본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
※ 들어가기 전에, 용어 정리
1. 유향 확률 모델(Directed Probabilistic Model)
그래프 이론과 확률론을 결합한 표준적인 개념으로, 흔히 베이즈 네트워크(Baysian network) 라고 불린다. 구체적인 정의는 다음과 같다.
- 변수들 $\{X_1, X_2, \dots, X_n\}$을 노드(각 노드 $X_i$는 확률변수)로,
- "원인 -> 결과" 관계를 나타내는 유향 간선(화살표)로 연결한 비순환 그래프(DAG)를 구성하고,
- "각 노드 $X_i$가 부모 집합 $P_a\{X_i\}$에 조건부로만 의존한다고 가정(조건부 독립)하여,
$$P(X_1,X_2,X_3, \dots, X_n) = \prod_{i=1}^{n} P(X_i | Pa(X_i))$$
로 결합 확률을 인수분해(factorize)한 모델을 말한다.
이 구조 덕분에 "부모 -> 자식" 순서로 샘플링하여 데이터를 생성할 수 있고, "증거 -> 관심 변수" 방향으로 효율적인 추론(inferecnce)을 수행할 수 있다.
2. 잠재 변수(Latent Variables)
잠재 변수란, 관측은 되지 않지만 모델링 과정에서 설명력을 높이기 위해 가정하고 포함하는 "숨겨진" 확률 변수를 말한다.
3. 변분 하한(Variational Lower Bound)
변분 하한 또는 ELBO(Evidence Lower Bound)란, 계산이 어려운 모델이 있고, 해당 모델의 정규화 상수가 $log p(x)$라고 하자. 변분 하한이란 계산이 어려운 모델의 정규화 상수(marginal likelyhood) $\log p(x)$를 직접 구하지 않고도 우회적으로 최대화할 수 있게 해 주는 목적 함수다. 즉 근사분포 $q$를 이용해 사후분포 추론과 모델 학습을 효율적이고 일관성 있게 수행하도록 해 주는 핵심 목적 함수다.
4. 주변 밀도(Marginal density)
주변 밀도란, 결합밀도에서 특정 변수에만 초점을 맞추고 다른 변수를 모두 없앤 확률밀도다. 예컨대 두 변수 $x$와 $z$의 결합밀도 $p_\theta(x,z)$가 있을 때, $x$의 주변밀도는
$$p_\theta(x)= \int p_\theta(x,z)\,\mathrm{d}z$$
와 같이 모든 가능한 $z$ 값을 적분하여 구한다.
이렇게 하면 “$x$가 관측될 확률(밀도)”만 남게 되어, $z$를 모를 때도 $x$의 분포를 알 수 있다.
5. 결합 밀도
결합밀도 $p_\theta(x,z)$는 $x$와 $z$가 동시에 발생할 확률(또는 밀도)을 나타내며,
$$p_\theta(x,z)=p_\theta(z)\,p_\theta(x\mid z).$$
따라서 $p_\theta(x)\neq p_\theta(x,z)$이며,
$p_\theta(x)$는 “모든 가능한 $z$에 대한 결합밀도의 합(적분)”으로 계산된다.
6. 기대값의 정의
7. Jensen 부등식
Jensen 부등식은 확률과 최적화, 수리통계에서 사용되는 기본적인 불등식으로, 함수의 볼록성(convexity) 과 기댓값(expectation) 사이의 관계를 나타낸다.
정의:
함수 $\varphi$가 정의역의 모든 구간에서 볼록(convex) 이고, 확률변수 $X$가 유한한 기댓값을 가질 때,
$$\varphi\bigl(\mathbb{E}[X]\bigr)\;\le\;\mathbb{E}\bigl[\varphi(X)\bigr].$$
반대로 $\varphi$가 오목(concave) 하면 부등호 방향이 뒤집혀 $\varphi(\mathbb{E}[X]) \ge \mathbb{E}[\varphi(X)]$ 가 성립한다.
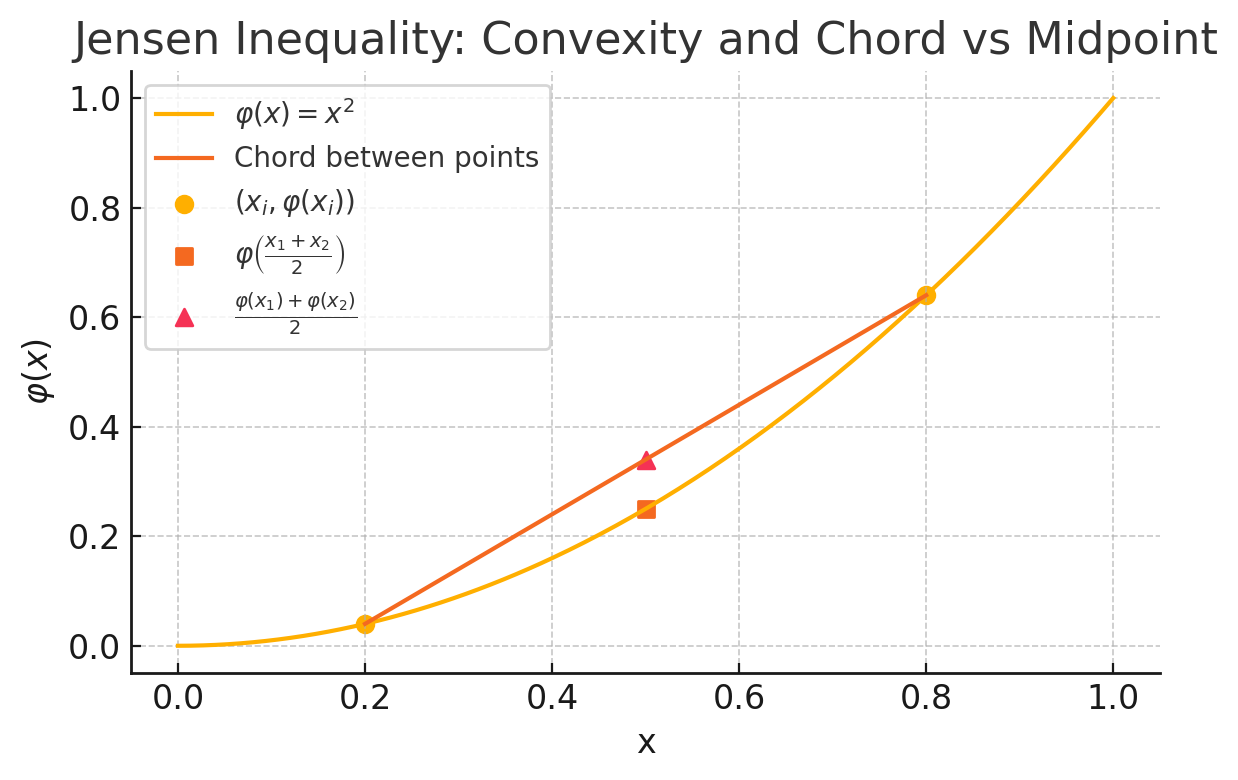
위 그래프는 두 점 $x_1=0.2$, $x_2=0.8$와 그 중점 $\frac{x_1+x_2}{2}$을 활용해 Jensen 부등식을 시각화한 것이다:
◆ 노랑 선: $\varphi(x)=x^2$ (볼록 함수)
◆ 빨강 선: 두 점 $(x_1,\varphi(x_1))$과 $(x_2,\varphi(x_2))$를 잇는 chord (선분)
◆ 노랑 동그라미: $(x_i,\varphi(x_i))$ (끝점 값)
◆ 주황 네모: $\varphi\bigl(\tfrac{x_1+x_2}{2}\bigr)$ (함수값 at midpoint)
◆ 빨강 세모: $\tfrac{\varphi(x_1)+\varphi(x_2)}{2}$ (chord at midpoint)
이 그래프에서 볼 수 있듯,
$$
\varphi\Bigl(\tfrac{x_1+x_2}{2}\Bigr)
\;\le\;
\tfrac{\varphi(x_1)+\varphi(x_2)}{2},
$$
즉 Jensen 부등식의 1차 간단한 형태가 성립함을 명확히 볼 수 있다.
예시:
$\varphi(t)=\log t$ 는 오목 함수이므로
$$\log\!\bigl(\mathbb{E}[Y]\bigr)\;\ge\;\mathbb{E}\bigl[\log Y\bigr]$$
와 같이 쓸 수 있으며, 변분 추론의 ELBO 유도에 사용된다.
8. $\|\cdot\|$ 기호는 벡터의 크기나 행렬의 크기를 나타내는 일반적인 표기법으로, “노름(norm)”이라고 부른다.
벡터 $v=(v_1,\dots,v_d)$에 대해, 유클리드 노름(2-노름)은
$$\|v\|_2 = \sqrt{v_1^2 + v_2^2 + \cdots + v_d^2}.$$
1-노름($\|v\|_1$)은 성분 절댓값 합: $\sum_i|v_i|$, 무한대 노름($\|v\|_\infty$)은 최대 절댓값: $\max_i|v_i|$ 등을 의미한다.
9. 몬테카를로 샘플 근사
몬테카를로 샘플 근사는 단순히 어떤 분포에서 랜덤 샘플들을 뽑아, 기대값을 근사한다는 것이다. 즉, 몬테카를로 샘플 근사는
$$
\mathbb{E}_{p(\varepsilon)}[\,f(g_\phi(\varepsilon,x))\,]
\approx \frac1L\sum_{l=1}^L f\bigl(g_\phi(\varepsilon^{(l)},x)\bigr)
$$
와 같이 $L$ 개의 샘플링을 통한 일반적인 수치적 기댓값 계산 방법을 가리킨다.
Abstract
본 논문은 연속 잠재 변수를 포함하는 유향 확률 모델에서 사후분포가 해석적으로 구할 수 없고, 동시에 대규모 데이터셋을 다뤄야 하는 상황에서도 효율적으로 추론과 학습을 수행하는 새로운 프레임워크를 제안한다. 먼저, 변분 하한(Evidence Lower Bound)을 재매개변수화(reparameterization)함으로써, 표준 확률적 경사법(stochastic gradient methods)으로 곧바로 최적화할 수 있는 편향 없는 하한 추정기를 도출하였다. 이 추정기는 미분 가능하고, 잠재 변수의 사후분포가 비해석적일 때에도 사용할 수 있어 범용성이 매우 높다. 둘째, 각 데이터 포인트마다 연속 잠재 변수가 존재하는 i.i.d 데이터셋에 대해서는, 제안된 하한 추정기를 이용해 인식 모델(recoginition model)을 학습시킴으로써 전통적인 반복적 추론 없이도 빠르게 사후 분포를 근사하도록 설계하였다. 구체적으로, 인식 모델은 입력 입력으로부터 잠재 변수의 분포 파라미터를 직접 예측하며, 이를 통해 매 샘플마다 별도의 MCMC나 변분 최적화를 수행할 필요를 제거한다. 그 결과, 모델 파라미터와 잠재 변수 분포를 동시에 학습하면서 추론 비용을 크게 줄이는 동시에, 대규모 데이터에서도 선형에 가까운 확장성을 달성한다. 제안 기법은 MNIST 등 벤치마크 실험에서 기존 방법들보다 빠른 수렴 속도와 우수한 생성 · 추론 성능을 모두 보여주었으며, 특히 대량의 데이터 처리 환경에서 효율성과 정확성을 동시에 확보할 수 있음을 실증했다.
1. Introduction
본 논문은 연속 잠재 변수나 파라미터를 가진 생성 모델에서, 사후분포 계산이 불가능할 때도 효율적으로 추론·학습할 수 있는 새로운 변분 베이지안 기법을 제안한다. 핵심은 (1) 변분 하한(ELBO)을 재매개변수화해 "미분 가능한, 편향 없는 확률적 추정량"(SGVB)을 얻는 것과, (2)i.i.d 데이터셋 상황에서 이 SGVB 추정량으로 학습되는 "인식(Recognition) 모델"을 도입해, 각 데이터에 대해 복잡한 반복 추론 없이 한 번의 샘플링만으로 사후분포를 빠르게 근사하는 AutoEncoding VB(AEVB) 알고리즘을 개발한 점이다. 결과적으로, MCMC나 복잡한 변분 최적화 없이도 표준 확률적 경사법으로 생성 · 추론 ·학습이 가능하며, 학습된 인식 모델은 분류 · 노이즈 제거 ·잠재 표현 · 시각화 등 다양한 응용에 활용될 수 있다.
2. Method
이 절에서 제시한 전략은, 연속 잠재 변수를 가지는 다양한 유향 그래프 모델에 대해 확률적(lower-bound) 목적 함수를 도출하는 것이다. 여기서 특히 다음과 같은 전형적인 상황에 집중하였다.
- i.i.d 데이터셋: 각 데이터에 대응하는 잠재 변수가 있고,
- 글로벌 파라미터에 대해 최대우도(ML) 또는 MAP 추정을 하고,
- 잠재 변수에 대해 변분 추론을 수행한다.
여기서 글로벌 파라미터도 변분 추론하기 위해서, 부록에 설명된 확장된 알고리즘을 사용하면 되고, 온라인 · 비정상(non-stationary) 환경(스트리밍 데이터)에 바로 적용할 수 있지만, 본 논문에서는 단순화를 위해 고정된 데이터셋만 가정하였다.

위 Figure1은 고려중인 유향 그래프 모델이다. 실선은 생성 모델을 나타내고, 점선은 계산 불가능한 사후확률의 변분 추론을 의미한다. 변분 추론 파라미터는 ELBO를 통해 생성 모델 파라미터와 공동으로 학습(최적화)된다. 실선의 생성모델은 전역 파라미터$\theta$ 하에서 잠재변수 $z$를 뽑고, 그 $z$를 조건으로 관측값 $x$를 생성하는 구조다. 점선인 변분 근사확률의 경우 실제 사후확률 $p_0(z|x)$가 계산 불가능하니, 인식(Recognition) 네트워크 $q_\pi$로 대신 근사(inference)하고, $\pi$는 $\theta$와 함께 ELBO를 통해 공동으로 학습된다. 마지막을 네모 박스 안에 들어있는 노드와 화살표는 해당 모형 구조가 독립 동형으로 N번 복제된다는 것을 의미한다.
내용을 조금 더 심도있게 파고들면, 잠재변수 $z$와 관측변수 $x$ 사이의 양방향 추론 구조를 나타내는 directed graphical model이다. 구체적으로, 실선 화살표 $z\!\to\!x$는 생성 모델 $p_\theta(x\mid z)$(decoder)에 대응하며, 점선 화살표 $x\!\to\!z$는 변분 근사 사후분포 $q_\phi(z\mid x)$(probabilistic encoder)를 의미한다. 실제로 관측되는 것은 오직 $x$뿐이므로, 진짜 posterior $p_\theta(z\mid x)$를 직접 계산할 수 없다. 따라서 $x\to z$ 경로에 해당하는 $q_\phi(z\mid x)$를 ELBO를 최대화하도록 학습하는데, 이때 ELBO의 음수를 loss로 설정하고 back-propagation을 통해 $\phi$를 갱신한다. 요약하면 첫째, 잠재변수 $z$는 관측되지 않으므로 가정(assume)하고, 둘째, 관측값 $x$를 입력(input)으로 하여 $q_\phi(z\mid x)$를 variational approximation으로 설정하며, 셋째, negative ELBO를 손실(loss)로 보아 back-propagation으로 $\phi$를 최적화한다. 이 과정을 통해 encoder $q_\phi$는 실제 posterior $p_\theta(z\mid x)$를 ELBO 기준으로 최적으로 근사하며, decoder $p_\theta(x\mid z)$는 latent $z$로부터 관측 $x$를 효과적으로 재구성하도록 상호 보완적으로 최적화된다.
2.1 Problem scenario
본 절에서는 다음과 같은 가정 하에, 연속 잠재변수가 포함된 생성 모델의 ㉮ 모수 학습(ML/MAP) ㉯ 잠재 변수 사후 추론 ㉰ 주변 확률 추론을 효율적으로 수행하기 위한 틀을 세운다.
우리가 관측할 수 있는 데이터 $X = {{x^i}}_{i=1}^N$ 가 실제로는 "보이지 않는" 연속 잠재 변수 $z$에 의해 생성된다는 가정을 세우고, 그 아래에서 발생하는 세 가지 핵심 과제 - ㉮ 생성 모델의 모두 $\theta$ 를 최대우도(또는 MAP)로 추정하는 문제, ㉯ 관측값 $x$에 대응하는 잠재 변수 $z$의 사후분포를 효과적으로 근사하는 문제, ㉰ 관측값 제체의 주변확률$p_0(x)$를 계산하는 문제 - 을 모두 "대규모 데이터"와 "도델 내 적분 · 사후분포가 닫힌 형태로 계산 불가능"이라는 어려움 속에서 어떻게 효율적으로 풀 것인지에 대한 툴을 제시한다.
우선 데이터 생성 과정을
㉮ 잠재 변수 $z$ 를 사전분포 $p_0(z)$로부터 뽑고,
㉯그 $z$를 조건으로 관측값 $x$도 가능도 $p_0(x | z)$로부터 생성한다.
는 두 단계 확률 과정으로 모델링한다. 그러나 실제로는 사전분포 모수 $\theta$도, 각 데이터에 대응하는 $z^i$값도 관측할 수 없기 때문에, 이론적으로 가장 자연스러운 "증거 $p_\theta(x)$ 최대화"나, 진정한 사후분포 $p_\theta(z|x)$활용"은 적분 · 정규화 상수 계산의 난제로 불가능하다.
2.2 The variational bound
이 절에서는 마진 가능도($log\, p_\theta(x))$를 변분 하한(ELBO) 으로 분해하고, 그 특징을 설명한다.
㉮ 마진 가능도의 분해
$$log\,p_\theta(x^t) = D_{KL}(q_\theta(z | x^t) || p_\theta(z|x^i)) + \mathcal{L}{(\theta,\phi;x^i)}$$
여기서 첫 항은 근사사후와 진짜 사후의 KL 발산이고,
둘째 항 $\mathcal{L}$이 바로 변분 하한이다.
이 분해는 $ \log p_\theta(x)$ 를 근사분포 $q_\phi(z\mid x)$ 를 도입해 풀어쓴 것에서 나온다. 구체적인 유도 과정은 다음과 같다.
1. 로그 주변 가능도에 근사분포 넣기
$q_\phi(z\mid x)$를 적분 안에 곱하고 나누어 넣는 것은 수학적 아이디어로, 실제 분포를 바꾸지는 않는다.
이렇게 하면 마치 $\mathbb{E}_{q_\phi}[\;\cdot\;]$ 형태로 적분을 표현할 수 있다.
$$
\log p_\theta(x)
= \log \int p_\theta(x,z)\,dz
= \log \int q_\phi(z\mid x)\,\frac{p_\theta(x,z)}{q_\phi(z\mid x)}\,dz.
$$
2. 로그 안의 적분을 기대값으로 바꾸기
$$
\log p_\theta(x)
= \log \mathbb{E}_{q_\phi(z\mid x)}\!\Bigl[\tfrac{p_\theta(x,z)}{q_\phi(z\mid x)}\Bigr].
$$
3. Jensen 부등식 적용
$\log\mathbb{E}[\,\cdot\,]\ge \mathbb{E}[\log\,\cdot\,]$ 를 써서,
$$
\log p_\theta(x)
\;\ge\;
\mathbb{E}_{q_\phi(z\mid x)}\Bigl[\log p_\theta(x,z) - \log q_\phi(z\mid x)\Bigr]
= \mathcal{L}(\theta,\phi;x).
$$
4. 정확한 등식으로 복원
실제로는 Jensen 부등식을 거꾸로 풀어,
$$
\log p_\theta(x)
= \underbrace{\mathbb{E}_{q_\phi}[\log p_\theta(x,z)-\log q_\phi(z\mid x)]}_{\mathcal{L}}
+ \underbrace{\mathbb{E}_{q_\phi}\bigl[\log q_\phi(z\mid x)-\log p_\theta(z\mid x)\bigr]}_{D_{KL}(q_\phi\|p_\theta)}.
$$
여기서 두번째 항이
$\;D_{KL}(q_\phi(z\mid x)\,\|\,p_\theta(z\mid x))\ge0$ 이므로,
$\mathcal{L}$ 이 바로 “$\log p_\theta(x)$ 의 하한(lower bound)” 가 됩니다.
즉 “로그 주변 가능도”를
$$
\log p_\theta(x)
= D_{KL}\bigl(q_\phi(z\mid x)\|p_\theta(z\mid x)\bigr)
+ \mathcal{L}(\theta,\phi;x)
$$
로 나누는 것은, 위 1~4단계를 통해 수학적으로 증명되는 표준적인 변분추론 기법이다.
[질문]
Figure 1에서 “근사사후”와 “실제사후”는 무엇을 가리키며, “변분 하한”은 어떤 부분을 의미하는가?
[답변]
근사사후 $q_\phi(z\mid x)$과 실제사후 $p_\theta(z\mid x)$ 는 모두 잠재변수 $z$ 와 관련된 분포다. 실선 화살표로 그려진 $p_\theta(z)$→$z$와 $z$→$x$가 결합된 실제 사후 $p_\theta(z\mid x)$ 이고,점선 화살표 $x$→$z$가 인식 모델 $q_\phi(z\mid x)$ 로서 실제 사후를 근사하는 분포다. 변분 하한(ELBO) 은 이 점선 화살표, 즉 $q_\phi(z\mid x)$를 통해 정의된 하한 식 전체를 가리킨다.그림에서 점선으로 표현된 $x\to z$의 경로와, ELBO를 최적화하는 과정을 의미하며, 이 $q_\phi$ 자체를 ELBO를 최대화하는 방식으로 학습해 얻은 분포다. 즉, ELBO(변분 하한) 를 도출하고 최적화하는 과정을 통해 점선으로 표시된 근사사후분포 $q_\phi(z\mid x)$ 의 파라미터 $\phi$ 를 구하게 되는 것이 핵심이다.
1. $ \log p(x) $의 의미
- $ p(x) $는 데이터 $ x $가 실제로 발생할 확률, 즉 관측된 데이터가 생성될 확률분포다.
- 이 값은 직접 계산하기 매우 어렵거나 불가능한 경우가 많다.
2. 변분 추론의 핵심 분해식
- 실제로 구하기 어려운 $ \log p(x) $를 다음과 같이 분해할 수 있다:
$$
\log p(x) = \underbrace{\text{ELBO}}_{\text{Evidence Lower Bound}} + \underbrace{\text{KL}(q(z|x) \| p(z|x))}_{\text{KL divergence}}
$$
- 여기서,
- ELBO (변분 하한): 우리가 직접 계산 및 최적화할 수 있는 하한 (lower bound)이다.
- KL divergence: 근사 분포 $ q(z|x) $와 실제 후방분포 $ p(z|x) $ 사이 차이를 나타내는 값으로, 항상 0 이상이다.
3. 왜 이 분해가 중요한가?
- KL divergence는 항상 0 이상이므로, ELBO는 $ \log p(x) $에 대한 하한값이다. 즉,
$$
\log p(x) \geq \text{ELBO}
$$
- 우리는 직접 $ p(z|x) $를 계산할 수 없으니, 근사 분포 $ q(z|x) $를 정의하고 ELBO를 최대화함으로써
- 최적 근사 posterior를 찾고,
- 간접적으로 $ \log p(x) $를 높이는 방향으로 학습을 진행한다.
4. ELBO를 최대화하는 것이 목표
- ELBO는 두 가지 성분으로 구성된다:
- 재구성 손실 (입력 데이터와 출력 데이터 간 차이)
- KL divergence (근사 posterior와 사전 분포 간 차이)
- 이를 최적화하는 것이 VAE 학습의 핵심이며, 이 과정에서 역전파(backpropagation)가 사용된다.
결론
- $ \log p(x) $를 직접 알기 어렵기 때문에, VAE는 근사 posterior $ q(z|x) $를 도입하고 ELBO를 최대화하여 $ \log p(x) $를 간접적으로 표현 및 최적화한다.
㉯ 변분 하한(ELBO)의 정의
√ 일반형
$$\mathcal{L}(\theta,\phi; x)= \mathbb{E}_{q_\phi(z\mid x)}\bigl[\log p_\theta(x,z) - \log q_\phi(z\mid x)\bigr].$$
√ KL 분해형
$$\mathcal{L}(\theta,\phi; x)= -D_{KL}\bigl(q_\phi(z\mid x)\|p_\theta(z)\bigr)+ \mathbb{E}_{q_\phi(z\mid x)}\bigl[\log p_\theta(x\mid z)\bigr].$$
√ 최적화 목표
ELBO $\mathcal{L}(\theta,\phi)$를 $\theta$와 $\phi$ 모두에 대해 극대화하여, $\log p_\theta(x)$를 간접적으로 최대화하고 $q_\phi$를 올바른 사후로 가깝게 만든다.
√ 변분 파라미터 φ의 경사 문제
näive Monte Carlo 추정기$\nabla_\phi\mathbb{E}_{q_\phi}[f(z)]\approx \frac1L\sum f(z^{(l)})\nabla_\phi\log q_\phi(z^{(l)})$ 는 분산이 매우 커 실용적이지 않다.
이로써 ELBO의 정의와, φ에 대한 näive 경사 추정 방식이 비효율적임을 보여준다.
2.3 The SGVB estimator and AEVB algorithm
2.3 절에서는 2.2절에서 일반형으로 정의한 변분 하한
$$\mathcal{L}(\theta, \phi; x) =\mathbb{E}_{q_\phi(z\mid x}\bigl[\log p_\theta(x,z) - \log q_\phi(z\mid x)]\bigr]$$
을 실제로 계산하고, 그에 대한 $\theta, \phi$ 의 미분을 가능케 하는 Stochastic Gradient Variational Bayes(SGVB) 추정기와, 이를 미니배치 학습으로 확장한 Auto-Encoding VB(AEVB) 알고리즘을 제안한다.
우선, 근사 사후분포 $q_\phi(z\mid x)$에서 직접 $z$를 샘플링하면
$$
\nabla_\phi\,\mathbb{E}_{q_\phi(z\mid x)}[f(z)]
\approx \tfrac1L\sum_{l=1}^L f\bigl(z^{(l)}\bigr)\,\nabla_\phi\log q_\phi\bigl(z^{(l)}\mid x\bigr),
$$
와 같은 고전적인 Monte Carlo 경사 추정은 분산이 지나치게 크기때문에 실용적이지 않다.
★ 고전적 Monte Carlo 경사 추정의 분산이 큰 이유
고전적 Monte Carlo 경사 추정기$$\hat g \;=\;\frac{1}{L}\sum_{l=1}^L Y^{(l)}, \quad Y^{(l)}=f\bigl(z^{(l)}\bigr)\,\nabla_\phi\log q_\phi\bigl(z^{(l)}\mid x\bigr),\quad z^{(l)}\sim q_\phi(z\mid x)$$의 분산이 큰 이유를 다음과 같이 자세히 유도한다.
1. 표본평균의 분산 공식
독립적인 $Y^{(l)}$에 대해
$$\mathrm{Var}[\hat g]= \mathrm{Var}\Bigl[\tfrac1L\sum_{l}Y^{(l)}\Bigr]= \tfrac1{L^2}\sum_{l}\mathrm{Var}[Y^{(l)}]
= \tfrac1L\,\mathrm{Var}[Y],$$
여기서 $Y$는 임의의 한 샘플 $Y^{(l)}$와 동일한 분포를 가진다.
2. $Y$의 분산 전개
$$\mathrm{Var}[Y]= \mathbb{E}[Y^2] \;-\;\bigl(\mathbb{E}[Y]\bigr)^2.$$
$Y = f(z)\,\nabla_\phi\log q_\phi(z\mid x)$이므로
2.1. $\mathbb{E}[Y]$
$$\mathbb{E}[Y]= \int q_\phi(z\mid x)\,\bigl[f(z)\,\nabla_\phi\log q_\phi(z\mid x)\bigr]\,\mathrm{d}z.$$
여기서 $\nabla_\phi\log q_\phi(z\mid x)$를 사용한 꼼수로,
$$
\int q_\phi\,f(z)\,\nabla_\phi\log q_\phi =
\int f(z)\,\nabla_\phi q_\phi(z\mid x)\,\mathrm{d}z
= \nabla_\phi\int q_\phi(z\mid x)\,f(z)\,\mathrm{d}z
= \nabla_\phi\,\mathbb{E}_{q_\phi}[f(z)].
$$
㉮ 첫 번째 등호: $\nabla_\phi\log q_\phi = \frac{\nabla_\phi q_\phi}{q_\phi}$
㉯ 두 번째 등호: Leibniz 법칙으로 미분·적분 교환
결국
$$
\mathbb{E}[Y] = \nabla_\phi\,\mathbb{E}_{q_\phi}[f(z)].
$$
2.2. $\mathbb{E}[Y^2]$
$$
\mathbb{E}[Y^2]
= \int q_\phi(z\mid x)\,\bigl[f(z)\,\nabla_\phi\log q_\phi(z\mid x)\bigr]^2\,\mathrm{d}z
= \int q_\phi(z\mid x)\,f(z)^2\,\bigl\|\nabla_\phi\log q_\phi(z\mid x)\bigr\|^2\,\mathrm{d}z
= \mathbb{E}_{q_\phi}\!\bigl[f(z)^2\,\|\nabla_\phi\log q_\phi(z\mid x)\|^2\bigr].
$$
㉮ 곱의 제곱은 각 항의 제곱 곱으로 분해
㉯ 노름(norm) $\|\cdot\|$ 표기를 사용해 다차원 $\phi$일 때도 일반화
따라서
$$
\mathrm{Var}[Y]
= \mathbb{E}_{q_\phi}\!\bigl[f(z)^2\,\|\nabla_\phi\log q_\phi(z\mid x)\|^2\bigr]
\;-\;\|\nabla_\phi\,\mathbb{E}_{q_\phi}[f(z)]\|^2.
$$
3. 표본평균 분산 결합
$$
\mathrm{Var}[\hat g]
= \tfrac1L\,\mathrm{Var}[Y]
= \tfrac1L\Bigl(
\mathbb{E}_{q_\phi}\!\bigl[f(z)^2\,\|\nabla_\phi\log q_\phi(z\mid x)\|^2\bigr]
- \|\nabla_\phi\,\mathbb{E}_{q_\phi}[f(z)]\|^2
\Bigr).
$$
4. 분산이 큰 이유 요약
$\mathbb{E}[Y^2]$ 항은 $f(z)^2$와 $\|\nabla_\phi\log q_\phi\|^2$의 곱의 기댓값이므로, 두 요소 모두 샘플마다 크게 변동하면 기댓값도 크게 증가한다.결과적으로 $\mathrm{Var}[Y]$가 커지고, $\tfrac1L$ 배율에도 불구하고 충분히 작은 분산을 얻기 위해선 $L$을 비현실적으로 크게 해야 한다. 이 때문에 “$\nabla_\phi\log q_\phi$” 항을 제거하는 재매개변수화가 필요하다.
이를 해결하기 위해 재매개변수화 트릭을 도입하여,
$$z\sim q_\phi (z \mid x) \quad\Longrightarrow\quad z=g_\phi(\varepsilon, x),\;\varepsilon \sim p(\varepsilon),$$
와 같이 잠재변수 샘플링 과정을 미분 가능한 결정론적 함수 $g_\phi$와 표준 잡음 $\varepsilon$의 결합으로 바꾼다. 이렇게 하면$\nabla_\phi f\bigl(g_\phi(\varepsilon,x)\bigr)$ 를 자동미분으로 안정적으로 구할 수 있어, 경사의 분산이 현격히 줄어들고 학습이 빠르고 견고해진다.
★ 재매개변수가 미분을 용이하게 하는 이유
나이브한 Monte Carlo 경사 추정기는 근사사후분포 $q_\phi(z\mid x)$에 대한 기대값의 그래디언트를 계산할 때, 직접적으로 분포 밀도 함수 내부에 들어 있는 파라미터 $\phi$를 미분해야 한다는 문제를 안고 있다. 구체적으로,
$$
\nabla_{\phi}\,\mathbb{E}_{q_\phi(z\mid x)}[f(z)]
=\nabla_{\phi}\int q_\phi(z\mid x)\,f(z)\,\mathrm{d}z
=\int \nabla_{\phi}\,q_\phi(z\mid x)\,f(z)\,\mathrm{d}z
=\int q_\phi(z\mid x)\,f(z)\,\nabla_{\phi}\log q_\phi(z\mid x)\,\mathrm{d}z.
$$
이 과정에서 각 샘플 $z^{(l)}$마다 $f(z^{(l)})\times\nabla_{\phi}\log q_\phi(z^{(l)}\mid x)$를 곱해 평균을 내는데, 이 곱의 값이 샘플마다 크게 달라져 경사 분산이 매우 커 학습이 불안정해진다( ★ 고전적 Monte Carlo 경사 추정의 분산이 큰 이유 참조).
이러한 불안정성을 해소하기 위해 도입된 것이 재매개변수화 트릭이다. 여기서는 샘플 $z$ 자체를 $q_\phi$에서 직접 뽑는 대신, 표준 잡음 변수 $\varepsilon\sim p(\varepsilon)$를 먼저 샘플링한 뒤, 미분 가능한 함수 $g_\phi$를 통해
$$
z = g_\phi(\varepsilon, x)
$$
로 변환한다. 이 방식으로 $z$를 표현하면, 분포 밀도 $q_\phi$는 $g_\phi$와 $p(\varepsilon)$의 결합으로 재표현되고, 파라미터 $\phi$는 오직 $g_\phi$의 내부에만 등장하게 된다. 그 결과, 관심 있는 기대값
$$
\mathbb{E}_{q_\phi(z\mid x)}[f(z)]
=\mathbb{E}_{p(\varepsilon)}\bigl[f\bigl(g_\phi(\varepsilon,x)\bigr)\bigr]
$$
의 그래디언트는
$$
\nabla_{\phi}f\bigl(g_\phi(\varepsilon,x)\bigr)
=\frac{\partial f}{\partial z}\Big|_{z=g_\phi(\varepsilon,x)}\;\nabla_{\phi}g_\phi(\varepsilon,x)
$$
와 같이 연쇄법칙(chain rule) 한 번으로 계산할 수 있다. 이 방식은 “$\nabla_\phi\log q_\phi$” 항을 제거하여 경사 분산을 현저히 낮추고, 표준적인 자동미분 도구만으로도 안정적인 학습이 가능하게 해 준다.
★ Monte Carlo 식 변형 증명
Monte Carlo 방법으로 변분 하한의 기댓값을 계산할 때, 원래 우리는 다음과 같이 근사사후분포 $q_\phi(z\mid x)$에 대한 기댓값을 직접 적분으로 표현한다:
$$
\mathbb{E}_{q_\phi(z\mid x)}[f(z)]
= \int q_\phi(z\mid x)\,f(z)\,\mathrm{d}z.
$$
그러나 이 식을 그대로 사용하면 $q_\phi$ 내부에 있는 파라미터 $\phi$를 미분할 때 분산이 큰 “$\nabla_\phi\log q_\phi$” 항이 등장하게 된다. 이를 완화하기 위해, 우리는 $z$를 직접 $q_\phi$에서 샘플링하는 대신, 재매개변수화를 수행합니다. 구체적으로는 표준 잡음 변수 $\varepsilon$를 먼저 $p(\varepsilon)$에서 샘플링하고,
※$q_\phi(z \mid x)$는 관측값 $x$가 주어졌을 때, 잠재변수 $z$가 어떻게 분포하는지 나타내는 확률분포이고, 이 분포의 모양(평균 · 분샨)을 결정ㄹ하는 학습 가능한 값들이 $\phi$ 라는 의미다.
$$
z = g_\phi(\varepsilon, x)
$$
와 같이 결정론적 함수 $g_\phi$를 통해 $z$를 생성한다. 이때 $g_\phi$를 적절히 정의하면, 확률변수 변환 규칙에 따라
$$
q_\phi(z\mid x)\,\mathrm{d}z
= p(\varepsilon)\,\mathrm{d}\varepsilon,
$$
즉 $z$에 대한 적분을 $\varepsilon$에 대한 적분으로 바꿀 수 있게 된다. 따라서 원래의 기댓값은
$$
\int q_\phi(z\mid x)\,f(z)\,\mathrm{d}z
= \int p(\varepsilon)\,f\bigl(g_\phi(\varepsilon,x)\bigr)\,\mathrm{d}\varepsilon
= \mathbb{E}_{p(\varepsilon)}\bigl[f\bigl(g_\phi(\varepsilon,x)\bigr)\bigr]
$$
로 재표현된다. 마지막으로, $p(\varepsilon)$로부터 i.i.d. 샘플 $\{\varepsilon^{(l)}\}_{l=1}^L$을 뽑아 기댓값을 샘플 평균으로 근사하면,
$$
\mathbb{E}_{p(\varepsilon)}\bigl[f(g_\phi(\varepsilon,x))\bigr]
\approx \frac{1}{L}\sum_{l=1}^L f\bigl(g_\phi(\varepsilon^{(l)},x)\bigr).
$$
이 과정을 통해, 원래 $q_\phi$에 대한 기댓값 적분이 “잡음 변수 $\varepsilon$에 대한 기댓값”으로 바뀌며, 그 결과 파라미터 $\phi$의 미분이 $g_\phi$ 내부의 연쇄 법칙만으로 처리 가능한 형태가 되어, 경사 분산을 크게 줄인다는 점을 보였다.
여기까지 글을 읽고 든 생각은 다음과 같다. 저자는 연속 잠재변수를 포함하는 복잡한 확률 생성 모델을 확률적 경사법으로 학습·추론하기 위해, 변분 하한(ELBO)을 Monte Carlo 방식으로 근사할 때 발생하는 높은 분산 문제를 해결하는 것을 주된 목표로 삼았다. 구체적으로, 근사사후분포 $q_\phi(z\mid x)$의 파라미터 $\phi$에 대한 그래디언트를 계산하면 “$\nabla_\phi\log q_\phi(z\mid x)$” 항이 샘플마다 크게 변동하여 학습이 불안정해진다. 이에 저자는 잠재변수 $z$를 직접 샘플링하는 대신, 표준 잡음 변수 $\varepsilon\sim p(\varepsilon)$를 먼저 뽑고 결정론적 함수 $g_\phi(\varepsilon,x)$를 통해 $z$를 생성하는 재매개변수화 트릭을 도입하였다. 이 방법을 통해 $\phi$는 $g_\phi$ 내부에서만 등장하게 되고, 그래디언트는 체인룰 한 번으로 깔끔하게 계산되므로 분산이 현저히 줄어들어, 안정적이고 효율적인 SGVB 추정기 및 AEVB 알고리즘을 구현하는 기반을 마련하고자 한 것이다.
★ 내용 추가
Leibniz 법칙(파라미터 미분-적분 교환 정리)에 따라, 다음 두 조건이 만족되면
$$\nabla_\phi \int g(z,\phi)\,\mathrm{d}z= \int \nabla_\phi\,g(z,\phi)\,\mathrm{d}z$$
와 같이 ∇_φ 연산자를 적분 안으로 옮길 수 있다.
㉮ 적분 범위가 φ에 의존하지 않을 것. 즉, $\int_{a}^{b} g(z,\phi)\,dz$ 형태로, 상·하한 $a,b$가 φ와 무관해야 한다.
㉯ 적분할 함수 $g(z,\phi)$가 φ에 대해 연속 미분 가능하고, 지배 수렴 정리를 사용할 수 있을 만큼 적분과정이 수렴해야 합니다.
여기서 “φ가 z에 무관할 때만 가능”하다는 오해가 있는데,실제 요건은 “적분 구간이 φ에 의존하지 않아야 한다”는 것이고,
integrand인 $g(z,\phi)$ 내부에 φ가 들어 있어도 괜찮다. 다시 말해서,
$$
g(z,\phi)=q_\phi(z\mid x)\,f(z)
$$
처럼 φ가 분포밀도 안에 포함되어 있어도, 위 두 조건만 만족하면 ∇\_φ를 적분 안으로 안전히 옮길 수 있다.
다음 두 가지 간단한 예시를 보시면 이해가 더 쉬울 것이다.
예시 1: 적분 구간은 고정, integrand에 φ 포함
정의: $H(\phi)=\int_{0}^{1} \underbrace{\phi\,z}_{g(z,\phi)}\,dz.$
여기서 ㉮ 적분 구간 $[0,1]$은 φ와 전혀 무관, ㉯ integrand $g(z,\phi)=\phi\,z$ 내부에 φ가 들어 있음
직접 계산
$$H(\phi)=\phi\int_{0}^{1} z\,dz = \phi\cdot\frac12.$$
* 미분-적분 교환
1. 외부에서 한 번에 미분:
$$\displaystyle \nabla_\phi H=\frac12.$$
2. Leibniz 법칙 적용:
$$
\nabla_\phi H
= \nabla_\phi\int_{0}^{1}\phi\,z\,dz
= \int_{0}^{1}\nabla_\phi\bigl(\phi\,z\bigr)\,dz
= \int_{0}^{1}z\,dz
= \tfrac12.
$$
→ 둘 다 일치
결론: integrand에 φ가 있어도, 적분 범위가 φ에 의존하지 않으면
$\nabla_\phi$를 자유롭게 적분 안으로 넣을 수 있다.
예시 2: 적분 구간이 φ에 의존할 때 문제
정의:$K(\phi)=\int_{0}^{\phi} z\,dz.$
여기서는 ㉮ upper limit가 φ에 의존, ㉯ integrand은 φ와 독립 ($g(z,\phi)=z$)
1. 외부에서 미분 (Fundamental Theorem of Calculus):
$$\frac{d}{d\phi}K(\phi)= \frac{d}{d\phi}\int_{0}^{\phi}z\,dz= \phi.$$
2. “교환” 시도:
$$\displaystyle \nabla_\phi\bigl(\int_0^\phi z\,dz\bigr)\overset{?}{=}\int_0^\phi \nabla_\phi z\,dz = \int_0^\phi 0\,dz=0,$$
틀린 결과!
이제 ELBO를 Monte Carlo 샘플로 근사하여, 일반형 SGVB 추정기를 정의한다:
$$
\widetilde{\mathcal{L}}_A(\theta,\phi;x)
=\frac1L\sum_{l=1}^L\Bigl[\log p_\theta\bigl(x,z^{(l)}\bigr)
-\log q_\phi\bigl(z^{(l)}\mid x\bigr)\Bigr],
\quad
z^{(l)}=g_\phi(\varepsilon^{(l)},x),\;\varepsilon^{(l)}\sim p(\varepsilon).
$$
추가로, $\mathrm{KL}(q_\phi(z\mid x)\|p_\theta(z))$ 항을 해석적으로 계산할 수 있을 때에는 KL 통합형 SGVB
$$
\widetilde{\mathcal{L}}_B(\theta,\phi;x)
=-D_{KL}\bigl(q_\phi(z\mid x)\,\|\,p_\theta(z)\bigr)
+\frac1L\sum_{l=1}^L\log p_\theta\bigl(x\mid z^{(l)}\bigr)
$$
을 사용함으로써, 샘플 추정이 필요한 재구성 오차 항만 남겨 경사 분산을 더욱 낮출 수 있다.
마지막으로 이 두 추정기를 미니배치 학습에 적용한 것이 AEVB 알고리즘(알고리즘 1)이다. 전체 데이터셋 크기 $N$에서 무작위로 $M$개를 뽑은 미니배치 $\{x^{(i)}\}_{i=1}^M$마다, 각 데이터에 대해 $L$개의 잡음 샘플 $\{\varepsilon^{(i,l)}\}$을 생성하고,
$$
\widetilde{\mathcal{L}}_M
=\frac{N}{M}\sum_{i=1}^M \widetilde{\mathcal{L}}(\theta,\phi;x^{(i)})
$$
로 미니배치 ELBO를 추정한다.
그다음 $\theta,\phi$에 대한 경사 $\nabla_{\theta,\phi}\widetilde{\mathcal{L}}_M$를 SGD나 Adagrad 같은 확률적 최적화 기법으로 업데이트하며, 보통 실험에서는 $L=1$, $M=100$ 정도로도 안정적인 수렴을 보인다.
이 과정을 통해 VAE는 한 번의 샘플링과 미니배치 확률적 경사만으로, 복잡한 적분이나 반복적 MCMC 없이도 생성 모델과 인식 모델을 동시에 효율적으로 학습할 수 있다.
★ 재매개변수화로 ELBO 기댓값을 치환하고, Monte Carlo 근사로 넘어가는 과정
변분 하한(ELBO)은
$$
\mathcal{L}(\theta,\phi;x)
= \mathbb{E}_{q_\phi(z\mid x)}\bigl[\log p_\theta(x,z)-\log q_\phi(z\mid x)\bigr]
$$
로 정의되지만, 이 기댓값을 직접 $q_\phi$에서 샘플링해 계산하면 $\nabla_\phi\log q_\phi(z\mid x)$ 항으로 인해 경사의 분산이 매우 커진다. 이를 완화하기 위해 재매개변수화 트릭을 적용한다..
㉮ 재매개변수화
잠재 변수 $z$를
$$z = g_\phi(\varepsilon,x),\quad \varepsilon\sim p(\varepsilon)$$
와 같이 “표준 잡음” $\varepsilon$에서 결정론적으로 생성하도록 바꿉니다. 이때 $g_\phi$는 $\varepsilon\leftrightarrow z$ 1:1 대응이며, 야코비안 $\det\bigl(\tfrac{\partial z}{\partial\varepsilon}\bigr)=1$이 되도록 한다.
㉯ 변수 치환
확률변수 변환 법칙에 따라
$$q_\phi(z\mid x)\,\mathrm{d}z = p(\varepsilon)\,\mathrm{d}\varepsilon.$$
따라서 ELBO 기댓값 적분을
$$\int q_\phi(z\mid x)\,h(z)\,\mathrm{d}z= \int p(\varepsilon)\,h\bigl(g_\phi(\varepsilon,x)\bigr)\,\mathrm{d}\varepsilon= \mathbb{E}_{p(\varepsilon)}\bigl[h(g_\phi(\varepsilon,x))\bigr].$$
㉰ Monte Carlo 근사
$\varepsilon^{(l)}\sim p(\varepsilon)$ i.i.d. 샘플을 $L$개 뽑아,
$$\mathbb{E}_{p(\varepsilon)}\bigl[h(g_\phi(\varepsilon,x))\bigr]\approx \frac{1}{L}\sum_{l=1}^L h\bigl(g_\phi(\varepsilon^{(l)},x)\bigr).$$
㉱ SGVB 추정기
위 $h(\varepsilon)$에 $h(\varepsilon)=\log p_\theta\bigl(x,g_\phi(\varepsilon,x)\bigr) -\log q_\phi\bigl(g_\phi(\varepsilon,x)\mid x\bigr)$ 를 대입하면,
$$\widetilde{\mathcal{L}}_A(\theta,\phi;x)= \frac{1}{L}\sum_{l=1}^L\Bigl[\log p_\theta\bigl(x,z^{(l)}\bigr)-\log q_\phi\bigl(z^{(l)}\mid x\bigr)\Bigr],$$
where $z^{(l)}=g_\phi(\varepsilon^{(l)},x)$.
이 과정을 통해, ELBO 기댓값은 “$q_\phi$에 대한 적분”에서 “$p(\varepsilon)$에 대한 적분”으로 치환되고, 다시 유한 샘플의 평균으로 근사되어 분산이 낮고 자동미분이 가능한 SGVB 추정기로 귀결된다.
많은 실제 모델에서 근사사후분포 $q_\phi(z\mid x)$와 사전분포 $p_\theta(z)$ 간의 KL 발산은 가우시안 대 가우시안처럼 해석적으로 계산할 수 있다. 이 경우, 샘플링이 필요한 것은 오직 재구성 항 $\mathbb{E}_{q_\phi(z\mid x)}[\log p_\theta(x\mid z)]$뿐이므로, KL 발산을 닫힌 식으로 그대로 두고 재구성 항만 몬테카를로 근사하여 분산을 크게 줄인 SGVB 추정기를 만들 수 있습니다. 이 “KL 통합형” 추정기는
$$
\widetilde{\mathcal{L}}_B(\theta,\phi;x)
= -D_{KL}\bigl(q_\phi(z\mid x)\,\|\,p_\theta(z)\bigr)
+ \frac{1}{L}\sum_{l=1}^L \log p_\theta\bigl(x\mid z^{(l)}\bigr),
\tag{★} $$
$\,z^{(l)}=g_\phi(\varepsilon^{(l)},x)\;,\;\varepsilon^{(l)}\sim p(\varepsilon)$)로 표현되며, KL 항은 인식 모델을 사전분포에 가깝게 정규화하는 역할을, 재구성 항은 오토인코더의 재구성 오류를 측정하는 역할을 한다. 이 방식은 일반형 SGVB보다 경사 분산이 낮아 보다 안정적인 학습을 가능하게 한다.
여기서 여러 개의 데이터 $X=\{x^{(i)}\}_{i=1}^N$에 대해, 전체 증거 하한 $\sum_{i=1}^N\mathcal{L}(\theta,\phi;x^{(i)})$을 직접 계산하는 대신, 매 반복마다 크기 $M$의 미니배치 $X_M\subset X$를 무작위로 뽑아
$$
\widetilde{\mathcal{L}}_M(\theta,\phi)
= \frac{N}{M}\sum_{i\in X_M}\widetilde{\mathcal{L}}(\theta,\phi;x^{(i)})
$$
로 전체 ELBO를 확률적으로 추정한다. 이때 데이터포인트당 샘플 수 $L$는 보통 1로 두고, 미니배치 크기 $M\approx100$을 사용해도 안정적으로 수렴한다. 이렇게 구한 $\widetilde{\mathcal{L}}_M$에 대해 $\theta$와 $\phi$의 경사 $\nabla_{\theta,\phi}\widetilde{\mathcal{L}}_M$를 계산하여, SGD나 Adagrad 같은 확률적 최적화 알고리즘으로 파라미터를 갱신하면, 전체 데이터에 대한 하한을 효율적으로 최대화할 수 있다.
다시 한 번 정리하면, AEVB 알고리즘에서는 전체 데이터 $N$개를 매번 전부 사용하지 않고, 매 반복마다 무작위로 $M$개의 샘플만 골라 “미니배치”를 구성한다. 이 미니배치에 속한 각 데이터 $x^{(i)}$에 대해 SGVB 추정기 $\widetilde{\mathcal{L}}(\theta,\phi;x^{(i)})$를 계산한 뒤, 이들을 모두 합산하고 전체 데이터 크기에 맞춰 $\tfrac{N}{M}$을 곱한다. 이렇게 얻은 값이 바로 전체 데이터에 대한 ELBO 하한의 확률적 추정치 $\widetilde{\mathcal{L}}_M(\theta,\phi)$ 이다. 그다음 이 추정치에 대해 생성 모델 파라미터 $\theta$와 인식 모델 파라미터 $\phi$의 기울기를 계산하고, SGD나 Adagrad와 같은 확률적 최적화 기법으로 한 번에 업데이트한다. 이 과정을 반복함으로써, 모든 데이터를 매번 처리하지 않아도 전체 ELBO를 효율적으로 최대화할 수 있고, 계산 비용과 메모리 사용량을 크게 줄이면서도 안정적인 수렴을 달성할 수 있다.
이제 식 (★)을 보면 VAE가 오토인코더 구조와 정확히 대응됨을 알 수 있다. 인식 모델 $g_\phi$는 입력 $x$와 노이즈 $\varepsilon$를 결합해 잠재 코드 $z$를 샘플링하는 인코더 역할을 하며,
㉮ 첫 번째 KL 항 $-D_{KL}(q_\phi(z\mid x)\,\|\,p_\theta(z))$ 은 잠재공간을 사전분포에 맞춰 정규화(regularizer) 하는 역할을 하고, ㉯ 두 번째 재구성 항 $\mathbb{E}_{q_\phi}[\log p_\theta(x\mid z)]$ 은 디코더 $p_\theta(x\mid z)$가 $z$로부터 원본 $x$를 얼마나 잘 재구성하는지를 측정하는 음의 재구성 오류다.
따라서 VAE의 목적함수는 “인코더 + KL 정규화”와 “디코더 + 재구성 손실”을 한데 묶은, 확률적 오토인코더로 볼 수 있다.
2.4 The reparameterization trick
본 절에서는, 근사사후분포 $q_\phi(z\mid x)$로부터 샘플을 얻고 그에 대한 기댓값의 경사를 계산할 때 발생하는 높은 분산 문제를 해결하기 위해 재매개변수화 트릭을 도입하며, 그 핵심 아이디어는 다음과 같다.
구체적으로, 연속 잠재변수 $z$가 $z\sim q_\phi(z\mid x)$ 를 따른다면, 이를
$$z = g_\phi(\varepsilon, x)$$
라는 결정론적 함수와, 분포가 독립적인 보조 잡음 $\varepsilon\sim p(\varepsilon)$의 조합으로 표현할 수 있다. 여기서 $g_\phi$는 파라미터 $\phi$로 정의된 벡터값 함수다. 즉, “$g_\phi$는 $\varepsilon$과 $x$를 입력으로 받아 잠재변수 $z$를 출력하는 결정론적 함수이며, 그 구체적인 동작 방식(특히 가중치나 편향 등)을 파라미터 $\phi$가 정의한다”라고 말할 수 있다. 이 단순한 변환을 통해, 이후 Monte Carlo 추정의 미분이 가능해지도록 기댓값 연산을 재구성할 수 있다.
★ 벡터값 함수
여기서 “벡터값 함수”라는 말은, $g_\phi$가 하나의 숫자를 내놓는 스칼라 함수가 아니라 여러 차원의 출력을 한꺼번에 생성한다는 뜻이다. 즉, 보조 잡음 $\varepsilon\in\mathbb{R}^d$와 관측값 $x\in\mathbb{R}^m$을 입력받아 잠재변수 $z\in\mathbb{R}^k$를 동시에 반환하는 함수가 바로 $g_\phi$ 이다.
또 “파라미터 $\phi$로 정의된다”는 것은, 이 함수의 구체적인 동작 방식을 결정하는 내부 매개변수 집합이 $\phi$라는 의미다. 예를 들어, $g_\phi$가 단순한 위치·스케일 변환이라면
$$
g_\phi(\varepsilon,x)=\mu_\phi(x)+\sigma_\phi(x)\,\varepsilon
$$
처럼 평균과 분산을 계산하는 네트워크 $\mu_\phi,\sigma_\phi$의 가중치와 편향이 전부 $\phi$가 되고, 더 복잡한 경우에는 여러 층의 신경망 가중치와 편향이 $\phi$를 구성한다.
학습 과정에서 파라미터 $\phi$를 경사 하강법으로 갱신함으로써, 동일한 잡음 $\varepsilon$과 관측값 $x$에 대해 $g_\phi$가 생성하는 잠재변수 $z$가 점점 ELBO를 최대화하는 방향으로 조정된다. 즉, $g_\phi$는 “잡음과 관측을 결합해 잠재표현을 만들어내는 연산”을 담당하며, 그 구체적인 동작 방식을 담고 있는 학습 가능한 매개변수 $\phi$를 통해 최적화되는 핵심 구성 요소이다.
재매개변수화 트릭(reparameterization trick)은 본 논문에서 제안하는 SGVB 추정기의 핵심 기법으로, 기존의 Monte Carlo 경사 추정 시 발생하는 높은 분산 문제를 해결한다. 먼저 연속 잠재변수 $z$가 근사사후분포 $q_\phi(z\mid x)$를 따른다고 가정하고, 이 확률변수를 결정론적 함수 $g_\phi$와 보조 잡음 변수 $\varepsilon$의 결합으로 다음과 같이 재표현한다:
$$z = g_\phi(\varepsilon, x),\quad \varepsilon \sim p(\varepsilon).$$
이때 확률밀도 변화 법칙(change‐of‐variables)으로부터
$$q_\phi(z\mid x)\,\mathrm{d}z = p(\varepsilon)\,\mathrm{d}\varepsilon$$
가 성립하며, 따라서 임의의 함수 $f$에 대한 기댓값은
$$
\int q_\phi(z\mid x)\,f(z)\,\mathrm{d}z
= \int p(\varepsilon)\,f\bigl(g_\phi(\varepsilon,x)\bigr)\,\mathrm{d}\varepsilon
= \mathbb{E}_{p(\varepsilon)}\bigl[f(g_\phi(\varepsilon,x))\bigr]
$$
로 완전히 치환된다. 이어서 $\varepsilon$에 대해 i.i.d. 샘플 $\{\varepsilon^{(l)}\}_{l=1}^L$을 뽑아
$$
\mathbb{E}_{p(\varepsilon)}\bigl[f(g_\phi(\varepsilon,x))\bigr]
\approx \frac{1}{L}\sum_{l=1}^L f\bigl(g_\phi(\varepsilon^{(l)},x)\bigr)
$$
로 Monte Carlo 근사하면, 이 추정기는 오직 $g_\phi$ 내부 연산에 대해서만 파라미터 $\phi$에 의존하므로 체인룰(chain rule) 하나만으로 $\nabla_\phi$를 계산할 수 있다. 결과적으로 “$\nabla_\phi\log q_\phi$” 항을 제거하여 경사 분산을 획기적으로 낮추면서도, Monte Carlo 방식의 유연성을 유지할 수 있게 된다. 이러한 재매개변수화 기법을 2.3절의 ELBO 기댓값 추정에 적용함으로써, SGVB 추정기는 확률적 경사하강법을 통한 효율적이고 안정적인 최적화를 가능케 한다.
재매개변수화 트릭은 원래 분포 $q_\phi(z\mid x)$로부터 직접 샘플링한 후 기댓값을 계산할 때 발생하는 높은 분산을 줄이고, 파라미터 $\phi$에 대해 미분 가능한 형태로 변환하기 위한 기법이다. 가장 쉽게 이해할 수 있는 예로, 잠재변수 $z$가 1차원 가우시안 분포 $\mathcal{N}(\mu,\sigma^2)$를 따른다고 가정해 보자. 이때 우리는 대신 표준 정규분포 잡음 $\varepsilon\sim\mathcal{N}(0,1)$를 샘플링하여 $z=\mu+\sigma\,\varepsilon$로 정의함으로써, 원래 기대값
$$
\mathbb{E}_{\mathcal{N}(\mu,\sigma^2)}[f(z)]
$$
을
$$
\mathbb{E}_{\mathcal{N}(0,1)}[f(\mu+\sigma\varepsilon)]
\approx \tfrac1L\sum_{l=1}^L f\bigl(\mu+\sigma\varepsilon^{(l)}\bigr)
$$
로 바꿀 수 있다. 이렇게 하면 $\phi$에 대한 미분이 오직 $\mu+\sigma\varepsilon$ 내부만을 통과하는 연쇄법칙으로 처리되어 안정적이다.
이 방법은 가우시안에만 국한되지 않는다. 첫째, 역누적분포함수(inverse CDF)가 닫힌 형태로 주어지는 분포—예컨대 Exponential, Cauchy, Logistic, Rayleigh, Pareto, Weibull, Gumbel, Erlang 등—의 경우, 균일분포 $\varepsilon\sim U(0,1)$에 역누적분포함수를 적용하여 $z=F_{q_\phi}^{-1}(\varepsilon\mid x)$로 재매개변수화할 수 있다. 둘째, 위치–스케일(location–scale) 패밀리에 속하는 분포들—Laplace, Elliptical, Student’s t, Logistic, Uniform, Triangular and Gaussian distributions 등—도 $\varepsilon\sim$ 표준형 분포를 위치·스케일 변환하는 방식으로 동일하게 다룰 수 있다. 셋째, 로Log-Normal (exponentiation of normally distributed variable), Gamma (a sum over exponentially distributed variables), Dirichlet (weighted sum of Gamma variates), Beta, Chi-Squared, $F$ distribution 처럼 보다 복잡한 분포들은 여러 단순 분포의 합이나 조합을 통해 생성되므로, 이들을 구성하는 각 단계에서 재매개변수화를 적용할 수도 있다.
이 세 가지 접근법조차 적용하기 어려운 경우에는 역누적분포근사(inverse‐CDF approximation) 기법을 써서 계산 비용을 크게 늘리지 않고도 재매개변수화를 구현할 수 있다. 요컨대, 역누적분포, 위치–스케일 변환, 합성을 포함한 다양한 전략을 통해 거의 모든 연속분포에 재매개변수화 트릭을 적용함으로써 Monte Carlo 기댓값의 미분 가능성과 낮은 분산이라는 두 마리 토끼를 동시에 잡을 수 있다.
3. Example: Variational Auto-Encoder
본 절에서는 Variational Auto-Encoder(VAE) 의 구체적 구현 예시를 제시한다. 먼저 잠재변수 $z$의 사전 확률 분포를 centered isotropic multivariate Gaussian
$$
p_\theta(z) = \mathcal{N}(z;0,I)
$$
로 고정하여, 사전 확률 분포자체에는 학습할 파라미터가 없음을 명시한다. 다음으로 관측값 $x$에 대한 conditional likelihood $p_\theta(x\mid z)$는 데이터 형태에 따라 다음과 같이 정의된다: real‐valued일 경우 multivariate Gaussian, binary일 경우 Bernoulli 분포를 선택하며, 이들 분포의 파라미터(평균·분산 또는 성공확률)는 모두 decoding MLP(single‐hidden‐layer fully-connected neural network)가 $z$를 입력받아 산출한다.
실제 사후 확률 분포 $p_\theta(z\mid x)$는 계산하기 난해하므로, 우리는 encoding MLP를 통해 출력된 평균 $\mu^{(i)}$와 분산 $\sigma^{(i)}$를 이용해 변분 근사 사후분포
$$
q_\phi(z\mid x^{(i)}) = \mathcal{N}\bigl(z;\,\mu^{(i)},\,\sigma^{2(i)}I\bigr)
\tag{9}
$$
를 가정한다. 여기서 $\mu^{(i)},\sigma^{(i)}$는 각각 데이터포인트 $x^{(i)}$와 변분 파라미터 $\phi$의 비선형 함수로 구현된 MLP의 출력이다(부록 C 참고).
이와 같은 구조 하에서 인코더 $q_\phi$와 디코더$p_\theta$의 파라미터 $\phi,\theta$를 AEVB 알고리즘을 통해 공통으로 최적화하면, MCMC 없이도 효율적인 사후 추론 및 생성 모델 학습이 가능하다.
다시 정리하면, 사전 확률분포 $p_\theta(z)=\mathcal{N}(z;0,I)$는 평균이 0이고 공분산이 단위행렬인 정규분포로 고정되어 있으며, 학습 가능한 파라미터를 포함하지 않는다. 반면, 관측값 $x$에 대한 근사 사후분포 $q_\phi(z\mid x)$는 변분 파라미터 $\phi$를 통해 평균 $\mu_\phi(x)$와 분산 $\sigma^2_\phi(x)$을 예측함으로써 실제 사후분포 $p_\theta(z\mid x)$를 근사하도록 학습된다. 또한, 조건부 우도 $p_\theta(x\mid z)$는 decoding MLP의 가중치·편향 집합인 $\theta$를 통해 real‐valued 데이터의 경우 평균 및 분산, binary 데이터의 경우 성공 확률을 출력하여 정의된다. 요약하면, prior는 고정된 분포로 두고, 오직 encoder $q_\phi$와 decoder $p_\theta$만이 각각 $\phi$와 $\theta$라는 학습 가능한 파라미터를 지니며 모델링된다는 점이 본 VAE의 중요한 특징이다.
4. Related work
본절에서는 제안하는 AEVB 알고리즘이 위치하는 연구 맥락을 정리한다. 먼저, Wake–Sleep 알고리즘[Hinton et al., 1995]은 본 논문과 마찬가지로 recognition model을 사용하여 연속형 잠재변수 모델의 posterior를 근사한다는 점에서 유사하다. 그러나 Wake–Sleep은 두 개의 상이한 목적함수를 동시 최적화해야 하며, 이들 목적함수가 주변 우도(marginal likelihood) 또는 그 하한의 최적화와 일치하지 않는다는 단점이 있다. 다만 이 알고리즘은 이산 잠재변수 모델에도 적용 가능하고, 데이터 포인트당 계산 복잡도는 AEVB와 동일하다.
최근 Stochastic Variational Inference[Hoffman et al., 2013]가 크게 주목받고 있으며, 특히 [Ranganath et al., 2012]와 [Ranganath et al., 2013]에서는 variance reduction을 위한 control variates 기법이 도입되어 나이브 몬테카를로 경사 추정기의 높은 분산 문제를 해결하려 했다. 또한 [Kingma & Welling, 2014]에서는 본 논문과 유사한 reparameterization trick을 사용한 stochastic variational 알고리즘을 제안해 exponential‐family approximations의 natural parameters 학습에 적용하였다.
AEVB는 directed probabilistic models의 변분 목적함수와 auto-encoder 구조 간의 연결을 명시적으로 드러낸다. 사실 linear auto-encoder 와 linear-Gaussian generative model 간의 관계는 이미 잘 알려져 있어, PCA가 prior $p(z)=\mathcal{N}(0,I)$와 $p(x\mid z)=\mathcal{N}(x;Wz,\epsilon I)$ (with $\epsilon\to0$)의 ML 해라는 사실이 [Roweis, 1998]에서 증명된 바 있다. 더욱이 [Vincent et al., 2010]는 unregularized autoencoder의 학습 기준이 입력 $X$와 latent $Z$ 간의 상호정보(mutual information)에 대한 lower bound와 동일함을 보였으나, 단순 reconstruction error만으로는 유용한 표현을 학습하기에 충분치 않다는 점이 [Bengio et al., 2013]에서 지적되었다. 이에 denoising, contractive, sparse autoencoder 등 다양한 regularization 기법이 제안되었다.
AEVB의 SGVB objective는 식 (10)의 KL‐regularizer 항을 통해 변분 하한에 의해 강제되는 하이퍼파라미터 없는 정규화를 포함하며, 별도의 불필요한 정규화 하이퍼파라미터 없이도 유용한 표현을 학습할 수 있다. 이 밖에도 Predictive Sparse Decomposition (PSD)[Kavukcuoglu et al., 2008]나 노이즈 오토인코더를 통해 마르코프 체인의 전이 연산자를 학습하는 Generative Stochastic Networks (GSN)[Bengio et al., 2013] 등 encoder–decoder 구조의 다양한 변형이 제안되었으며, Deep Boltzmann Machine 학습을 위한 recognition model[Salakhutdinov & Larochelle, 2010]이나, 이산 잠재 변수를 다루는 DARN[Gregor et al., 2013] 등도 등장하였다. 그러나 이들 접근법은 주로 비정규화 undirected 모델이나 sparse coding 계열에 한정되는 반면, AEVB는 일반적인 directed 확률모델을 대상으로 encoder와 decoder를 end-to-end로 joint하게 학습할 수 있다는 점에서 차별화된다.
DARN[Gregor et al., 2013]은 auto-encoding 구조를 이용해 directed probabilistic model을 학습하되, 이산 잠재변수에만 적용되었다. 그보다 더 최근에 발표된 Rezende et al. (2014)[RMW14]는 본 논문에서 소개한 reparameterization trick을 이용해 auto-encoders, directed probabilistic models, stochastic variational inference 간의 연결고리를 독립적으로 재발견함으로써 AEVB에 대한 추가적 관점을 제시했다.
5. Experiments
본 절에서는 제안하는 AEVB 알고리즘의 성능을 MNIST 및 Frey Face 데이터셋을 통해 평가하였다. 모델 구조로는 3장에서 소개한 바와 같이 encoding과 decoding에 각각 동일한 수의 hidden unit을 가진 single‐hidden‐layer MLP를 사용하였으며, MNIST의 이진화된 손글씨 숫자 이미지에는 Bernoulli 출력 디코더를, 연속치 얼굴 이미지인 Frey Face 데이터에는 Gaussian 출력 디코더를 적용하되, 출력 평균이 $(0,1)$ 구간에 머물도록 시그모이드 활성화 함수를 추가하였다.
학습은 변분 하한 $\mathcal{L}(\theta,\phi;X)$의 gradient를 이용한 stochastic gradient ascent 방식으로 이루어졌으며, 여기에 prior $p(\theta)=\mathcal{N}(0,I)$에 대응하는 경미한 weight decay를 더하여 approximate MAP 추정과 동등한 형태로 최적화를 수행하였다. 파라미터는 모두 $\mathcal{N}(0,0.01)$에서 초기화되었고, 학습률은 Adagrad를 사용하되 글로벌 스텝사이즈를 $\{0.01,0.02,0.1\}$ 중 training set의 초기 반복 성능에 따라 선택하였다. 매 반복마다 크기 $M=100$의 미니배치를 샘플링하고, 잠재변수당 $L=1$개의 샘플을 생성하여 gradient를 계산하였다.
비교 대상으로는 전통적인 Wake–Sleep 알고리즘을 채택하였는데, 여기서도 동일한 recognition model(encoding MLP)을 사용하고 variational 및 generative 파라미터를 MAP 기준으로 joint하게 학습하였다. 각 알고리즘의 성능은 학습 과정 중 변분 하한의 상승 속도 및 학습 후 추정된 marginal likelihood를 바탕으로 비교·분석되었다.
첫째, variational lower bound 측정을 위해 MNIST와 Frey Face 데이터셋에 각각 500개·200개의 hidden unit을 갖는 encoder/decoder 구조를 학습하였다. 이는 기존 auto‐encoder 연구들을 참고해 설정한 규모이며, 알고리즘 간 상대 성능은 hidden unit 수에 크게 민감하지 않음을 확인하였다. Figure 2에 제시된 바와 같이, AEVB는 변분 하한을 가장 빠르고 안정적으로 끌어올렸으며, 오히려 latent 차원을 과도하게 늘려도 과적합 현상이 관찰되지 않았다. 이는 변분 하한 자체가 내장한 KL‐정규화 항이 과도한 표현력을 자동으로 억제하기 때문이다.

둘째, marginal likelihood를 직접 비교하기 위해 잠재 공간 차원을 3으로 제한하고, encoder/decoder 모두 100개의 hidden unit을 갖는 신경망을 학습한 뒤, MCMC 기반의 추정기를 사용해 marginal likelihood를 계산하였다(추정기 세부사항은 부록 참조). 이때 AEVB와 Wake–Sleep을, Hybrid Monte Carlo(HMC)를 이용한 Monte Carlo EM(MCEM)과 비교하였으며, 작은 학습 세트와 큰 학습 세트 모두에 대해 수렴 속도를 측정했다. Figure 3에서 보듯, AEVB는 MCEM보다 훨씬 적은 반복만으로 우도 하한과 marginal likelihood 모두에서 빠르게 수렴하였고, Wake–Sleep 대비에도 일관된 우위를 보였다.

이상의 결과는 AEVB가 다양한 모델 크기와 데이터셋 규모에 걸쳐 end-to-end 확률적 추론 및 학습의 효율성과 안정성을 모두 달성함을 실증한다.
6. Conclusion
본 논문에서는 연속 잠재변수를 갖는 directed probabilistic model의 효율적 근사추론을 위해, 변분 하한을 몬테카를로 방식으로 직접 최적화할 수 있는 Stochastic Gradient VB (SGVB) 추정기를 제안하였다. SGVB는 표준 확률적 경사기법으로 손쉽게 미분·최적화할 수 있으며, i.i.d. 데이터와 데이터당 연속 잠재변수 구조에 특화된 Auto-Encoding VB (AEVB) 알고리즘으로 확장된다. AEVB는 SGVB를 이용해 인식 모델(recognition model)을 학습함으로써, 기존의 반복적 MCMC나 복잡한 기대값 계산 없이도 encoder–decoder 구조에서 end-to-end로 효율적인 추론과 학습을 동시에 달성한다. 이론적 이점은 MNIST·Frey Face 실험에서 변분 하한과 주변 우도의 빠른 수렴으로 입증되었다.
7. Future work
SGVB와 AEVB는 연속 잠재변수를 포함하는 거의 모든 모델에 적용 가능하므로, 다음과 같은 확장이 기대된다:
1. 심층 계층형 생성 모델: convolutional neural network 등 deep architecture를 encoder·decoder로 사용하여 AEVB로 joint 학습
2. 시계열 모델: dynamic Bayesian network 같은 시계열 데이터에 대한 확률적 추론
3. 전역 파라미터 변분추론: global model parameter에 대한 variational inference로 SGVB 적용
4. 지도학습 확장: latent 변수를 포함한 supervised 모델에서 복잡한 noise 분포 학습
이들 연구를 통해 SGVB·AEVB 프레임워크는 더욱 폭넓은 분야에 효율적이고 확장 가능한 확률적 추론·학습 솔루션을 제공할 수 있을 것이다.