본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
이 글을 읽기전에 먼저 읽어보세요:
Abstract
딥 신경망 학습의 난점은 입력을 정보가 풍부한 중간 표현으로 변환하는 비지도 사전학습으로 완화될 수 있다. 본 논문은 입력 일부를 의도적으로 손상한 뒤 원본을 복원하도록 학습시키는 Denoising Autoencoder(DAE) 를 제안하며, 이를 층별로 쌓아 깊은 구조를 안정적으로 초기화한다. 이 원리는 다양체 학습·정보 이론·에너지 기반 모델 관점에서 해석될 수 있고, MNIST 등에서 기존 방법보다 낮은 오류율을 달성함으로써 입력 손상의 이점을 입증하였다.
1. Introduction
최근 이론 연구(Bengio & Le Cun, 2007; Bengio, 2007)는 복잡한 확률 분포를 효율적으로 모형화하고 어려운 인식 과제에서 일반화 성능을 향상시키기 위해 심층 아키텍처가 필요함을 시사한다. 층을 깊게 쌓으면 표현력과 모형 능력이 증가한다는 생각은 오래전부터 제기되어 왔으나(McClelland et al., 1986; Hinton, 1989; Utgoff & Stracuzzi, 2002), 실제 학습은 두 가지 이유로 어려웠다. 첫째, 심층 방향 그래프 모델에서 “설명 상쇄(explaining away)”로 인한 추론 난제가 존재한다. 둘째, 다층 신경망은 최적화 문제(기울기 소실 등)로 인해 두 개 이상의 은닉층에서 기대한 성능 향상을 얻기 어려웠다(Bengio et al., 2007; Bengio, 2007). 이러한 한계는 최근 Deep Belief Network와 스택형 오토인코더를 활용한 비지도 사전학습(Hinton et al., 2006; Hinton & Salakhutdinov, 2006; Bengio et al., 2007; Ranzato et al., 2007; Lee et al., 2008) 방식의 성공으로 극복되기 시작하여, 깊은 구조 학습이 실질적 성과를 거두고 있다.
심층 신경망 학습의 최근 성과에서 핵심 역할을 하는 요소 중 하나는 비지도 학습 기반의 층별 초기화(layer-wise unsupervised pretraining)이다. 이 접근은 각 층이 하위 층에서 전달받은 표현을 바탕으로, 관측된 입력 패턴에 대한 더 높은 수준의 은닉 표현을 생성하도록 로컬 비지도 학습 기준(local unsupervised criterion)을 최적화하여 학습된다. 이러한 표현은 연산이 누적됨에 따라 점차 더 추상적인 표현으로 진화하며, 이후에는 전체 모델을 대상으로 과제에 적합한 지도 학습 기준(supervised criterion)을 통해 전역 미세 조정(global fine-tuning)을 수행한다. 이 초기화 방식은 임의 초기화에 비해 불량한 지역 최적해에 갇히는 문제를 완화하는 것으로 경험적으로 확인되었다.
그러나 이러한 방식에서 “좋은” 중간 표현이란 무엇인지, 그리고 이를 학습시키는 명시적인 기준이 무엇인지는 아직 충분히 이해되지 않았다. 현재까지 이 목적에 효과적인 것으로 입증된 알고리즘은 제한 볼츠만 머신(RBM)을 활용한 contrastive divergence 학습 방식과, 여러 유형의 오토인코더(autoencoder) 방식이 대표적이다.
본 연구는 딥 아키텍처 학습을 위한 중간 표현(intermediate representation)이 충족해야 할 명시적인 기준은 무엇인가라는 질문에서 출발한다. 가장 기본적으로, 중간 표현은 입력에 대한 일정량의 정보(information)를 보존해야 하며, 동시에 오토인코더와 같은 설정에서는 정해진 형식(예: 고정된 크기의 실수 벡터)으로 제약을 받아야 한다.
이러한 기본 조건 외에도, 기존 연구(Ranzato et al., 2008; Lee et al., 2008)에서는 희소성(sparsity)을 추가적인 기준으로 제안해왔다. 본 연구에서는 여기에 더해 입력의 부분 손상(partial destruction)에 대한 강건성(robustness)을 새로운 구체적 기준으로 제안하고 이를 실험적으로 검증하고자 한다. 즉, 부분적으로 손상된 입력(partially destructed inputs)**도 거의 동일한 표현을 산출해야 한다(yield almost the same representation)는 것이다.
이 가설은 다음과 같은 비공식적인 논리에 기반한다. 우수한 표현은 관측된 입력 분포의 안정적인 구조(stable structure)―즉 변수 간의 종속성과 규칙성―를 포착해야 하며, 특히 고차원 입력(예: 이미지)의 경우에는 많은 차원에 걸친 단서들을 결합하여 의미 구조를 인식해야 한다. 따라서 일부 차원만 관측되어도 그 구조가 복원 가능해야 한다.
이러한 개념은 인간이 가려지거나 손상된 이미지를 인식하는 능력, 또는 이미지와 소리 등 다중 모달 정보 중 일부가 결손되더라도 고차 개념을 재인식하는 능력에서 잘 드러난다.
이 가설의 타당성을 검증하고, 딥 아키텍처 학습의 유도 원리 중 하나로서의 유용성을 평가하기 위해, 본 연구는 오토인코더(autoencoder) 구조를 수정하여 부분 손상 입력에 대한 강건성(robustness)을 명시적으로 통합한 학습 프레임워크를 제안한다.
- 2장에서는 알고리즘 세부를 설명하고,
- 3장에서는 기존 문헌과의 연결점을 논의하며,
- 4장에서는 다양한 이론적 관점에서 모델을 분석하고,
- 5장에서는 실제 성능 차이를 실험적으로 검증하며,
- 6장에서 연구를 종합적으로 결론짓는다.
이와 같은 구조를 통해 본 논문은 “강건성”이라는 기준을 중심으로 딥러닝 표현 학습의 이론적 토대를 확장하고자 한다.
2. Description of the Algorithm
2.1 Notation and Setup
우리는 두 개의 확률 변수 X와 Y를 고려하며, 이들은 결합 확률분포 $p(X,Y)$를 따른다. 각 변수는 자신의 주변 확률분포, 즉 마지날 분포인 $p(X), p(Y)$를 가지고 있다. 확률분포에 기반한 다양한 개념들을 사용할 때 우리는 정보 이론에서 정의된 몇 가지 중요한 수학적 도구들을 활용한다.
먼저 기대값은 어떤 함수 $f(X)$ 에 대해 확률분포 $p(X)$ 하에서 그 함수의 평균적인 값을 나타내며, 수식으로는 $\mathbb{E}_{p(X)}[f(X)] =\int p(x)f(x)dx$ 로 표현됩니다. 엔트로피는 확률분포의 평균적인 불확실성, 혹은 정보의 놀라움의 정도를 나타내며, 이는 $H(X) = \mathbb{E}_{p(X)}[-\log p(X)]$로 계산된다. 조건부 엔트로피는 Y가 주어졌을 때의 X에 대한 평균적인 불확실성을 나타내며, $H(X|Y) = \mathbb{E}_{p(X,Y)}[-\log p(X|Y)]$ 라는 형태로 주어진다.
또한, 우리가 어떤 실제 확률분포 pp와 모델이 예측하는 확률분포 $q$ 간의 차이를 측정하고자 할 때에는 Kullback-Leibler 다이버전스(KL divergence)를 사용한다. 이는 확률분포 $p$의 입장에서 얼마나 $q$가 비효율적으로 정보를 표현하는지를 나타내며, 식으로는 $ D_{KL}(p || q) = \mathbb{E}_{p(X)}\left[\log \frac{p(X)}{q(X)}\right] $로 정의된다. 크로스 엔트로피는 $p$분포에 따라 $q$를 사용하여 부호화할 때 기대되는 정보량을 의미하며 $ H(p||q) = H(p) + D_{KL}(p||q) $라는 관계로 표현된다.
두 확률 변수 간에 얼마나 많은 정보를 공유하고 있는지 나타내는 측정치로는 상호정보량(Mutual Information)이 있다. 이는 $ I(X; Y) = H(X) - H(X|Y) $로 정의되며, X를 알고 있을 때 Y에 대해 얼마나 더 잘 알 수 있는지를 수량적으로 표현한다. 이러한 개념들을 바탕으로 머신러닝의 전형적인 지도학습(supervised learning) 설정을 고려한다. 지도학습에서는 입력과 해당 정답쌍으로 구성된 훈련 데이터셋 $ D_n = \{(x^{(1)}, t^{(1)}), (x^{(2)}, t^{(2)}), \ldots, (x^{(n)}, t^{(n)}) \}$이 사용된다. 이 데이터는 알려지지 않은 분포 $q(X, T)$ 에서 독립적으로 동일한 방식으로(i.i.d.) 샘플링된 것으로 가정하며, 이에 따라 입력 $X$와 타겟 $T$ 의 주변 분포 $q(X), q(T) $ 도 존재한다고 생각할 수 있다.
이 모든 정의와 개념은 확률론과 정보이론을 기반으로 하여 머신러닝 모델의 학습과 일반화 성능을 이론적으로 분석하고 향상시키는 데 중요한 기초를 제공한다.
2.2 The Basic Autoencoder
오토인코더(autoencoder)는 입력 데이터를 저차원의 잠재 표현(latent representation)으로 압축한 뒤, 이를 다시 원래의 데이터 공간으로 복원하는 신경망 구조다. 대표적으로 Bengio et al., 2007에서 심층 학습의 기반을 다지는 데 사용되었다.

입력 벡터 $ x $는 각 요소가 0과 1 사이의 값을 가지며, 차원이 $ d $이다. 이 벡터는 먼저 은닉 표현 $ y $로 매핑된다. 이때 $ y $ 역시 범위의 $ d' $ 차원 벡터이며, 인코더 함수 $ f_{\theta}(x) = s(Wx + b) $를 사용한다. $ W $는 $ d' \times d $ 크기의 가중치 행렬, $ b $는 편향 벡터, $ s(\cdot) $는 시그모이드 활성화 함수다.
은닉 표현 $ y $는 또 한 번 디코더(decoder) 네트워크를 통해 원래의 입력 공간과 동일한 차원의 벡터 $ z $로 복원된다. 복원 과정은 $ z = g_{\theta'}(y) = s(W'y + b') $식으로 나타내며, 여기서 $ W' $와 $ b' $는 디코더의 가중치와 편향이다. 경우에 따라서는 디코더의 가중치 행렬을 인코더의 전치 행렬과 같도록(Tied Weights) 제한을 두기도 한다. 이러한 구조는 파라미터 수 절감과 더불어 학습상의 제약을 제공한다.
훈련에서 각 입력 $ x^{(i)} $는 대응하는 은닉 표현 $ y^{(i)} $, 복원 벡터 $ z^{(i)} $를 갖고, 모델은 원본과 복원의 차이를 최소화하는 파라미터를 찾는다. 대표적인 손실 함수로는 제곱 오차 $ L(x, z) = \|x - z\|^2 $가 있으며, 입력과 복원이 이진 데이터이거나 베르누이 확률로 해석될 수 있을 땐 reconstruction cross-entropy가 자주 사용된다.
크로스 엔트로피 손실은 다음과 같이 주어진다:
$$
L_{\mathrm{IH}}(x, z) = -\sum_{k=1}^{d} [x_k \log z_k + (1 - x_k) \log(1 - z_k)]
$$
이 손실은 입력 벡터가 이진일 경우, 해당 복원 벡터에 대한 음의 로그 가능도(negative log-likelihood)와 같다.
최종적으로 전체 손실의 평균이 최소화되도록 파라미터를 학습하며, 보통은 경험적 데이터 분포에 대한 기댓값 형태로 다음과 같이 나타낼 수 있다:
$$
\theta^*, \theta'^* = \arg\min_{\theta, \theta'} \mathbb{E}_{q_0(X)} [L_{\mathrm{IH}}(X, g_{\theta'}(f_{\theta}(X)))] \tag1
$$
여기서 $ q_0(X) $는 훈련 데이터가 따르는 경험적 분포이고, 최적화는 대개 확률적 경사하강법(stochastic gradient descent)으로 진행된다.
즉, 오토인코더는 입력 데이터를 효율적으로 인코딩한 뒤 디코딩하여 복원하고, 원본과 복원 데이터 간의 차이가 가장 작아지도록 파라미터를 조정하는 방식으로 학습된다. 이 과정에서 사용하는 손실 함수는 데이터 특성에 따라 선택할 수 있다.

※ 정보이론에서의 크로스 엔트로피, 엔트로피, KL 다이버전스 관계 증명
-> Auto encoder 논문 요약 페이지에 정리하였지만, 다시 한 번 정리한다.
1. 정보이론적 기본 정의
- 엔트로피(Entropy):
확률분포 $P$의 불확실성, 즉 평균 정보량은 다음과 같이 정외된다.
$$
H(P) = -\sum_x P(x) \log P(x)
$$
- 크로스 엔트로피(Cross-Entropy):
실제 분포 $P$ 와 모델 분포 $Q$ 간의 평균 정보량(또는 코드 길이)은
$$
H(P, Q) = -\sum_x P(x) \log Q(x)
$$
- KL 다이버전스(Kullback-Leibler Divergence):
서로 다른 두 확률분포 $P$와 $Q$의 불일치 정도(비대칭적 거리)는
$$
D_{KL}(P\|Q) = \sum_x P(x) \log \frac{P(x)}{Q(x)}
$$
2. 세 함수의 수식적 관계 전개
KL 다이버전스를 전개하면:
$$
D_{KL}(P\|Q) = \sum_x P(x)\log \frac{P(x)}{Q(x)} = \sum_x P(x)\log P(x) - \sum_x P(x)\log Q(x)
$$
즉,
$$
D_{KL}(P\|Q) = -H(P) + H(P, Q)
$$
따라서
$$
H(P, Q) = H(P) + D_{KL}(P\|Q)
$$
즉, 크로스 엔트로피는 엔트로피와 KL 다이버전스의 합이다.
3. 베르누이 분포에서의 적용과 오토인코더 손실 함수
오토인코더에서 입력 $ x $와 출력(복원값) $ \tilde x $가 각각 [1] 구간의 확률 또는 0/1 벡터일 때,
- 엔트로피:
$$
H(x) = -[x \log x + (1-x)\log(1-x)]
$$
- 크로스 엔트로피(손실 함수로 사용):
$$
H(x, \tilde x) = -[x \log \tilde x + (1-x)\log(1-\tilde x)]
$$
- KL 다이버전스:
$$
D_{KL}(x\|\tilde x) = x \log \frac{x}{\tilde x} + (1-x)\log \frac{1-x}{1-\tilde x}
$$
이들을 항목별로 전개해 보면
$$
H(x) + D_{KL}(x\|\tilde x) = -[x \log x + (1-x)\log(1-x)] + x \log \frac{x}{\tilde x} + (1-x)\log \frac{1-x}{1-\tilde x}
$$
$$
= -[x \log x + (1-x)\log(1-x)] + x(\log x - \log \tilde x) + (1-x)(\log(1-x) - \log(1-\tilde x))
$$
$$
= -[x \log x + (1-x)\log(1-x)] + x \log x + (1-x)\log(1-x) - x\log \tilde x - (1-x)\log(1-\tilde x)
$$
$$
= -x\log \tilde x - (1-x)\log(1-\tilde x) = H(x, \tilde x)
$$
즉, 베르누이 분포에서의 크로스 엔트로피 손실 수식이 정보이론적 정의와 정확히 일치함을 확인할 수 있다.
2.3 The Denoising Autoencoder
기존의 오토인코더는 입력 벡터 $ x \in ^d $를 받아, 잠재 공간(latent space)에 표현된 은닉 벡터 $ y \in ^{d'} $를 거쳐, 다시 복원된 벡터 $ z \in [0,$( 0 이상 1 이하의 실수 값을 가진다는 의미 )로 출력하는 구조였다. 이때 오토인코더는 복원된 출력 $ z $가 가능한 한 원래 입력 $ x $과 가깝도록 훈련되며, 손실 함수로는 일반적으로 평균 제곱 오차(Mean Squared Error) 또는 크로스 엔트로피(Cross-Entropy)가 사용된다.
그러나 단순한 오토인코더는 항등함수(x = z)를 쉽게 학습하여 입력을 그대로 복사하게 되는 문제가 있다. 이 경우 학습된 모델은 본질적인 표현을 추출하지 못하고 일반화 능력이 떨어진다. 이를 해결하기 위해 Denoising Autoencoder라는 확장 모델이 제안된다.
1. 입력 파괴 과정 (Corruption Process)
Denoising Autoencoder 에서는 원본 입력 $x$를 확률적 맵핑을 통해 손상된 입력 $\tilde{x}$로 변환한다. 이 과정은 다음과 같이 표현된다:
$$ \tilde{x} \sim q_D(\tilde{x} \mid x) $$
여기서 $ q_D $는 입력 $x$를 부분적으로 손상시키는 파괴 분포(corruption distribution)이며, 전체 입력 차원 $d$ 중에서 비율 $\nu$에 해당하는 $\nu d$개의 성분을 무작위로 선택하고, 그 값들을 0으로 강제로 설정한다. 나머지 성분은 변형 없이 유지된다.
즉, $\tilde{x}$는 부분적으로 0으로 마스킹된 입력이고, 이는 실제 데이터 손실이나 결측(missing values), 노이즈 등의 현상을 시뮬레이션하는 역할을 한다.
2. 네트워크 구성 및 복원 과정
손상된 입력 $\tilde{x}$는 인코더를 통해 은닉 표현 $y$로 변환되고, 다시 디코더를 통해 복원 결과 $z$로 출력된다:
- 인코더(Encoder):
$$ y = f_\theta(\tilde{x}) = s(W\tilde{x} + b) $$
- 디코더(Decoder):
$$ z = g_{\theta'}(y) = s(W'y + b') $$
여기서:
- $ s(\cdot) $는 시그모이드 활성화 함수
- $ \theta = \{W, b\} $, $ \theta' = \{W', b'\} $는 각각 인코더와 디코더의 학습 파라미터이다.
3. 손실 함수 (Reconstruction Loss)
복원된 벡터 $z$는 원본 입력 $x$와 비교하여 손실을 계산하며, 이때 사용하는 손실 함수는 크로스 엔트로피(Cross-Entropy)로 표현된다:
$$ L_{\text{CE}}(x, z) = -\sum_{k=1}^d \left[ x_k \log z_k + (1 - x_k) \log(1 - z_k) \right] $$
이 손실은 $x$가 베르누이 분포를 따르는 경우 음의 로그 가능도(Negative Log-Likelihood)와 같은 역할을 하며, $z_k$는 각 위치 $k$에서 복원된 확률을 나타낸다.
4. 최적화 목적 함수 (Objective Function)
전체 학습 목표는, 손상된 입력 $\tilde{x}$로부터 원본 입력 $x$를 최대한 정확하게 복원하도록 오토인코더의 파라미터 $\theta, \theta'$를 학습하는 것이다. 따라서 손실 함수의 기대값을 최소화하는 형태로 최적화 문제는 다음과 같이 정의된다:
$$
\min_{\theta, \theta'}\ \mathbb{E}_{q_0(x) q_D(\tilde{x} \mid x)} \left[ L_{\text{CE}}(x, z) \right]
= \mathbb{E}_{q_0(x) q_D(\tilde{x} \mid x)} \left[ L_{\text{CE}}(x,\ g_{\theta'}(f_\theta(\tilde{x}))) \right]
$$
여기서:
- $ q_0(x) $는 훈련 데이터의 경험적 분포
- $ q_D(\tilde{x} \mid x) $는 입력에 대한 손상 확률 분포
- 전체 분포 $ q_0(x, \tilde{x}) $는 원본 $x$에서 손상된 버전 $\tilde{x}$로의 확률 흐름을 반영
또한 은닉 표현 $y$는 $\tilde{x}$로부터의 결정적 결과이므로 다음과 같은 조인트 분포로도 표현할 수 있다:
$$ q_0(x, \tilde{x}, y) = q_0(x)\ q_D(\tilde{x} \mid x)\ \delta_{f_\theta(\tilde{x})}(y) $$
여기서 $\delta_u(v)$는 $u = v$일 때 확률 1, 그렇지 않으면 0을 주는 디랙 델타 함수로, $y$가 $\tilde{x}$의 결정적 함수(deterministic function)임을 나타낸다.
※ 보충 설명
각 기호의 의미
- $q_0(X)$:
훈련 데이터(원본 데이터) $X$에 대한 경험적(즉 실제 관측된) 분포다. 보통 데이터셋의 샘플 빈도.
- $q_D(\tilde{X}|X)$:
원본 데이터 $X$를 손상(노이즈 주입 등)시켜 손상된 데이터 $\tilde{X}$를 생성하는 '확률적(혹은 결정적) 손상 함수'.
예를 들어 어떤 픽셀을 무작위로 0으로 바꾼다든지, 노이즈를 더한다든지 하는 과정이 이에 해당한다.
- $Y$:
손상된 입력 $\tilde{X}$를 오토인코더의 인코더(예: $f_\theta$)로 통과시켜 얻은 은닉 표현(latent representation).
즉 $Y = f_\theta(\tilde{X})$.
- $\delta_{f_\theta(\tilde{X})}(Y)$:
Dirac delta function로, $Y$가 정확히 $f_\theta(\tilde{X})$일 때만 1이고, 그렇지 않으면 0이 됩니다.
이렇게 하면 "은닉표현 $Y$는 반드시 $\tilde{X}$를 인코더에 넣었을 때 결과로 나온다"는, 결정적 함수임을 수학적으로 명시한다.
전체 식의 해석
이 식은 (원본, 손상본, 은닉표현) 세 변수의 공동 분포(joint distribution)를 의미한다.
- 먼저 원본 샘플 $X$를 경험적 분포 $q_0(X)$에서 샘플링한다.
- 그 $X$를 손상 함수 $q_D(\tilde{X}|X)$에 의해 손상하여 $\tilde{X}$를 얻는다.
- 손상된 입력 $\tilde{X}$를 인코더 $f_\theta$에 집어넣어 $Y$를 얻는다.
- delta function은 "오직 $Y = f_\theta(\tilde{X})$일 때만 확률이 0이 아닌 값을 가진다"는 것을 보장한다.
즉,
1. 원본 데이터 $X$를 뽑아서,
2. $X$에서 $\tilde{X}$(손상버전)를 만들고,
3. $\tilde{X}$를 신경망 인코더로 $Y$로 보내며,
4. 이 모든 과정을 동시에 "확률적으로 기술"한 분포가 바로 $q_0(X, \tilde{X}, Y)$이다.
요약 (쉽게):
- $q_0(X)$: 실제 관측된 원본데이터(정상 데이터)의 분포
- $q_D(\tilde{X}|X)$: 원본에서 랜덤하게 손상된 데이터(노이즈 입력) 만드는 과정
- $Y = f_\theta(\tilde{X})$: 손상 이미지를 인코더에 넣어 얻는 잠재 벡터(은닉표현)
- $\delta_{f_\theta(\tilde{X})}(Y)$: $Y$는 $\tilde{X}$에서 결정적으로(즉, 항상 동일하게) 얻어짐을 명시
이 식은 “정상 데이터 → 손상 데이터 → 은닉표현”의 확률적-결정적 변환 과정을 하나의 3변수 분포로 정식화한 것이다.
쉽게 말해,
실제 데이터 $X$로부터 랜덤하게 노이즈를 넣은 $\tilde{X}$를 만들고, 다시 그 $\tilde{X}$를 인코더에 넣어 $Y$까지 얻는 전체 과정을 확률적으로 기술한 것이다.
5. 학습 방식과 장점
학습은 확률적 경사 하강법(Stochastic Gradient Descent) 방식으로 수행된다. 구체적으로는 다음과 같은 과정이 반복된다:
1. 훈련 데이터에서 입력 샘플 $x$을 선택하고
2. 일부 성분을 0으로 바꾼 손상된 형태 $\tilde{x}$를 생성
3. $\tilde{x}$를 오토인코더에 통과시켜 복원 결과 $z$를 얻고
4. 원본 $x$와 $z$를 비교해 손실을 계산 후, 파라미터 $\theta, \theta'$를 업데이트
이러한 구조에서는 입력과 출력이 항상 다르기 때문에, 오토인코더가 항등함수를 학습할 수 없게 된다. 따라서 더 이상 은닉 차원 $d'$이 입력 차원 $d$보다 작아야 할 필요가 없고(trivial solution 회피), 정규화 기법 없이도 일반화 가능한 특성 표현을 학습하게 된다.
2.4 Layer-wise Initialization and Fine Tuning
딥 네트워크를 효과적으로 학습시키기 위해 기본 오토인코더는 층별(layer-wise)로 학습된 후, 그 파라미터가 전체 네트워크의 초기값으로 사용된다. 구체적으로, 첫 번째 오토인코더가 입력을 받아 은닉 표현을 학습하면, 두 번째 오토인코더는 이 은닉 표현을 새로운 입력으로 삼아 별도로 학습된다. 이런 방식으로 여러 층이 차례로 추가되며 각각 독립적으로 학습된다. 각 층이 모두 예비학습(pretraining)을 마치면, 전체 네트워크는 지도학습(supervised fine-tuning) 기준에 따라 추가적으로 전체 파라미터를 미세조정한다. 이와 같은 'greedy layer-wise' 방식은 무작위 초기화에 비해 더 좋은 학습 성능과 더 나은 일반화 결과를 가져오는 것으로 밝혀졌다.
denoising autoencoder로도 동일한 층별 학습이 활용되는데, 단지 각 층의 학습에서 사용하는 손실 함수만 다르다(노이즈가 추가된 입력을 복원하도록 학습). 파괴 맵핑(qD)을 통한 입력 손상은 학습시에만 적용되고 실제 인퍼런스(표현 전달) 단계에서는 쓰이지 않는다. 또한, k번째 레이어를 학습할 때는 항상 바로 아래 레이어의 손상되지 않은(un-corrupted) 출력이 입력으로 사용된다
결과적으로, 이 층별 사전학습-미세조정 절차는 깊은 네트워크가 더 견고하고 효과적으로 학습되도록 돕는다.
3. Relationship to Other Approaches
denoising autoencoder 의 학습 방식은 노이즈가 추가된(손상된) 입력으로부터 원래의 깨끗한 입력을 복구하는, 즉 '디노이즈(denoising)' 작업에 해당한다. 이와 유사한 문제, 특히 이미지 복원(denoising)은 오래 전부터 이미지 처리 분야에서 활발히 연구되어 왔으며, 최근에는 머신러닝 기반 방식들도 많이 제안되었다. 실제로 오토인코더를 이용한 디노이즈 목적의 구조나 알고리즘도 과거부터 있었으나, 본 논문의 목표는 단순히 경쟁력 있는 디노이즈 알고리즘(특히 이미지 영역)을 만드는 것과는 근본적으로 다르다. 저자들은 오히려 노이즈에 대한 명시적 강인성 학습을 통해, 더 나은 범용 표현 학습 알고리즘을 개발하고자 한다.
즉, 입력 데이터뿐 아니라 중간 표현(intermediate representation)들까지 반복적으로 손상·복원 과정을 적용하며, 이 과정은 특정 도메인(예: 이미지)에 한정되지 않으며, 이미지 구조에 대한 사전 지식도 활용하지 않는다. 그리고 일반적으로 사용되는 데이터 증강 방식처럼 훈련 데이터를 인위적으로 변형하는 것과 유사하지만, 저자들은 이 과정에서도 별도의 사전 지식에 의존하지 않는다. 또한, 저자들이 제안한 방식은 비지도(unsupervised) 손실 기준의 최적화에만 손상된 패턴(노이즈가 추가된 예시)을 사용하는 점이 특징이다.
이 접근법은 정보손실 채널 위에서의 강인한 부호화(robust coding)에 기반한 기존 연구들과도 개념적으로 닿아 있지만, 저자들의 목적은 생물학적 뇌 해석이나 최적 전송과는 다르며, 무엇보다 오토인코더의 비선형성은 딥러닝 네트워크 초기화에 핵심적 역할을 한다고 강조한다.
또한 만약 결측값 문제를 엄밀히 다루는 것이 목적이라면, 잠재 변수 생성모델(latent variable generative model)과 사후확률 추론(posteriors over hidden representation)이 더 자연스러운 해법일 수 있지만, 이는 예측 시마다 계산 비용이 많이 드는 단점이 있다. 반면, denoising autoencoder 는 이미 노이즈가 섞인 입력 예제들을 반복적 학습을 통해 빠르고 강인하며 결정적인(deterministic) 매핑 함수를 학습하는 데 중점을 둔다. 즉, 추론할 때마다 복잡한 marginalization 대신, 학습 단계에서 괄목할 만한 제약 조건을 부여해 모델이 데이터의 암묵적 불변성(invariance)을 잘 얻는 특징들을 자동으로 학습하도록 유도한다.
마지막으로, 논문 후반(4.4)에서는 이 denoising autoencoder의 학습 알고리즘 자체가, 특정 생성모델 내에서의 변분 추론(variational inference)으로도 해석될 수 있음을 논의한다.
요약하면, denoising autoencoder는 전통적인 디노이즈 목적이나 데이터 증강과 구분되는 “표현 학습의 견고성”에 본질적 목적을 둔, 빠르고 일반화 가능한 비지도 학습 프레임워크다.
4. Analysis of the Denoising Autoencoder
앞서 denoising autoencoder는 노이즈에 강한 표현(robust representations)을 학습하기 위한 방법으로 직관적 동기를 설명했다. 이번 절에서는 그 알고리즘을 다양한 시각에서 분석해봄으로써, 좀 더 깊은 이해를 얻고자 한다.
해당 내용은 논문의 나머지 부분에 필수적인 것은 아니므로, 건너뛰어도 큰 무리는 없다. 하지만 이론적 통찰을 얻기 위해 여러 대안적 관점에서 denoising autoencoder를 해석하려는 시도를 포함하고 있다.
4.1 Manifold Learning Perspective
denoising autoencoder는 손상된 입력 데이터를 원래의 깨끗한 입력으로 복원하는 학습 과정을 통해, 데이터가 분포하는 저차원 공간 구조, 즉 다양체(manifold)를 학습하는 방식으로 이해할 수 있다. 현실의 고차원 데이터(예: 이미지)는 단순한 고차원 공간 전체에 균일하게 분포하는 것이 아니라, 훨씬 더 낮은 차원의 다양체 근처에 집중되는 경향이 있다. 이 모델은 손상된 입력이 이 다양체에서 벗어난 위치에 있을 경우, 원래 입력의 위치로 되돌아가도록 만드는 함수적 매핑을 학습한다.
학습 과정에서는 손상된 입력 $\tilde{x}$가 원본 입력 $x$에 비해 다양체에서 멀어진 상태가 되며, 이를 다시 다양체 근처의 고확률 영역으로 복원하기 위한 확률적 연산자 $p(X|\tilde{X})$를 학습한다. 즉, denoising autoencoder는 낮은 확률 밀도를 가진 지점(노이즈 포함 입력)에서 높은 확률 밀도를 가지는 지점(다양체 근처)으로 이동시키는 맵(mapping)을 학습하는 셈이다. 이 맵은 손상의 정도가 클수록 더 큰 '이동'을 학습하게 된다. 결과적으로 denoising autoencoder는 단순히 손상된 입력을 복원하는 것을 넘어서, 데이터가 의미 있게 분포하는 공간 구조 그 자체를 정의하고 움직이는 방향을 학습하는 것이다.
이 과정에서 오토인코더가 학습하는 은닉 표현 $y = f(x)$는 다양체 상의 좌표계처럼 작동하는 새로운 표현 공간이 된다. 특히 은닉 공간의 차원이 입력보다 작을 경우, 이 표현은 저차원 다양체 위의 좌표로 해석될 수 있다. 그리고 희소성(sparsity)이나 다른 제약 조건이 있는 경우에도, 은닉 표현은 여전히 데이터의 주요 변화를 잘 반영하여 중요한 특징만을 압축적으로 담은 표현으로 기능하게 된다.
즉, denoising autoencoder는 데이터 위에 내재된 저차원 구조를 학습하는 강력한 표현 학습 도구이며, 이 구조를 통해 노이즈에도 강인하게 작동하는 특성 추출과 복원 능력을 갖추게 된다.

4.2 The Stochastic Operator Perspective
denoising autoencoder는 확률적 연산자(stochastic operator) 관점에서 이해할 수 있다. 이 관점에서, 오토인코더는 손상된 입력 $\tilde{X}$로부터 원래의 입력 $X$를 복원하는 조건부 확률 분포 $p(X \mid \tilde{X})$를 학습하며, 이를 이용해 $X$와 $\tilde{X}$ 사이의 공동 분포(joint distribution) $p(X, \tilde{X})$를 정의할 수 있다.
구체적으로, 이 공동 분포는 두 분포의 곱으로 표현된다:
$$p(X, \tilde{X}) = p(\tilde{X}) \cdot p(X \mid \tilde{X})$$
여기서 $p(\tilde{X})$는 손상된 입력의 분포를 의미하며, 이는 모델이 직접 학습하는 것이 아니라, 훈련 데이터로부터 정의되는 경험적 분포 $q_0(\tilde{X})$를 그대로 사용한다.
모델 학습은 이 경험적 공동 분포 $q_0(X, \tilde{X})$와 모델이 정의한 공동 분포 $p(X, \tilde{X})$ 사이의 KL 다이버전스를 최소화하는 방식으로 진행된다.
즉,
$$D_{KL}(q_0(X, \tilde{X}) \parallel p(X, \tilde{X}))$$
를 최소화하는 것이 학습 목표이며, 이는 본래 denoising 목적에서 사용한 손실 함수와 다시 연결된다.
이와 같은 방식으로 학습하면, 모델이 정의한 마지널 분포 $p(X)$는 실제 데이터 분포 $q_0(X)$에 점차 가까워지게 된다. 결국 denoising autoencoder는 경험적 데이터 분포를 근사할 수 있는 준-파라메트릭(semi-parametric) 모델로 작동하게 되며, 이는 단순히 복원을 잘하는 것이 아니라, 데이터의 본질적인 분포 구조까지 학습하는 방식이다.
denoising autoencoder : KL 다이버전스, 확률 모델링, 가중평균 비유의 통합 정리
1. KL 다이버전스와 모델 분포의 의미
Denoising Autoencoder의 주요 학습 목표 중 하나는 $ D_{\text{KL}}(q_0(X, \tilde{X}) \parallel p(X, \tilde{X})) $ 을 최소화하는 것이다.
- 여기서 $q_0(X, \tilde{X})$는 실제 데이터에서 관찰된 원본 $X$와 손상된 $\tilde{X}$로 이뤄진 경험적 결합 분포이고,
- $p(X, \tilde{X})$는 모델이 정의한, $\tilde{X}$에서 $X$를 복원하는 확률적 모델 결합 분포다.
이 KL 다이버전스를 낮출수록, 모델의 주변 분포 $p(X)$가 실제 데이터 분포 $q_0(X)$와 점점 더 가까워진다.
즉, 오토인코더가 데이터의 본질적 구조를 더 잘 모사하게 된다.
2. $p(X)$ 수식과 실제적 의미
오토인코더가 학습한 $X$에 대한 분포 $p(X)$는 다음과 같이 계산한다:
$$
p(X) = \frac{1}{n} \sum_{i=1}^{n} \sum_{\tilde{x}} p(X \mid \tilde{X} = \tilde{x}) \cdot q_D(\tilde{x} \mid x_i)
$$
- $x_i$: 전체 $n$개의 훈련 데이터 원본 샘플
- $\tilde{x}$: $x_i$에서 생성 가능한 여러 손상본(노이즈, 마스킹 등)
- $q_D(\tilde{x} \mid x_i)$: $x_i$로부터 $\tilde{x}$가 만들어질 확률(즉, 손상 공정 자체의 확률)
- $p(X \mid \tilde{X})$: 손상본 $\tilde{x}$로부터 원본 $X$를 복원할 확률(신경망 예측)
- 모든 손상본과 원본에 대해 곱해서 합하고 평균을 내 최종 $p(X)$를 평가함
3. 주사위 기대값과 가중평균 비유
이 구조는, "각 경우의 값에 그 경우가 나올 확률을 곱하고 모두 합하는" 가중평균(weighted average) 방식과 같다.
예를 들어 주사위 기대값 계산에서
- 1이 나올 확률 0.5, 2는 0.1, 3은 0.12라면,
- 기대값 = $1 \times 0.5 + 2 \times 0.1 + 3 \times 0.12 + ...$
오토인코더의 $p(X)$ 역시 "각 손상본에서 $X$가 복원될 신뢰도 × 해당 손상본이 나올 확률" 을 모두 곱해 합하는, 확률적 가중평균과 같은 원리다.
즉, 모든 원본과 손상본 조합, 복원 성공 신뢰도를 일일이 반영해 최종적으로 "입력이 실제 데이터에서 얼마나 가능성 있는지"를 모델로 학습하게 된다.
4. 왜 $p(X \mid \tilde{X})$만 최적화하고, 나머진 고정인가?
이 모델에서는 학습 동안 오직 $p(X \mid \tilde{X})$의 파라미터만 최적화한다.
- 손상공정 $q_D(\tilde{x} \mid x_i)$는 이미 정의된 노이즈 추가/마스킹 등의 규칙에 따른 정해진 분포다.
(예: 픽셀 n% 마스킹, 정규 노이즈 주입 등)
- $p(X \mid \tilde{X})$는 손상된 입력에서 원본을 복원하는 확률로, 오토인코더의 디코더 신경망이 학습해서 얻은 복원 확률이다.
- 따라서 학습에서는 이 디코더의 가중치(파라미터)만을 업데이트하게 된다.
즉,
- 손상 과정의 확률은 학습에서 고정되어 있고
- 복원 함수만(네트워크의 파라미터만) 최적화 대상인 구조다.
5. 샘플링이 쉽다는 의미
이 구조에서는 모델에서 샘플을 생성(복원)하는 과정이 매우 간단하다.
- 먼저, 실제 데이터 $x_i$를 정해진 방법으로 손상하여 $\tilde{x}$를 만듭니다(기존 손상 알고리즘 적용).
- 이후, 학습된 오토인코더 디코더(함수 $p(X \mid \tilde{X})$)에 $\tilde{x}$를 넣어 $X$를 복원(샘플링)한다.
이 과정은 복잡한 확률적 추론 없이, 정해진 손상 + 신경망 네트워크의 순전파만으로 이루어져 빠르고 쉽게 샘플을 뽑을 수 있다는 의미다.
정리
- denoising autoencoder는 손상된 입력에서 원본을 복원하는 확률(신경망 파라미터)만 학습하며,
- 손상 공정(노이즈 부여)의 확률은 이미 고정돼 있다.
- 전체적인 확률 모델은 "가중평균" 방식으로, 주사위 기대값 공식과 구조가 같고,
- 샘플링은 매우 간단하게 가능하다는 장점이 있다.
- 결과적으로, 이 방식은 경험적 데이터에 근거해 일반화 가능한 확률적 복원 모델을 효과적으로 학습하는 방법이다.
세미파라메트릭 모델(semi-parametric model)이란?
세미파라메트릭 모델은 통계와 머신러닝에서 자주 쓰이는 개념으로, 순수하게 파라메트릭(모수적) 모델이나 논파라메트릭(비모수적) 모델의 장점을 모두 결합한 모델 유형이다.
1. 파라메트릭 vs 논파라메트릭
- 파라메트릭 모델(parametric model):
- 소수의 파라미터(예: 평균, 표준편차)로 데이터 전체의 분포 구조를 완전히 설명한다.
- 예: 정규분포, 선형회귀, 로지스틱 회귀 등.
- 장점: 계산이 간단하고 효율적, 데이터 양이 적어도 견고함.
- 단점: 데이터가 가정한 분포를 따르지 않으면 성능이 떨어짐.
- 논파라메트릭 모델(non-parametric model):
- 특별한 분포 가정을 하지 않고, 데이터 자체로 구조를 학습한다.
- 예: 커널 밀도 추정, k-최근접 이웃(k-NN), 의사결정나무 등.
- 장점: 유연성이 높아 복잡한 데이터도 잘 설명할 수 있음.
- 단점: 데이터가 많아야 하고 계산량이 많음.
2. 세미파라메트릭 모델의 정의 및 특징
- 세미파라메트릭 모델(semi-parametric model):
- 일부 구조(성분)는 소수의 파라미터로 설명하고(파라메트릭),
나머지 구조는 분포적 가정 없이 유연하게 모델링(논파라메트릭)한다.
- 즉, 정해진 함수 구조와 자유로운 함수 구조가 혼합되어 있는 모델.
- 대표 예시:
- Cox 비례위험모형(Cox proportional hazards model):
생존분석에서, 위험함수(hazard function)는 파라메트릭 선형식과, 시간에 따른 논파라메트릭 밑변수 함수가 결합됨.
- 척도(location, scale)는 정해진 파라미터로, 나머지 함수 형태는 자유롭게 추정하는 회귀.
3. denoising autoencoder에서의 예
- denoising autoencoder 논문에서 세미파라메트릭 모델이란,
- 모델 내부의 일부는 신경망(파라메트릭: 복원 함수의 파라미터)을 통해 학습되고,
- 전체 데이터 분포 자체는 경험적으로 산출된 데이터 빈도(논파라메트릭 또는 데이터 기반 분포)에 의존하는 구조를 말한다.
- 즉, "신경망 복원 파라미터만 학습하고, 손상 모델이나 데이터 분포는 고정된" 혼합적 확률 모델을 의미한다.
4. 요약
- 세미파라메트릭 모델은 파라메트릭 구조(모수 기반 공식)와 논파라메트릭 구조(데이터 기반 유연 모델)의 장점을 조합한 모델이다.
- 덕분에 가정이 너무 엄격하지 않으면서도 복잡한 데이터 구조를 상대적으로 효과적으로 설명할 수 있다.
- 머신러닝이나 통계, 그리고 응용 분야 전반에 걸쳐 널리 활용되는 중요한 개념이다.
다음으로 손상된 입력을 복원하는 연산자를 반복 적용함으로써 얻어지는 확률 분포의 동역학을 살펴본다. 첫 단계에서는 경험 분포 $q_0(\tilde X)$를 초기 분포 $p_0(X)$로 삼고, 이후 $p_1(X)=p(X)$를 거쳐 재귀적으로
$$
p_k(X)=\sum_x p(X\mid\tilde X=x)\,p_{k-1}(x)
$$
를 통해 분포가 갱신된다. 이 연산자가 충분히 섞이는 성질(에르고딕)을 가진다면, 무한 반복 후에는 더 이상 변하지 않는 고정점 분포 $\pi(X)=\lim_{k\to\infty}p_k(X)$에 수렴하게 된다. 흥미로운 점은, 이 $\pi(X)$가 오직 모델 파라미터만으로 정의되는 순수한 모수적 분포라는 것이며, 기존에 경험 분포와 합성된 반모수 모델 $p(X)$는 이 $\pi(X)$의 일차 근사에 불과하다는 점이다. 따라서 반복적 복원을 통해 경험적 데이터에 명시적으로 의존하지 않는 완전한 모수적 분포를 이론적으로 도출할 수 있다. denoising autoencoder는 이처럼 데이터로부터 학습된 확률적 복원 연산자를 통해, 깔끔하면서도 표현력 있는 데이터 분포 모델을 형성할 수 있게 되는 것이다.
"만약 이 확률적 연산자(손상된 입력에서 원본으로 복원하는 함수)를 여러 번 반복 적용한다면 어떻게 될까?"에 대해 자세히 풀어보자.
1. 확률적 연산자란?
- 여기서 확률적 연산자란,
손상된 입력 $\tilde{X}$가 주어졌을 때 원본 입력 $X$가 될 확률 분포 $p(X \mid \tilde{X})$를 말한다.
2. 반복 적용의 정의
- 처음에 분포 $p_0(X)$를 정의하는데,
이는 손상된 입력이 원본처럼 보일 확률 분포(이론적(모델 기반/학습된)) 분포로, 경험적 손상 분포(실제 분포, 실질적 통계값) $q_0(\tilde{X})$와 같다. 즉,
$
p_0(X = x) = q_0(\tilde{X} = x)
$
- 한 번 연산자를 적용하면,
$
p_1(X) = p(X)
$
여기서 $p(X)$는 오토인코더가 학습해서 얻은 입력 분포다.
- 이후 반복해서 연산자를 적용하면,
$
p_k(X) = \sum_{\tilde{x}} p(X \mid \tilde{X} = \tilde{x}) \cdot p_{k-1}(\tilde{x})
$
이 수식은, 이전 단계 $k-1$에서 얻은 분포 $p_{k-1}(\tilde{x})$를 기반으로 다시 손상 → 복원 연산자를 통해 새 분포 $p_k(X)$를 계산하는 과정을 의미한다.
3. 의미와 직관
- 이 과정을 반복하는 것은,
현재 가진 데이터 분포에서 손상을 시뮬레이션하고,
손상된 데이터를 다시 복원하는 연산을 계속해서 적용하는 것과 같다.
- 이때 점차 분포가 변형되며,
적절한 조건(보통 `ergodic`이라는 수학적 속성) 하에서,
분포 $p_k(X)$는 수렴하여 하나의 고정된 분포 $$\pi(X)$$에 이르게 된다.
4. 요약
- 이 연산자 반복적 적용은 마코프 체인(확률적 상태이행 과정)을 정의한다.
- 초기 확률 분포 $p_0(X)$에서 시작해서 손상-복원 과정을 거칠 때마다 새 확률분포 $p_k(X)$가 만들어지고,
- 충분히 많이 반복하면 분포 $p_k(X)$는 안정적인 최종 분포(고정점) $\pi(X)$로 수렴한다.
- 이 고정점 분포 $\pi(X)$가 바로 모델이 궁극적으로 학습하려는, 손상과 복원이 반복돼도 변하지 않는 데이터 분포라고 볼 수 있다.
쉽게 말하면
반복해서 손상된 데이터를 복원하는 연산을 적용하면, 처음에는 불완전하게 보였던 분포들이 점점 더 다듬어져서, “더 정확하고 안정적인” 데이터 분포 상태로 변해간다는 의미다. 이 과정을 Markov chain, 또는 확률적 반복 프로세스라고도 부릅니다.
요약하면, denoising autoencoder는 단순한 복원 모델이 아니라, 손상된 입력에서 원본을 추정하는 확률 연산자를 학습하고, 이를 반복 적용함으로써 데이터 분포를 근사하고 생성하는 유연한 준-파라메트릭 확률 모델로 해석할 수 있다.
4.3 Bottom-up Filtering, Information Theoretic Perspective
본 절에서는 하향식 필터링(bottom-up filtering) 관점과 정보이론적(information-theoretic) 관점을 도입한다. 이를 위해, 입력 표본을 나타내는 확률변수 $X$, 그 손상된 버전인 $\tilde X$, 그리고 이에 대응하는 은닉 표현인 $Y=f_\theta(\tilde X)$를 정의한다. 입력 $X$는 진정한 생성 분포 $q(X)$를 따르며, 손상 과정은 $q_D(\tilde X\mid X)$로, 표현 함수는 파라미터 $\theta$로 고정된 형태로 주어진다. 이들 변수의 결합분포
$$
q(X,\tilde X,Y)=q(X)\,q_D(\tilde X\mid X)\,\delta\bigl(Y - f_\theta(\tilde X)\bigr)
$$
는 기존에 사용되던 $q_0(X,\tilde X,Y)$와 동일한 의존 구조 및 동일한 조건부 분포($\tilde X\mid X$, $Y\mid\tilde X$)를 가지도록 정의되었음을 주목할 필요가 있다.
위 표현은 논문의 표기와 다르게 보일 수 있지만 단순한 표기법의 차이일 뿐, 동일한 의미를 담고 있다. 첫 번째 식
$$
q(X,\tilde X,Y)=q(X)\,q_D(\tilde X\mid X)\,\delta\bigl(Y - f_{\theta}(\tilde X)\bigr)
$$
에서의 $\delta(Y - f_{\theta}(\tilde X))$는 $Y$가 오직 $f_{\theta}(\tilde X)$일 때만 확률 질량을 갖고, 그 외에는 0이 된다는 뜻의 디랙 델타 함수를 사용한 표기다. 반면 논문에서는
$$
q_0(X,\tilde X,Y)=q_0(X)\,q_D(\tilde X\mid X)\,\delta_{\,f_\theta(eX)}(Y)
$$
와 같이 $\delta_{f_\theta(eX)}(Y)$라는 지시 함수를 도입하여 “$Y$가 $f_\theta(eX)$일 때 1, 그렇지 않을 때 0”이라고 간결히 적었다. 이 두 표기—$\delta(Y - f_\theta(\tilde X))$와 $\delta_{f_\theta(\tilde X)}(Y)$—모두 “결정적으로 $Y$는 항상 $f_\theta(\tilde X)$와 같다”는 동일한 관계를 표현하므로, 어떤 표기를 사용해도 결합 분포의 의미나 수식적 성질에는 차이가 없다.
본 연구의 사전학습(pre-training) 과정은 입력 $X$와 은닉 표현 $Y$ 간의 정보 보존과 은닉 표현의 주변분포가 바람직한 형태를 동시에 만족시키는 파라미터 $\theta$를 찾는 문제로 정의된다. 이를 위해 최적화하는 목적 함수는
$$
\max_{\theta}\;\Bigl\{\,I(X;Y)\;+\;\lambda\,J(Y)\Bigr\}
$$
으로,
* $I(X;Y)$ 항은 입력과 표현 간 상호정보(mutual information) 를 측정하여, 표현이 입력의 통계적 구조를 얼마나 잘 보존하는지를 평가한다.
* $\lambda\,J(Y)$ 항은 표현의 주변분포 $q(Y)$ 에 대해 설계자가 원하는 특성을 유도하는 보조 목적 함수로, 예를 들어
1. KL 발산: 사전분포 $p_{\mathrm{prior}}(Y)$와의 차이를 줄이기 위해
$\;J(Y)=-D_{\mathrm{KL}}\bigl(q(Y)\|p_{\mathrm{prior}}(Y)\bigr)$
2. 희소성(sparsity): 평균 활성도 제약 또는 L1 정규화를 통해
$\;J(Y)=-\sum_i\bigl|\mathbb{E}[Y_i]\bigr|$ 또는
$\;J(Y)=-\sum_iD_{\mathrm{KL}}(\mathbb{E}[Y_i]\|\rho)$
3. 독립성(independence): 차원 간 상호정보를 최소화하여
$\;J(Y)=-\sum_{i\neq j}I(Y_i;Y_j)$
4. 그 외 분산 제약, 모멘트 매칭 등 다양한 통계적 제약을 설계할 수 있다.
여기서 $\lambda$ 는 정보 보존($I$)과 주변분포 제약($J$) 사이의 절충 정도를 조절하는 하이퍼파라미터다.
그러나 본 연구에서는 은닉 표현 $Y$에 오직 차원 수(dimensionality)만을 제약한다고 가정하여, $J(Y)$ 항을 모든 분포에 대해 상수로 취급($\lambda=0$)한다. 이에 따라 결국 순수히 상호정보 $I(X;Y)$ 최대화만을 수행하는 사전학습 기준을 사용한다.
다음으로 상호정보 최대화 관점에서 오토인코더 학습 기준을 수식적으로 도출한다.
먼저
$$
I(X;Y)=H(X)-H(X\mid Y)
$$
이고, 입력 분포 $q(X)$가 고정되어 $H(X)$가 상수이므로
$$
\max_\theta I(X;Y)\;=\;\max_\theta\bigl[-H(X\mid Y)\bigr].
$$
이는 곧
$$
\max_\theta\bigl[-H(X\mid Y)\bigr]
=\max_\theta \mathbb{E}_{q(X,Y)}\bigl[\log q(X\mid Y)\bigr].
$$
하지만 실제로는 $q(X\mid Y)$를 알 수 없으므로, 임의의 분포 $p^*(X\mid Y)$로 근사하며
$$
\max_\theta \mathbb{E}_{q}[\log q(X\mid Y)]
=\max_{\theta}\max_{p^*}\mathbb{E}_{q}[\log p^*(X\mid Y)],
$$
이며 최적화 대상 $p^*$를 파라메트릭 분포 $p(X\mid Y;\theta')$로 제한하면
$$
\max_\theta\bigl[-H(X\mid Y)\bigr]
\;\ge\;
\max_{\theta,\theta'}\mathbb{E}_{q}[\log p(X\mid Y;\theta')],
$$
이 부등식은 $p(X\mid Y)=q(X\mid Y)$일 때 등호가 된다.
1. 하한(lower bound)과 KL 발산 관계
$$
\mathbb{E}_{q(X,Y)}\bigl[\log p(X\mid Y;\theta')\bigr]
= \mathbb{E}_{q}\bigl[\log q(X\mid Y)\bigr]
\;-\;D_{\mathrm{KL}}\bigl(q(X\mid Y)\;\|\;p(X\mid Y;\theta')\bigr).
$$
여기서
* $\mathbb{E}_q[\log q(X\mid Y)]$는 상수(실제 분포에 의존),
* $D_{\mathrm{KL}}(q\|p)\ge0$ 이므로
$$
\mathbb{E}_q[\log p]
\;\le\;
\mathbb{E}_q[\log q].
$$
2. 등호 성립 조건(KL divergence 정의 참조)
$$
\mathbb{E}_q[\log p]
= \mathbb{E}_q[\log q]
\quad\Longleftrightarrow\quad
D_{\mathrm{KL}}\bigl(q(X\mid Y)\;\|\;p(X\mid Y;\theta')\bigr)=0.
$$
KL 발산이 0이 되는 유일한 경우는 두 분포가 완전히 같을 때, 즉
$$
p(X\mid Y;\theta') \;=\; q(X\mid Y)
$$
인 경우뿐이다.
3. 결론
따라서
$$
\max_{\theta,\theta'}\mathbb{E}_q[\log p(X\mid Y;\theta')]
\;=\;
\mathbb{E}_q[\log q(X\mid Y)]
$$
이 되려면 반드시 $p(X\mid Y)=q(X\mid Y)$ 이어야 하고, 이때 KL 발산이 0이 되어 부등식이 등호로 바뀐다.
즉, 모든 파라미터 $(\theta,\theta')$ 중에서 $p(X\mid Y;\theta')$가 실제 후분포 $q(X\mid Y)$와 일치할 때가 하한이 최대가 되는 지점으로, 그 순간에만 등호가 성립한다.
이제 이진 벡터 $X$를 재구성하는 오토인코더를 고려하면,
$$
p(X\mid Y)=\mathrm{Bernoulli}\bigl(g_{\theta'}(Y)\bigr)
$$
로 모델링할 수 있으며, 손상 입력 $\tilde X$에 대해
$$
\begin{aligned}
\max_{\theta,\,\theta'}\;\mathbb{E}_{q(X,Y)}\bigl[\log\,\mathrm{Bernoulli}\bigl(g_{\theta'}(Y)\bigr)(X)\bigr]
&=
\max_{\theta,\,\theta'}\;\mathbb{E}_{q(X,\tilde X)}\bigl[\log\,\mathrm{Bernoulli}\bigl(g_{\theta'}\bigl(f_{\theta}(\tilde X)\bigr)\bigr)(X)\bigr]\\
&=
\min_{\theta,\,\theta'}\;\mathbb{E}_{q(X,\tilde X)}\bigl[-\log\,p\bigl(X\mid g_{\theta'}(f_{\theta}(\tilde X))\bigr)\bigr].
\end{aligned}
$$
* $\mathrm{Bernoulli}(g_{\theta'}(Y))(X)$는 $Y$로부터 복원된 이진 분포,
* $p(X\mid g_{\theta'}(f_{\theta}(\tilde X)))$는 재구성 확률을 의미.
$$
\mathbb{E}_{q(X, Y)} \left[\log \mathrm{Bernoulii}(g_{\theta'}(Y))(X)\right]
$$
이 값을 최대화한다는 것은, 오토인코더가 복원을 잘할수록, 즉 예측 확률이 원본 $X$와 가까울수록 이 항이 커진다는 의미다.
여기서 $B_{g_{\theta'}(Y)}(X)$는 보통 베르누이 또는 이항 분포의 확률을 의미하고, $g_{\theta'}(f_{\theta}(\tilde{X}))$는 손상된 입력 $$\tilde{X}$$를 통과시켜 원본을 복원하는 네트워크의 출력이다.
이 평균 로그우도(log likelihood)의 최대화는,
곧 $ L_{IH}(X, g_{\theta'}(f_\theta(\tilde{X}))) $ 즉, 교차엔트로피 또는 음의 로그 가능도 형태의 loss(손실 함수)를 최소화하는 것과 수학적으로 완전히 같은 개념이다.
요약하면,
- $$\mathbb{E}_{q(X,Y)}[\log \mathrm{Bernoulii} (g_{\theta'}(Y))(X)]$$ 값을 최대화 = 모델의 예측값이 참값과 가까워지도록 학습
- $$L_{IH}(X, g_{\theta'}(f_\theta(\tilde{X})))$$ 값을 최소화 = 복원 에러(손실)를 줄이도록 학습
이 두 표현은 동일한 훈련 목표를, 각각 최대화와 최소화 관점에서 나타낸 것이다.
즉, 손실 함수 최적화와 로그우도 최대화는 본질적으로 같은 최적화 문제임을 의미한다.
가 성립한다. 즉, 기대 재구성 오차(expected reconstruction error) 최소화는 정보이론적 $-H(X\mid Y)$ 하한을 최대화하는 것과 본질적으로 동일하다.
마지막으로, 실제 학습에서는 진짜 분포 $q$ 대신 경험 분포 $q_0$를 사용하여 이 기준(Eq. 1)을 구현한다.
4.4 Top-down, Generative Model Perspective
본 절에서는 디노이징 오토인코더 학습 기준(식 1)을 생성 모델 관점에서 재도출한다. 우선, 은닉 변수 $Y$로부터 원본 입력 $X$를 생성하고, 다시 이 $X$를 손상시켜 관측된 $\tilde X$를 얻는 세 단계의 확률적 생성 과정을 가정한다. 즉,
$$
p(X,\tilde X,Y) = p(Y)\;p(X\mid Y)\;p(\tilde X\mid X),
$$
여기서 $p(Y)$는 균일 사전분포, $p(X\mid Y)=\mathrm{Bernoulli}_s(W'Y + b')$는 복원 분포, $p(\tilde X\mid X)=q_D(\tilde X\mid X)$는 손상 과정이며, 파라미터 집합 $\theta'=\{W',b'\}$으로 이 모델을 정의한다.
실제 훈련 절차에서는 “원본 $X$와 재구성 $\hat X$을 비교해서 손실을 계산하고 파라미터를 업데이트한다.
그런데 “모델이 $\tilde X$를 얼마나 잘 설명하느냐”를 얘기하는 건, 생성 모델 관점에서의 이론적 근거를 세우기 위함이다. 요약하자면:
1. 훈련 절차
* 입력으로 주어진 손상 샘플 $\tilde X$에서
* 인코더로 $Y$를 뽑고,
* 디코더로 $X'$를 재구성한 뒤
* 원본 $X$와 비교하여 손실을 최소화
→ 여기서는 당연히 “원본과 비교”만 신경 쓰면 된다.
2. 왜 $\tilde X$ 분포를 모델링하느냐
* 학습 데이터를 “$\tilde X$+원본 $X$ 쌍”으로 본다면,
* “원본 $X$를 얼마나 잘 복원했나” = “$\tilde X$가 어떻게 생성됐는가를 얼마나 잘 역추정했나”와 동치다.
* 생성 모델 관점에서 “$\tilde X$의 우도를 최대화한다”는 것은,
“그 역추정 과정($\tilde X\to Y\to X$)이 정확하다”는 수식적 표현이다.
3. 결론
* 실제 학습은 “원본 $X$와 재구성 $X'$의 오차를 줄인다”가 맞고,
* ELBO/생성 모델은 “왜 그 오차 최소화가 통계적으로 타당한 최대우도 학습인지”를 보여 주기 위한 이론적 도구일 뿐입니다.
그러니 훈련 코드를 짤 때는 “원본과 재구성 비교”만 구현하면 되고, “$\tilde X$ 우도를 모델링”은 이론적 해석이라는 점을 기억해야 한다.
$p$가 마지막 생성 단계에서 손상 과정을 포함하고 있으므로, 우리는 손상된 훈련 샘플에 대해 $p(\tilde X)$를 최대한 잘 설명하도록 적합(fit)할 것을 제안한다. 즉, 실제로 관측되는 손상된 샘플 $\tilde X$의 주변분포 $p(\tilde X)$를 최대화하는 것이 학습의 궁극적 목표가 된다. 경험 분포 $q_0(\tilde X)$로부터 샘플을 뽑아 최대우도(maximum likelihood) 추정을 수행하면 그 문제는 다음 식을 최대화하는 것과 동치이다:
$$
H \;=\;\max_{\theta'}\;\mathbb{E}_{q_0(\tilde X)}\bigl[\log p(\tilde X)\bigr].
$$
여기서 $H$는 손상된 샘플에 대한 기댓값 로그우도(expected log-likelihood)이며, 크로스엔트로피
$$
H_{\mathrm{cross}}(q_0,p)
=-\mathbb{E}_{q_0(\tilde X)}\bigl[\log p(\tilde X)\bigr]
$$
와 비교하면
$$
\mathbb{E}_{q_0}[\log p(\tilde X)]
=-\,H_{\mathrm{cross}}(q_0,p),
$$
따라서
$$
\max_{\theta'}\;\mathbb{E}_{q_0}[\log p(\tilde X)]
\;\Longleftrightarrow\;
\min_{\theta'}\;H_{\mathrm{cross}}(q_0,p).
$$
즉, $H$를 최대화하는 것은 크로스엔트로피를 최소화하는 것과 정확히 동일한 최적화 문제다.
다음으로, $\log p(\tilde X)$가 직접 계산하기 어려우므로 임의의 보조 분포 $q^*(X,Y\mid\tilde X)$를 도입하여 변분 하한(ELBO)
$$
\mathcal{L}(q^*,\tilde X)
=\mathbb{E}_{q^*(X,Y\mid\tilde X)}\!\Bigl[\log\frac{p(X,\tilde X,Y)}{q^*(X,Y\mid\tilde X)}\Bigr]
$$
을 정의한다(“$p$” 항이 디코더(및 손상 과정을 포함한 생성 모델)를, “$q$” 항이 인코더(추론 모델)를 의미). 모든 $q^*$에 대해
$$
\log p(\tilde X)
=\mathcal{L}(q^*,\tilde X)
+ D_{\mathrm{KL}}\bigl(q^*(X,Y\mid\tilde X)\,\|\,p(X,Y\mid\tilde X)\bigr)
$$
가 성립하며, 후자의 KL 발산이 0일 때(즉 $q^*=p$) 변분 하한이 실제 로그우도에 딱 맞닿는다. 따라서
$$
\log p(\tilde X)=\max_{q^*}\mathcal{L}(q^*,\tilde X),
$$
이고, 이를 최대우도 목표
$$
H=\max_{\theta'}\;\mathbb{E}_{q_0(\tilde X)}[\log p(\tilde X)]
$$
에 대입하면
$$
H=\max_{\theta'}\;\mathbb{E}_{q_0(\tilde X)}\bigl[\max_{q^*}\mathcal{L}(q^*,\tilde X)\bigr].
$$
제약없는 $q^*$는 $\tilde X$마다 최적 후방분포를 완벽히 근사할 수 있으므로, 기대 안의 최대화를 밖으로 꺼내어(내부 식의 최적화 변수가 $\theta'$와 무관하기 때문에 바깥으로 꺼낼 수 있다)
$$
H=\max_{\theta',\,q^*}\;\mathbb{E}_{q_0(\tilde X)}\bigl[\mathcal{L}(q^*,\tilde X)\bigr]
$$
로 정리할 수 있다. 이 과정은 “관측치 우도 최대화” 문제를 “변분 하한 최대화” 문제로 바꾸어 훈련 목표를 명확히 설정한다.
이제 제약없는 $q^*$ 대신 인코더 $q_0$ 의 파라미터 $\theta$로 최대화를 근사하면, 우도 $H$에 대한 하한이
$$
H\;\ge\;\max_{\theta,\theta'}\;\mathbb{E}_{q_0(\tilde X)}\bigl[\mathcal{L}(q_0,\tilde X)\bigr].
$$
왜냐하면 “모든 $q^*$ 중 최대”는 언제나 “그중 하나인 $q_0$의 값” 이상이기 때문이다. 이 하한을 최대화하면
$$
\arg\max_{\theta,\theta'}\;\mathbb{E}_{q_0(X,\tilde X,Y)}\!\Bigl[\log\frac{p(X,\tilde X,Y)}{q_0(X,Y\mid\tilde X)}\Bigr]
=
\arg\max_{\theta,\theta'}\;\mathbb{E}_{q_0(X,\tilde X,Y)}\bigl[\log p(X,\tilde X,Y)\bigr],
$$
가 된다. 여기서
$$
q_0(X\mid\tilde X)\propto q_D(\tilde X\mid X)\,q_0(X),
\quad
q_0(Y\mid\tilde X)\text{는 결정적},
$$
따라서 이들의 엔트로피가 모두 $(\theta,\theta')$에 무관한 상수이므로, 오직
$$
\mathbb{E}_{q_0(X,\tilde X,Y)}\bigl[\log p(X\mid Y)\bigr],
\quad Y=f_\theta(\tilde X)
$$
만이 학습 대상이 된다. 즉, 인코더 파라미터 $\theta$와 디코더 파라미터 $\theta'$를 조정하여 $\mathbb{E}_{q_0}[\log p(X\mid Y)]$를 최대화하는 것이 바로 디노이징 오토인코더의 학습 기준임을 보인다.
※ 교차엔트로피 재구성 손실을 최소화하는 과정 상세
아래 일곱 단계는 인코더·디코더 파라미터 $(\theta,\theta')$를 조정해 ELBO $\mathbb{E}_{q_0}[\mathcal{L}(q_0,\tilde X)]$를 최대화하고, 결국 교차엔트로피 재구성 손실을 최소화하는 과정을 보여 준다.
1. ELBO 최대화 시작점
$$
\arg\max_{\theta,\theta'}\;\mathbb{E}_{q_0(\tilde X)}\bigl[\mathcal{L}(q_0,\tilde X)\bigr],
\quad
\mathcal{L}(q_0,\tilde X)=\mathbb{E}_{q_0(X,Y\mid\tilde X)}\Bigl[\log\frac{p(X,\tilde X,Y)}{q_0(X,Y\mid\tilde X)}\Bigr].
$$
2. 결합분포 형태로 전개
$$
\mathbb{E}_{q_0(\tilde X)}[\mathcal{L}]
= \mathbb{E}_{q_0(X,\tilde X,Y)}\bigl[\log p(X,\tilde X,Y)\bigr]
- \mathbb{E}_{q_0(X,\tilde X,Y)}\bigl[\log q_0(X,Y\mid\tilde X)\bigr].
$$
3. 두 항 분리
$\mathbb{E}_{q_0}[\log p(X,\tilde X,Y)]$
$\mathbb{E}_{q_0}[\log q_0(X,Y\mid\tilde X)]$
4. 인코더 항의 상수성
$q_0(X,Y\mid\tilde X)=q_0(Y\mid\tilde X)\,q_0(X\mid\tilde X)$에서
$q_0(Y\mid\tilde X)=\delta(Y-f_\theta(\tilde X))$ 는 결정적이므로 엔트로피 상수,
$q_0(X\mid\tilde X)\propto q_D(\tilde X\mid X)\,q_0(X)$ 는 $(\theta,\theta')$에 무관,
결국 $\mathbb{E}[\log q_0]$ 전체가 상수로 빠진다.
5. ELBO 최대화와 생성 로그우도
$$
\arg\max_{\theta,\theta'}\mathbb{E}_{q_0}[\mathcal{L}]
= \arg\max_{\theta,\theta'}\mathbb{E}_{q_0(X,\tilde X,Y)}[\log p(X,\tilde X,Y)].
$$
6. 생성 모델 분해 및 상수 제거
$p(X,\tilde X,Y)=p(Y)\,p(X\mid Y)\,p(\tilde X\mid X)$에서
$p(Y)$ 균일(상수),
$p(\tilde X\mid X)$ 손상 과정(상수),
남는 학습 항은
$\mathbb{E}_{q_0}[\log p(X\mid Y)]$ 단, $Y=f_\theta(\tilde X)$.
7. 교차엔트로피 손실로 변환
$$
\min_{\theta,\theta'}\mathbb{E}_{q_0}\bigl[-\log p(X\mid f_\theta(\tilde X))\bigr]
= \min_{\theta,\theta'}\mathbb{E}_{q_0}\bigl[L_{IH}(X,\,g_{\theta'}(f_\theta(\tilde X)))\bigr],
$$
즉 기대 재구성 오차를 최소화하는 것이 디노이징 오토인코더의 최종 학습 목표임을 수식적으로 증명한다.
마지막으로 이 식을 음의 로그우도(교차엔트로피) 형태로 바꾸면
$$
\min_{\theta,\theta'}\;\mathbb{E}_{q_0(X,\tilde X)}\bigl[-\log p\bigl(X\mid f_\theta(\tilde X)\bigr)\bigr]
=
\min_{\theta,\theta'}\;\mathbb{E}_{q_0(X,\tilde X)}\bigl[L_{IH}\bigl(X,\,g_{\theta'}(f_\theta(\tilde X))\bigr)\bigr],
$$
이 되어, 기대 재구성 오차를 최소화하는 것이 변분 하한을 최대화하는 것과 완전히 동일함을 수식적으로 증명한다.
※ 다음 일곱 단계의 동치 과정을 통해, ELBO 최대화가 곧 교차엔트로피 재구성 손실 최소화와 같다:
1. ELBO 정의 및 최대화
$\displaystyle \mathcal{L}(q_0,\tilde X)=\mathbb{E}_{q_0(X,Y\mid\tilde X)}\bigl[\log\frac{p(X,\tilde X,Y)}{q_0(X,Y\mid\tilde X)}\bigr]$ 를 최대화한다.
2. 분모 항 제거
인코더 분포 $q_0(X,Y\mid\tilde X)$는 결정적·무관 상수이므로 빠져나가,
$\displaystyle \mathbb{E}_{q_0}[\mathcal{L}]=\mathbb{E}_{q_0}[\log p(X,\tilde X,Y)] + \mathrm{const}.$
3. 생성 모델 분해
$p(X,\tilde X,Y)=p(Y)\,p(X\mid Y)\,p(\tilde X\mid X)$ 를 대입해
$\mathbb{E}_{q_0}[\log p(Y)]+\mathbb{E}_{q_0}[\log p(X\mid Y)]+\mathbb{E}_{q_0}[\log p(\tilde X\mid X)]$.
4. 상수 항 소거
$p(Y)$와 $p(\tilde X\mid X)$는 상수이므로 사라지고 오직
$\mathbb{E}_{q_0}[\log p(X\mid Y)]$ 만 남는다.
5. 인코더 반영
$Y=f_\theta(\tilde X)$ 를 대입해
$\displaystyle \mathbb{E}_{q_0}[\log p(X\mid f_\theta(\tilde X))]$.
6. 교차엔트로피로 전환
로그우도 최대화는 음의 로그우도(교차엔트로피) 최소화와 동치이므로
$\displaystyle \min_{\theta,\theta'}\mathbb{E}_{q_0}[-\log p(X\mid f_\theta(\tilde X))]$.
7. 손실 함수 정의
마지막으로 $-\log p(X\mid f_\theta(\tilde X))$를 $L_{IH}(X,g_{\theta'}(f_\theta(\tilde X)))$로 표기하여,
$$
\min_{\theta,\theta'}\;\mathbb{E}_{q_0}\bigl[L_{IH}\bigl(X,\,g_{\theta'}(f_\theta(\tilde X))\bigr)\bigr]
$$
가 디노이징 오토인코더의 학습 목표임을 수식적으로 증명한다.
5. Experiments
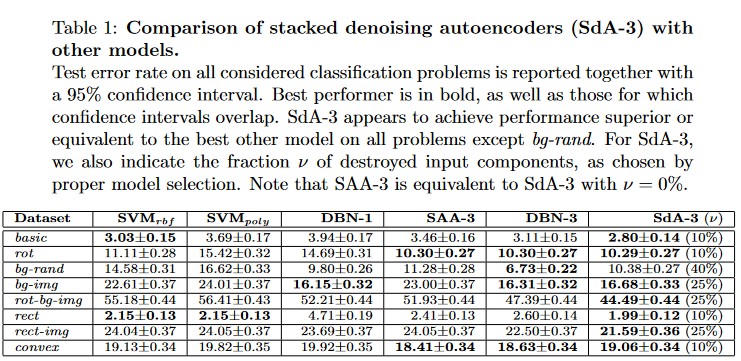
연구팀은 제안한 denoising autoencoder 기반 학습 알고리즘을 다양한 이미지 분류 문제에 적용해 성능을 평가했다. 이 실험은 Larochelle et al. (2007)에서 사용한 벤치마크 데이터셋을 동일하게 활용하였으며, 이 데이터셋은 기본 MNIST 숫자 분류 문제뿐 아니라 회전(rot), 랜덤 배경(bg-rand), 실제 이미지에서 추출한 배경(bg-img), 그 조합(rot-bg-img) 등의 다양한 변형이 포함되어 있다. 이러한 변형은 학습 알고리즘 입장에서 문제를 훨씬 더 어렵게 만들기 때문에 일반적 학습 방법의 강건성을 평가하는 데 유용하다.
각 문제는 학습용, 검증용, 테스트용 데이터셋으로 나누어졌으며(10,000 / 2,000 / 50,000개 샘플), MNIST 이외에도 도형의 볼록함(convex), 너비·길이 기반 분류(rect, rect-img) 같은 이진 분류 문제들도 포함된다. 실험에서는 3개의 은닉층을 갖는 심층 신경망 구조를 사용했으며, 이 신경망은 denoising autoencoder를 층별(stack)로 사전학습한 후(SdA-3), 지도 학습을 통해 분류 성능을 미세조정(finetuning)하는 방식으로 학습되었다.
하이퍼파라미터(예: 손상 비율 ν, 은닉층 크기, 비지도 학습 반복 횟수)는 검증 세트 결과를 기반으로 선택되었으며, 학습과정 중에는 early stopping을 적용하여 오버피팅을 방지했다. 최종 테스트 세트에 대한 분류 오류율은 Table 1에 정리되어 있으며, 기존 연구에서 보고된 다양한 모델(SVM, DBN-1/3, 기본 오토인코더 기반 SAA-3)과 비교되었다. 특히 SAA-3는 손상 없이 사전학습된 denoising autoencoder 구조, 즉 ν=0%의 SdA-3와 동일하기 때문에 직접 비교가 가능하다.
실험 결과, 거의 모든 문제에서 SdA-3 모델이 기존 모델들보다 뛰어난 분류 성능을 보여주었으며, 특히 SAA-3보다 확연히 우수했다. 이는 손상+복원 학습(denoising training)이 표현 학습에 실질적으로 도움이 되었음을 보여준다. 일부 과제를 제외하고, SdA-3는 기존의 심층 신뢰망(DBN)보다도 높은 정확도를 기록했다. 따라서 제안한 학습 방법이 더 유용하고 일반화 가능한 특징 탐지기(feature detector)를 학습한다는 점을 시사한다.
추가적으로, 손상 학습이 특징 표현에 어떤 영향을 주는지를 정성적으로 분석하기 위해, MNIST에 대해 첫 번째 오토인코더 학습 후의 필터(filter)들을 시각화하였다. 그림 3에는 다양한 손상 수준에서 학습된 가중치 행렬의 일부 행들이 이미지 패치 형태로 나타나 있으며, 이는 각각 은닉 노드들이 학습한 특징 감지기 역할을 한다. 실험 결과, 손상 없이 학습된 필터들은 의미 없는 무작위 패턴에 가까운 반면, 손상 강도를 높일수록 필터는 점차 의미 있는 특징(예: 선, 곡선)을 학습하기 시작하며, 더 넓은 범위의 입력 영역에 민감한 형태로 발전하였다. 즉, 높은 노이즈 수준에서 필터들은 더욱 확장된 구조를 포착하게 되어, 더 풍부한 특성 표현이 가능해졌
종합적으로, denoising autoencoder를 이용한 층별 초기화 방식은 기존 방법 대비 뛰어난 성능을 나타냈으며, 특히 고노이즈 환경에서 더 일반화 가능한 특징을 효과적으로 학습하는 데 유리함을 실험을 통해 입증하였다.

6. Conclusion and Future Work
이 연구에서는 오토인코더를 학습시키는 매우 단순한 원리를 제안했다. 그 핵심 아이디어는 입력이 손상된 이후 이를 복원하는 과정을 학습하도록 함으로써, 작고 비본질적인 입력 변화에 강인한 표현(representation)을 학습하는 것이다. 이러한 학습 원리는 다양체 학습(manifold learning)이나 생성 모델 관점에서도 동기 부여가 가능하며, 깊은 신경망의 사전학습(pretraining) 단계에서 오토인코더를 층별로 쌓아 학습하는 데 활용될 수 있다.
이를 평가하기 위해 이미지 분류 실험을 수행했으며, 그 결과는 다음과 같은 결론을 뒷받침한다. denoising 기준에 기반한 비지도 층 초기화는 입력 분포의 유의미한 구조를 효과적으로 포착하며, 이는 결국 후속의 감독 학습(classification) 과정에서 훨씬 더 적합한 중간 표현을 제공한다.
또한 실험에서는 심층 신뢰망(Deep Belief Network, DBN)과 비교도 이루어졌는데, DBN은 제한 볼츠만 머신(RBM)으로 층을 초기화한다. 그 결과 RBM 또한 훈련 과정 중 표현에 노이즈가 유입되기 때문에, 자연스럽게 강인한 표현을 학습하고 있을 가능성이 제기되었다.
향후 연구는 이러한 관찰에 기반해 입력뿐만 아니라 중간 표현 자체에도 다양한 손상을 가하는 방식의 학습을 탐구함으로써, 더욱 강력한 표현 학습 방법을 개발할 수 있을 것이다.