJPE(Mean Per Joint Position Error)를 기록하며 더 높은 정확도를 입증했습니다. 이러한 결과는 단일 시점의 RGB 영상만을 활용하여 3D 키포인트 추정을 가능하게 하는 시스템의 가능성을 보여줍니다. 향후 연구에서는 모델의 정확도를 더욱 개선하고, 다양한 환경에서의 실시간 적용 가능성을 탐색할 예정입니다.
1. MoveNet
MoveNet은 Google에서 개발한 경량화된 2D 인체 포즈 추정 모델로, 실시간으로 사람의 신체 주요 관절 위치(키포인트)를 예측하는 데 사용됩니다. 이 모델은 높은 정확도와 빠른 처리 속도로 모바일 및 엣지 디바이스에서 효율적으로 동작하도록 설계되었습니다. MoveNet은 주로 피트니스 트래킹, 비디오 분석, 증강 현실(AR), 로봇 제어 등의 응용 분야에서 사용됩니다.
- MoveNet의 특징
- 경량성 및 실시간 처리: MoveNet은 딥러닝 기반의 경량화된 구조를 사용하여 높은 처리 속도를 자랑하며, 모바일 기기나 엣지 컴퓨팅 환경에서도 실시간으로 인체의 2D 포즈를 추정할 수 있습니다.
- 높은 정확도: 다양한 환경과 자세에 대해 높은 예측 정확도를 제공하며, 특히 객체가 없는 상태에서 인체의 주요 관절(총 17개의 키포인트)을 정확히 추정합니다.
- 유연한 사용 가능성: MoveNet은 단일 프레임 이미지와 연속된 프레임으로 구성된 비디오 모두에서 사용할 수 있으며, 여러 사람의 포즈도 동시에 추정할 수 있는 확장성을 갖추고 있습니다. - MoveNet의 적용 분야
- 피트니스 앱: 운동 자세 분석 및 피드백 제공
- 증강 현실(AR): 가상 캐릭터의 움직임을 실제 사용자의 움직임에 맞춰 동기화
- 스포츠 분석: 선수의 움직임 분석 및 성능 개선 지원
- 로봇 제어 및 HCI: 인간의 움직임을 인식하여 로봇이나 시스템을 제어 - 기술적 개요
MoveNet은 딥러닝 기반의 Convolutional Neural Network (CNN) 구조를 사용하며, Lite 모델과 Thunder 모델이라는 두 가지 버전으로 제공됩니다.
- Lite 버전: 더 작은 모델 크기와 빠른 속도로 모바일 환경에서 최적화된 성능 제공
- Thunder 버전: 더 높은 정확도를 제공하며, 컴퓨팅 자원이 더 많은 환경에 적합
MoveNet은 이러한 특성으로 인해 다양한 장치와 환경에서 2D 포즈 추정의 효율성을 극대화하며, 특히 메타버스와 같은 인터랙티브 플랫폼에서의 응용 가능성을 넓히고 있습니다.
2. 3D 월드 좌표를 2D 픽셀 좌표로 변환 설명 추가
다음은 실제 AI-Hub 피트니스 데이터셋에서 추출한 3D 월드 좌표와 2D 픽셀 좌표를 이용하여 변환 과정을 예시로 설명합니다.
예시
데이터 파일: `D20-9-811-3d.json`와 `D20-9-811.json`에서 하나의 프레임을 선택하여 Nose 키포인트의 3D 좌표와 2D 픽셀 좌표를 사용합니다.
1. 3D 좌표와 2D 좌표 확인:
- 3D 월드 좌표 (`D20-9-811-3d.json` 파일에서):
- `Nose`: \( (x, y, z) = (56.109, 86.824, 12.137) \)
- 2D 픽셀 좌표 (`D20-9-811.json` 파일에서 view1):
- `Nose`: \( (x, y) = (855, 608) \)
2. 3D 좌표의 X축 고정 및 180도 회전:
- 초기 3D 좌표 \( (x, y, z) = (56.109, 86.824, 12.137) \)를 기준으로 X축을 고정하여 180도 회전합니다.
- 이때 Y축과 Z축의 값이 뒤집힙니다:
\[(x', y', z') = (56.109, -86.824, -12.137)\]
3. Y축 고정 후 θ도 회전:
- 회전한 좌표에서 Y축을 고정한 후, 특정 각도 \( \theta \)로 회전합니다. 예를 들어, \( \theta = 30^\circ \)라 가정하면, Z축과 X축의 변화를 계산합니다:
\[x'' = x' \cos(\theta) - z' \sin(\theta)\] \[z'' = x' \sin(\theta) + z' \cos(\theta)\]
- 계산 결과:
\[x'' = 56.109 \cos(30^\circ) - (-12.137) \sin(30^\circ)\]\[z'' = 56.109 \sin(30^\circ) + (-12.137) \cos(30^\circ)\]
- 결과 좌표: \( (x'', y', z'') \)
4. 크기 변환과 평행 이동:
- 변환된 3D 좌표를 2D 좌표에 맞추기 위해 스케일링(크기 변환)을 적용합니다. 예를 들어, 스케일 팩터를 \( s = 15 \)로 설정했다면:
\[(x''', y''') = (s \cdot x'', s \cdot y')\]
- 이후, 평행 이동을 적용하여 2D 좌표와 일치하도록 조정합니다. 예를 들어, \( (dx, dy) = (200, 100) \) 만큼 이동합니다:
\[x_{\text{final}} = x''' + dx\]\[y_{\text{final}} = y''' + dy\]
5. 2D JPE 계산:
- 변환된 3D 좌표의 투영 값 \( (x_{\text{final}}, y_{\text{final}}) \)와 실제 2D 픽셀 좌표 \( (855, 608) \) 간의 JPE를 계산합니다:
\[\text{2D JPE} = \sqrt{(x_{\text{final}} - 855)^2 + (y_{\text{final}} - 608)^2}\]
이 과정을 반복하여 각 카메라 뷰에 맞는 최적의 \( \theta \)와 변환된 3D 좌표를 찾고, 최소의 2D JPE를 가지는 좌표를 선택합니다.
추가
- Y축 회전 공식
만약 3D 좌표가 (x,y,z)이고, Y축을 기준으로 \theta만큼 회전한다고 가정하면, 회전 후의 좌표 (x′,y′,z′)는 다음과 같이 계산됩니다:
\[\begin{pmatrix} x' \\ y' \\ z' \end{pmatrix} = \begin{pmatrix} \cos(\theta) & 0 & \sin(\theta) \\ 0 & 1& 0 \\ -\sin(\theta) & 0 & \cos(\theta) \end{pmatrix} \begin{pmatrix} x \\ y \\ z \end{pmatrix} =\begin{pmatrix} x \cos(\theta) + z \sin(\theta) \\ y \\ -x \sin(\theta) + z \cos(\theta) \end{pmatrix}\] - 예제
주어진 3D 좌표: \( (x, y, z) = (56.109, 86.824, 12.137) \)
회전 각도: \( \theta = 30^\circ \)
계산
1. \( x' \) 계산:
\[x' = 56.109 \cdot \cos(30^\circ) + 12.137 \cdot \sin(30^\circ)\]
2. \( y' \) 계산:
\[y' = 86.824\]
3. \( z' \) 계산:
\[z' = -56.109 \cdot \sin(30^\circ) + 12.137 \cdot \cos(30^\circ)\]
실제 값 대입 후 계산
1. \( \cos(30^\circ) = \frac{\sqrt{3}}{2} \approx 0.866 \), \( \sin(30^\circ) = \frac{1}{2} = 0.5 \)
\[x' = 56.109 \cdot 0.866 + 12.137 \cdot 0.5\]\[x' \approx 48.592 + 6.069\]\[x' \approx 54.661\]
2. \( y' = 86.824 \) (변화 없음)
3. \( z' \) 계산:
\[z' = -56.109 \cdot 0.5 + 12.137 \cdot 0.866\]\[z' \approx -28.055 + 10.510\]\[z' \approx -17.545\]
회전 후의 최종 좌표
\[(x', y', z') \approx (54.661, 86.824, -17.545)\]
3. MPJPE (Mean Per Joint Position Error)
MPJPE는 3D 키포인트 추정의 성능을 평가하기 위한 지표로, 예측된 각 관절 위치와 실제 관절 위치 사이의 평균 유클리드 거리를 계산합니다. 수식은 다음과 같습니다:
\[\text{MPJPE} = \frac{1}{N} \sum_{i=1}^{N} \sqrt{(x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2 + (z_i - \hat{z}_i)^2}\]
여기서:
- \( N \)은 관절의 개수 (키포인트의 수)입니다.
- \( (x_i, y_i, z_i) \)는 실제 관절의 3D 좌표입니다.
- \( (\hat{x}_i, \hat{y}_i, \hat{z}_i) \)는 예측된 관절의 3D 좌표입니다.
이 수식은 각 관절의 예측 값과 실제 값 사이의 유클리드 거리를 계산한 후, 이를 모든 관절에 대해 평균하여 MPJPE를 구합니다. MPJPE 값이 낮을수록 예측의 정확도가 높음을 의미합니다.