본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
Abstract
본 논문은 정렬된 이미지 쌍 없이도 image to image 변환을 수행할 수 있는 새로운 방법을 제안한다. 기존의 이미지 변환은 입력 이미지와 출력 이미지 간의 매핑을 학습하기 위해 정렬된 쌍이 필요했지만, 실제 많은 경우에는 그러한 데이터가 존재하지 않는다.저자들은 쌍이 없는 데이터에서 원본 도메인 $X$의 이미지를 대상 도메인 $Y$로 변환하는 매핑 $G: X \rightarrow Y$를 학습하며, 이때 적대적 손실(adversarial loss)을 사용하여 생성된 이미지 $G(X)$의 분포가 실제 $Y$와 구별되지 않도록 한다. 그러나 이 문제는 제약이 적어 해가 불안정하므로, 역방향 매핑 $F: Y \rightarrow X$와 함께 학습하고, 사이클 일관성 손실(cycle consistency loss)을 도입하여 $F(G(X)) \approx X$를 만족하도록 유도한다. 실험은 스타일 변환, 객체 변형, 계절 전환, 사진 향상 등 짝지어진 학습 데이터가 없는 다양한 과제에서 정성적 결과를 제시하며, 기존 방법들과의 정량적 비교를 통해 본 방법의 우수한 성능을 입증하였다.
1. Introduction
1873년 봄, 모네는 센강 변에서 풍경을 자신의 인상주의적 화풍으로 표현했고, 만약 그가 여름 저녁의 카시 항구를 보았다면 역시 특유의 색감과 붓터치로 그렸을 것이라 상상할 수 있다. 우리는 실제 사진과 그림을 비교한 적이 없어도, 모네의 그림들과 풍경 사진들의 스타일 차이를 알고 있기 때문에, 하나의 장면이 한 스타일에서 다른 스타일로 변환되었을 때 어떤 모습일지 추론할 수 있다.
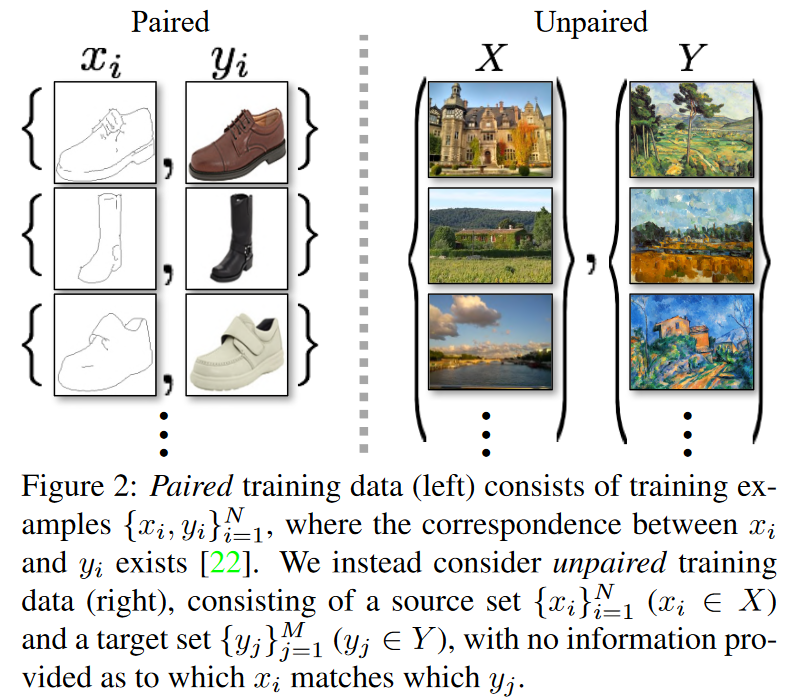
본 논문에서는 쌍을 이루는 학습 예제가 전혀 없는 상황에서도, 한 이미지 컬렉션의 고유한 특성을 포착하고 이러한 특성이 다른 이미지 컬렉션으로 어떻게 변환될 수 있는지를 학습할 수 있는 방법을 제안한다. 이러한 문제는 보다 일반적으로 image-to-image translation이라고 부르며, 특정 장면에 대한 하나의 표현 $x$을 다른 표현 $y$로 변환하는 작업이다. 예를 들어, 회색조에서 컬러로, 이미지에서 의미 라벨로, 에지 맵에서 실제 사진으로의 변환 등이 이에 해당한다. 컴퓨터 비전, 이미지 처리, 계산 사진학(computational photography), 그리고 그래픽스 분야에서 수년간의 연구를 통해 감독 학습(supervised learning) 환경에서 강력한 변환 시스템들이 개발되어 왔다. 이 경우, $\{x_i, y_i\}_{i=1}^N$과 같은 이미지 쌍이 주어진다(Figure 2, 왼쪽 참조), 하지만 이러한 쌍 데이터를 수집하는 것은 어렵고 비용이 많이 들며, 예를 들어 의미 분할(semantic segmentation)과 같은 작업을 위한 데이터셋은 몇 개밖에 존재하지 않으며 규모도 작다. 예술적 스타일 변환과 같은 그래픽 작업에서는 원하는 출력이 매우 복잡하여 보통 예술가의 창작 작업이 필요하기 때문에 더욱 어렵다. 또한, 얼룩말 ↔ 말(zebra ↔ horse)과 같은 객체 변형(object transfiguration) 작업에서는 원하는 출력 자체가 명확하게 정의되지 않기 때문에, 입력-출력 쌍을 구성하기조차 어렵다.
논문은 입력–출력 쌍 없이도 서로 다른 이미지 도메인 간 변환을 학습하는 알고리즘을 제안한다. 동일한 장면을 서로 다른 방식으로 표현한 두 이미지 집합(X와 Y)이 주어졌을 때, 변환 함수 $G\colon X\to Y$를 적대적 학습(adversarial loss)을 통해 학습하여 $G(x)$의 분포가 실제 $Y$의 분포와 일치하도록 유도한다. 그러나 분포 정합만으로는 개별 $x$와 $y$가 의미 있게 대응된다는 보장이 없고, 분포 일치를 달성하는 무수히 많은 변환이 존재한다. 또한 적대적 학습만으로는 모든 입력이 같은 출력으로 수렴하는 ‘모드 붕괴(mode collapse)’ 문제가 자주 발생한다. 이러한 문제를 해결 하기 위해 짝지어진 데이터 없이도 이미지 도메인 간 변환을 가능하게 하기 위해, 변환 함수 $G\colon X\to Y$와 역변환 $F\colon Y\to X$를 동시에 학습시키고 “순환 일관성(cycle consistency)” 손실을 추가한다. 즉, $x$를 $G$로 $Y$ 도메인으로 옮겼다가 $F$로 다시 $X$로 복원했을 때 원본 $x$와 유사해져야 하며(또한 $y$도 마찬가지), 이 손실을 두 도메인 각각에 대한 적대적 손실(adversarial loss)과 결합하여 짝 데이터 없이도 의미 있는 변환을 수행하는 최종 목적함수를 정의한다. 이 방법은 스타일 전환, 객체 변형, 계절 전환, 사진 보정 등 여러 분야에 적용 가능하며, 기존의 수작업 분리 방식이나 공유 임베딩 방식보다 성능이 뛰어나다. 그리고 PyTorch/Torch 구현을 제공하며, 추가 실험 결과는 웹사이트에서 볼 수 있다.

2. Related work
GAN은 이미지 생성·편집·표현 학습에서 탁월한 성과를 거뒀으며, 최근에는 텍스트→이미지, 인페인팅, 미래 프레임 예측, 동영상·3D 생성에도 활용된다. GAN의 핵심은 적대적 손실을 통해 생성물이 실제와 구분 불가하도록 학습시키는 것이며, 본 연구도 이를 차용해 변환된 이미지를 목표 도메인과 구별되지 않게 만드는 매핑을 학습한다. 이미지 간 변환 분야는 단일 쌍 학습으로 텍스처를 복제하던 초기 기법에서, CNN 기반의 파라메트릭 모델 학습으로 발전했으며, “pix2pix”를 포함한 조건부 GAN을 통해 입력→출력 매핑을 성공적으로 학습하였다. 본 연구는 pix2pix 을 기반으로 하지만 이들 기법과 달리, 쌍으로 된 학습 데이터 없이(unpaired)도 입력 도메인에서 출력 도메인으로 변환하는 매핑을 학습할 수 있다는 점이 핵심 차별점이다.
이전 연구들은 쌍 없는 이미지 변환을 위해 마르코프 랜덤 필드 기반 베이지안 모델, CoGAN·Cross-Modal Scene Networks의 가중치 공유, VAE와 GAN 결합, 그리고 입력·출력 간 특정 콘텐츠 특징 공유 등의 다양한 기법을 제안하였다. 하지만 이들은 보통 클래스·픽셀·특징 공간 같은 사전 정의된 유사도나 동일 임베딩 공간을 전체한다. 반면, 본 논문에서는 이러한 제한 없이 범용적으로 적용 가능한, 입력과 출력 간 별도의 유사도 함수나 저차원 공간 가정 없이 학습하는 방법을 제안하며, 5.1절에서 다양한 기존 기법과 비교 평가를 수행한다.
순환 일관성은 ‘한 방향으로 변환한 뒤 역방향으로 다시 변환했을 때 원본으로 돌아와야 한다’는 제약으로, 구조화된 데이터 학습을 안정화하는 기법이다. 이 아이디어는 시각 추적, 역번역 등 오랜 관행으로 사용돼 왔으며, 최근에는 구조광 복원, 3D 매칭, 의미 정렬, 깊이 추정 등 다양한 컴퓨터 비전 과제에도 적용되었다. 본 연구는 두 변환 함수 $G$와 $F$가 서로 역관계가 되도록 순환 일관성 손실을 추가해 학습하며, 동시 발표된 다른 연구들도 이와 유사한 방식을 제안하고 있다.
본 연구는 개별 이미지 간 전이가 아닌, 전체 이미지 컬렉션 간의 대응 구조를 학습하는 데 주안점을 둔다. 신경 스타일 전회(Neural Style Transfer)는 특정 두 이미지의 콘텐츠와 스타일을 결합하는 데 강점을 보이지만, 본 기법은 그림→사진 변환이나 객체 변형처럼 단일 샘플 전이가 어려운 작업에도 적용 가능하도록, 컬렉션 전체의 고수준 외관 패턴 간 매핑을 학습한다.
3. Formulation
두 개의 도메인 $X$와 $Y$ 간의 변환을 학습하기 위해, 저자들은 $G: X\to Y$와 $F: Y\to X$ 두 개의 매핑 함수와, 각각 실제 이미지와 변환된 이미지를 구분하는 적대적 판별기 $D_X$, $D_Y$를 도입했다. 학습 목표는 두 가지 손실로 구성된다. 첫째, 적대적 손실을 통해 생성된 이미지의 분포가 목표 도메인의 실제 분포와 일치하도록 하고, 둘째, 순환 일관성 손실을 통해 $x$를 $G$로 변환한 뒤 다시 $F$로 복원했을 때 원본 $x$에 가깝게 유지되도록 함으로써 $G$와 $F$가 서로 역함수 역할을 하도록 제약한다. 이로써 지도된 쌍(pair) 예제 없이도 두 도메인 간 의미 있는 매핑을 안정적으로 학습할 수 있다.
3.1 Adversarial Loss
이 절에서는 두 변환 함수 $G\colon X\to Y$와 $F\colon Y\to X$에 각각 적대적 손실을 적용한다. 예컨대 $G$와 대응하는 판별기 $D_Y$에 대한 손실은
$$
L_{\text{GAN}}(G,D_Y)=\mathbb{E}_{y\sim p_{\text{data}}(y)}[\log D_Y(y)]+\mathbb{E}_{x\sim p_{\text{data}}(x)}[\log (1 - D_Y(G(x)))]\tag{1}
$$
로 정의되며, $G$는 생성된 이미지 $G(x)$가 실제 $Y$ 도메인 이미지와 구분되지 않도록 학습하고, $D_Y$는 진짜와 가짜를 가려내도록 학습한다. 이때 $G$는 손실을 최소화하고, $D_Y$는 손실을 최대화하는 미니맥스 게임을 벌인다. 동일한 방식으로 $F$와 그 판별기 $D_X$에도 대응하는 적대적 손실을 적용한다.
3.2 Cycle Consistency Loss
순환 일관성 손실은 단순한 적대적 손실만으로는 보장할 수 없는 개별 입력–출력 간 의미적 대응을 확보하기 위해 도입되었다. 순환 일관성 손실을 도입하기 위해 저자들은 변환 함수들이 순환 일관성(cycle consistency) 을 지켜야 한다고 가정하였다. 두 변환기 $G:X\to Y$, $F:Y\to X$를 학습할 때, 입력 $x$를 $G$로 변환한 뒤 다시 $F$로 복원했을 때 원본 $x$에 가까워지도록, 그리고 $y$에 대해서도 마찬가지로 $F$→$G$ 순환 복원 결과가 원본 $y$와 가깝도록 $L_1$ 거리 기반의 순환 일관성 손실을 추가한다. 이 제약을 통해 $G$와 $F$가 서로 역함수 관계를 이루며 불필요한 매핑 자유도를 줄여, 다양한 이미지 변환 과제에서 입력이 의미 있게 재구성됨을 확인했다.
$$
L_{\rm cyc}(G,F)
= \; \mathbb{E}_{x\sim p_{\rm data}(x)}\bigl[\|\,F(G(x))-x\,\|_1\bigr]
\;+\;
\mathbb{E}_{y\sim p_{\rm data}(y)}\bigl[\|\,G(F(y))-y\,\|_1\bigr].\tag{2}
$$

3.3 Full Objective
이 모델은 두 개의 적대적 손실(GAN 손실)과 두 이미지 간 매핑의 순환 일관성 손실을 결합해 학습한다. $G: X\to Y$와 $F: Y\to X$를 번갈아 평가하면서, 생성된 이미지가 각각 목표 도메인 $Y$와 $X$의 실제 분포처럼 보이도록 $L_{\text{GAN}}$을 최소화하고, 동시에 $x\to G(x)\to F(G(x))\approx x$ 및 $y\to F(y)\to G(F(y))\approx y$가 성립하도록 $L_{\text{cyc}}$를 적용한다. 이 두 손실의 균형을 조절하는 하이퍼파라미터 $\lambda$를 통해 최종 목표 함수를 정의하며, 이중 최적화(min–max)를 통해 $G$, $F$, $D_X$, $D_Y$를 공동으로 학습한다. 실험 결과, 적대적 손실만으로는 무의미한 매핑이 발생하고(모드 붕괴), 순환 손실만으로는 충분한 제약이 걸리지 않으므로, 두 손실을 함께 사용하는 것이 고품질 번역 결과를 얻는 데 핵심임을 확인했다.
$$
L(G, F, D_X, D_Y)
= L_{\text{GAN}}(G, D_Y, X, Y)
+ L_{\text{GAN}}(F, D_X, Y, X)
+ \lambda\,L_{\text{cyc}}(G, F),\tag{3}
$$
$$
G^*, F^* = \arg\min_{G,F}\,\max_{D_X, D_Y}\,L(G, F, D_X, D_Y).\tag{4}
$$

4. Implementation
이 아키텍처는 Johnson 등(“Perceptual losses for real-time style transfer and super-resolution”)이 제안한 생성기 구조를 활용한다. 입력은 3개의 컨볼루션 → 여러 잔차 블록(128×128px 입력에 6개, 256×256px 이상 입력에 9개) → 2개의 역컨볼루션(스트라이드 ½) → RGB 출력 컨볼루션으로 처리되며, 학습 안정화를 위해 인스턴스 정규화를 도입한다. 판별기는 70×70 크기의 패치마다 진위를 판별하는 PatchGAN을 사용하여 파라미터 수를 줄이면서도 다양한 이미지 크기에 대응한다.
학습 세부 사항: 모델 학습 절차를 안정화하기 위해 최근 연구에서 제안된 두 가지 기법을 적용하였다. 첫째, LGAN(식 1)의 경우 음의 로그 우도 목표 함수를 최소제곱 손실로 대체하였다. 이 손실 함수는 학습 중 더 안정적이며, 보다 높은 품질의 결과를 생성한다. 구체적으로, GAN 손실 $L_{\text{GAN}}(G,D,X,Y)$에 대해, 생성자 $G$는 $\mathbb{E}_{x\sim p_{\text{data}}(x)}[(D(G(x)) - 1)^2]$를 최소화하도록 학습하며, 판별자 $D$는 $\mathbb{E}_{y\sim p_{\text{data}}(y)}[(D(y) - 1)^2] + \mathbb{E}_{x\sim p_{\text{data}}(x)}[D(G(x))^2]$를 최소화하도록 학습한다.
둘째, 모델 진동 현상(model oscillation)을 줄이기 위해 Shrivastava 등의 전략을 따라, 최신 생성기가 생성한 이미지가 아닌 과거 생성 이미지 히스토리를 활용해 판별자를 업데이트한다. 이를 위해 이전에 생성된 50개의 이미지를 저장하는 버퍼를 유지한다. 모든 실험에서 식 3의 하이퍼파라미터 $\lambda$는 10으로 설정했다. 옵티마이저로는 Adam을 사용하고 배치 크기는 1로 설정했다. 모든 네트워크는 학습률 0.0002로 처음부터 학습했으며, 처음 100 에폭 동안 동일한 학습률을 유지한 뒤, 이후 100 에폭에 걸쳐 선형적으로 0까지 감소시켰다.
5. Results
본 논문에서는 짝지어진 입력–출력 예제가 없는 환경에서도 이미지 도메인 간 변환을 가능하게 하는 CycleGAN을 제안한다. 먼저, 실제 정답 쌍이 존재하는 데이터셋에서 최신 언페어드(image-to-image) 변환 기법들과 CycleGAN을 비교하여 유사한 성능을 보임을 확인한다. 이어서, 적대적 손실(adversarial loss)과 순환 일관성 손실(cycle consistency loss)이 결과에 미치는 영향을 분석하고, 전체 모델과 손실 구성 요소를 제거한 변형 모델 간의 성능 차이를 검증한다. 마지막으로, 짝지어진 데이터가 전혀 없는 다양한 응용 분야—예컨대 스타일 변환, 계절 변화, 객체 치환, 사진 개선 등—에 CycleGAN을 적용하여 높은 범용성을 입증하며, 구현 코드와 학습된 모델, 상세 실험 결과를 웹사이트에 공개한다.
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
GitHub - junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch
Image-to-Image Translation in PyTorch. Contribute to junyanz/pytorch-CycleGAN-and-pix2pix development by creating an account on GitHub.
github.com
https://github.com/junyanz/CycleGAN
GitHub - junyanz/CycleGAN: Software that can generate photos from paintings, turn horses into zebras, perform style transfer,
Software that can generate photos from paintings, turn horses into zebras, perform style transfer, and more. - junyanz/CycleGAN
github.com
https://junyanz.github.io/CycleGAN/
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks In ICCV 2017 Abstract Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image us
junyanz.github.io
5.1 Evaluation
본 연구는 “pix2pix”와 동일한 실험 설정에서 제안된 CycleGAN을 평가하여, Cityscapes의 의미 레이블↔사진 및 지도↔항공 사진 변환 작업에서 기준 모델들 대비 우수한 성능을 보였음을 정성적·정량적으로 입증한다. 아울러 제안된 전체 손실 함수의 각 구성 요소가 결과에 미치는 영향을 제거 실험을 통해 분석한다.
5.1.1 Evaluation Metrics
본 실험에서는 AMT 지각 테스트를 통해 지도↔항공 사진 변환 결과의 사실성을 평가하였으며, 연습 단계 후 40회의 본 실험을 통해 각 알고리즘이 “가짜” 이미지를 진짜로 인식시키는 비율을 측정했다. 결과 해석 시에는 동일 조건 하에 비교한 본 연구 방법과 기준 모델 간의 상대적 성능 평가에만 사용해야 함을 강조한다. 또한 생성된 사진의 해석 가능성을 FCN을 활용해 자동 정량화한 FCN 점수를 도입하여, Cityscapes 레이블→사진 과제를 평가하였다. 또한, 사진→레이블 과제에는 전체 픽셀 정확도, 클래스별 정확도, 평균 Class IOU 등 Cityscapes 표준 의미 분할 지표를 사용하였다. 마지막으로 Cityscapes 벤치마크의 픽셀별 정확도, 클래스별 정확도, 평균 Class IOU 세 가지 표준 지표로 사진→레이블 변환 성능을 평가하였다.
5.1.2 Baselines
CoGAN
이 방법은 도메인 X용 GAN 생성기 하나와 도메인 Y용 GAN 생성기 하나를 학습하되, 초기 몇 개 층의 가중치를 묶어서(latent representation을 공유하도록) 사용한다. X에서 Y로의 변환은 이미지 X를 생성하는 잠재 표현(latent representation)을 찾은 뒤, 이를 스타일 Y로 렌더링(render)함으로써 이뤄진다.
SimGAN
Shrivastava 등의 방법은 본 연구와 유사하게, 적대적 손실(adversarial loss)을 사용하여 X에서 Y로의 변환(mapping)을 학습한다. 이 정규화 항 ‖x − G(x)‖₁은 픽셀 수준에서 큰 변화를 일으키는 것을 억제하기 위해 사용된다.
특징 손실 + GAN
SimGAN의 변형 버전도 실험하였는데, 여기서는 RGB 픽셀 값 대신 사전 학습된 네트워크(VGG-16 relu4_2)의 심층 이미지 특징 위에서 L₁ 손실을 계산한다. 이렇게 심층 특징 공간에서 거리를 계산하는 방법은 “지각 손실(perceptual loss)”이라고도 불린다.
BiGAN/ALI
Unconditional GAN은 무작위 잡음 z를 이미지 x로 매핑하는 생성기 G: Z → X를 학습한다. BiGAN과 ALI는 여기에 이미지 x를 잠재 벡터 z로 되돌리는 역매핑 F: X → Z도 함께 학습할 것을 제안한다. 원래는 z → x 구조에 쓰이던 이 목적 함수를, 본 연구에서는 소스 이미지 x를 목표 이미지 y로 매핑할 때에도 동일하게 구현해 적용했다.
pix2pix
페어된 데이터를 이용해 학습하는 pix2pix와도 비교하여, 페어 데이터 없이 이 “상한선(upper bound)”에 얼마나 근접할 수 있는지 평가했다. 공정한 비교를 위해, CoGAN을 제외한 모든 비교 기법들은 본 연구의 네트워크 아키텍처 및 설정과 동일하게 구현하여 실험했다. CoGAN은 공유된 잠재 표현에서 이미지를 생성하는 방식이라 본 연구의 이미지→이미지 네트워크와는 호환되지 않아, 공개된 CoGAN 구현 코드를 그대로 사용했다.
https://github.com/mingyuliutw/CoGAN
GitHub - mingyuliutw/CoGAN
Contribute to mingyuliutw/CoGAN development by creating an account on GitHub.
github.com
5.1.3 Comparison against baselines
베이스라인 방법들은 의미 있는 결과를 내지 못했으나, 제안된 기법은 완전 지도 학습 수준의 품질을 달성했다. AMT 실험에서는 약 25%의 경우에 사람들을 속일 정도로 현실감 있는 변환을 보여주었고, Cityscapes 데이터셋에서도 레이블→사진 및 사진→레이블 전환 과제에서 다른 방법들보다 뛰어난 성능을 기록했다.

5.1.4 Analysis of the loss function
GAN 손실과 사이클 일관성 손실을 모두 포함해야만 안정적이고 높은 품질의 번역 결과를 얻을 수 있으며, 어느 하나라도 제거하거나 단방향 사이클 손실만 사용할 경우 학습이 불안정해지고 모드 붕괴가 발생한다.


5.1.5 Image reconstruction quality
지도와 항공 사진처럼 정보의 다양성 차이가 큰 도메인 간 변환에서도, 네트워크는 입력 이미지를 충실히 복원하여 원본과 거의 차이가 없는 결과를 보여주었다.
5.1.6 Additional results on paired datasets
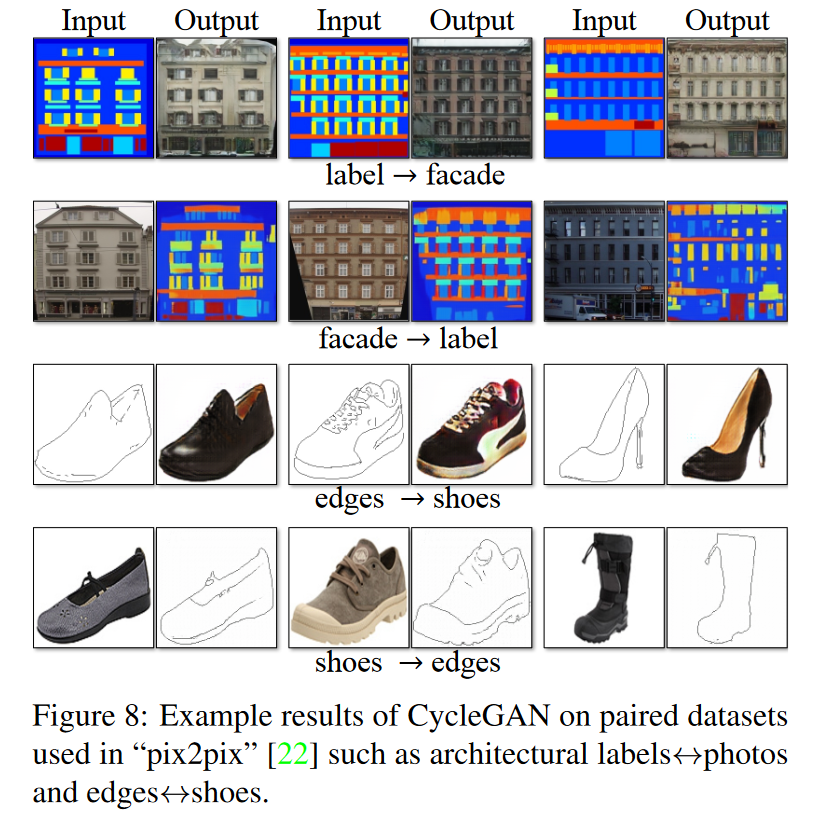
건축 레이블↔사진, 윤곽선↔신발 같은 다양한 페어드 데이터셋에서도, 페어드 감독 학습 없이도 pix2pix 수준의 이미지 품질을 달성함을 확인할 수 있었다.
5.2. Applications
이 절에서는 페어드 데이터가 없는 다양한 변환 과제에서 CycleGAN의 우수성을 검증하였다.
1. 컬렉션 스타일 전환
Flickr와 WikiArt에서 수집한 풍경 사진을 학습시켜, 특정 작품이 아닌 전체 화가의 ‘컬렉션’ 화풍을 전이할 수 있음을 보였다. 구체적으로 Cezanne(526장), Monet(1,073장), Van Gogh(400장), Ukiyo-e(563장) 등 네 화가의 방대하고 다양한 데이터를 활용하여 반 고흐 전체 화풍을 모방한 사진 생성에 성공했다.


2. 객체 변형 (Object Transfiguration)
ImageNet의 서로 다른 두 클래스(각 약 1,000장) 간 변형을 수행함으로써, 기존 Turmukhambetov 등의 서브스페이스 기법과 달리 기하학적 유사성을 지닌 범주 간에도 자연스러운 ‘visual transfiguration’을 실현하였다.

3. 계절 전환 (Season Transfer)
Yosemite의 겨울 사진(854장)과 여름 사진(1,273장)을 학습하여, 단순히 색조나 조명만이 아니라 계절감 전반을 바꾸는 자연스러운 풍경 변환을 달성했다.(Figure 13 참조)
4. 회화→사진 변환
Monet 등의 회화를 실제 사진처럼 바꾸기 위해 Taigman 등의 ‘항등 매핑(identity mapping) 손실’을 도입하였다. 이 손실이 없으면 Monet의 낮 풍경이 일몰 풍경으로 바뀌는 등의 불필요한 색조 변환이 자주 일어난다.
$$
L_{\text{identity}}(G,F)
=
\mathbb{E}_{y\sim p_{\mathrm{data}}(y)}\bigl[\|G(y)-y\|_{1}\bigr]
+
\mathbb{E}_{x\sim p_{\mathrm{data}}(x)}\bigl[\|F(x)-x\|_{1}\bigr]
$$
이를 통해 입력 도메인 샘플에 대해 생성기가 원본 색조와 구도를 잘 보존하도록 정규화하여 불필요한 일몰·야간 풍경 변경을 방지하였다.


5. 사진 심도 효과
스마트폰으로 촬영된 꽃 사진(깊은 피사계 심도)을 DSLR·대구경 렌즈로 촬영한 얕은 피사계 심도의 사진처럼 변환함으로써, 실용적 ‘배경 흐림’(bokeh) 효과까지 안정적으로 구현했다.

6. Neural Style Transfer 비교
Gatys 등의 기법과 비교하기 위해, 단일 작품 대신 전체 컬렉션의 ‘평균 Gram 행렬’을 활용한 스타일 전이 실험을 진행했다. 그 결과, Gatys 방식이 적절한 스타일 이미지를 찾기 어렵고 종종 사실감이 떨어지는 데 반해, CycleGAN은 대상 도메인과 매우 유사한 고품질 사진을 일관되게 생성했다.

이처럼 CycleGAN은 페어드 학습 없이도 회화·풍경·객체·계절·심도 등 다양한 변환 과제를 효과적으로 수행하며, 특히 컬렉션 단위 스타일 전이와 항등 손실 도입을 통해 기존 기법을 능가하는 자연스럽고 실용적인 결과를 제공한다.
6. Limitations and Discussion
CycleGAN이 색상·질감 변환 과제에서는 우수한 성능을 보이지만, 기하학적 변형이 필요한 작업에서는 실패 사례가 잦음을 지적한다. 특히 개→고양이 변환이나 말→얼룩말 변환에서 최소 변화 학습 또는 데이터 분포 불일치로 인한 오류가 발생했으며, 나무와 건물 레이블이 뒤바뀌는 모호성도 관찰되었다. 이러한 문제를 해결하려면 기하학적 변형을 다룰 수 있는 생성기 설계와 약한 의미적 감독을 도입한 준지도 학습이 필요하다고 결론지었다.
