본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
Abstract
본 논문은 기존 image to image 변환 기법들이 두 도메인 간 변환에만 최적화되어 있어, 세 개 이상의 도메인 변환을 위해서는 각 도메인 쌍마다 별도의 모델을 학습해야 한다는 확장성 및 강인성의 한계를 지적한다. 이를 해결하기 위해 저자들은 오직 하나의 모델만으로 다중 도메인 간 이미지 변환을 수행할 수 있는 StarGAN을 제안한다. 이 통합된 모델 아키텍처는 서로 다른 도메인을 지닌 여러 데이터셋을 단일 네트워크에서 동시에 학습할 수 있게 함으로써, 기존 방법 대비 더욱 우수한 변환 이미지 품질을 제공하며 입력 이미지를 사용자가 원하는 어떤 목표 도메인으로도 유연하게 변환할 수 있는 기능을 갖춘다. 얼굴 속성 전환과 얼굴 표정 합성 과제에 대한 실험을 통해 제안 방식의 효과를 실증적으로 입증하였다.
1. Introduction
이 절에서는 image to image 변환 과제의 발전 배경과 기존 접근법의 한계를 체계적으로 서술한다. 먼저 GAN 기반 기법들이 두 도메인 간 변환에서 머리 색깔 변경, 엣지 맵 재구성, 계절 변화 등 다양한 응용으로 성공을 거두었음을 언급한다. 그러나 이러한 기법들이 세 개 이상의 도메인으로 확장될 때는 도메인 쌍마다 별도의 모델을 학습해야 하므로 $k$개의 도메인 간 모든 쌍별 변환을 위해 $k(k-1)$개의 생성기가 필요해 학습 효율이 급격히 떨어진다고 지적한다. 또한, 각 생성기가 두 도메인 데이터만을 사용해 학습하기에 전체 학습 데이터를 충분히 활용하지 못해 생성 이미지 품질이 제한되며, 데이터셋별로 라벨링이 불완전해 서로 다른 데이터셋 도메인을 공동 학습할 수 없다는 비효과성 문제도 있다고 설명한다. 이러한 비효율성과 비효과성이 다중 도메인 변환 작업의 주요 장애물이 되고 있음을 강조한다.
본 논문은 다중 도메인 image to image 변환의 비효율성과 비확장성을 극복하기 위한 StarGAN의 핵심 설계 원리를 제시한다. StarGAN은 입력 이미지와 도메인 라벨을 동시에 받아 단일 제너레이터만으로 모든 도메인 쌍 사이의 매핑을 학습하며, 이때 도메인 라벨은 이진 또는 원-핫 벡터로 표현되어 학습 과정에서 무작위로 생성된 라벨을 통해 다양한 변환을 수행하도록 모델을 훈련시킨다. 또한도메인 라벨에 마스크 벡터를 추가함으로써 서로 다른 데이터셋의 도메인을 공동으로 학습할 수 있게 하여, 레이블이 제공되지 않은 도메인은 무시하고 특정 데이터셋이 제공한 라벨만을 학습함으로써 데이터셋 간 협업 학습이 가능하다. 이로 인해 RaFD 데이터에서 학습한 표정 특징을 CelebA 이미지에 적용하는 등 서로 다른 데이터셋 간 다중 도메인 변환을 성공적으로 수행할 수 있으며, 이는 본 연구가 처음 제시하는 성과이다. 이러한 설계를 바탕으로 StarGAN은 단일 모델로 다중 도메인 변환을 효과적으로 학습하고, 얼굴 속성 전환 및 표정 합성 과제에서 기존 기법을 능가하는 성능을 달성한다.


2. Related Work
Generative Adversarial Networks
GAN은 생성기와 판별기로 구성된 대립 구조를 통해 학습되며, 판별기는 진위 판별 능력을, 생성기는 판별기를 속일 만큼 현실적인 샘플 생성 능력을 각각 강화한다. 이러한 적대적 학습 메커니즘은 이미지 생성, 도메인 간 이미지 변환, 초해상도 복원, 얼굴 합성 등 여러 비전 과제에서 탁월한 성과를 이끌었다. 또한 본 연구의 방법 역시 동일한 적대적 손실을 활용해 생성 이미지의 사실성을 극대화한다는 점을 명시하여, 제안 접근법이 표준 GAN 프레임워크의 장점을 계승하고 있음을 강조한다.
Conitional GANs
조건부 GAN 연구는 생성기와 판별기 모두에 클래스 정보를 주입해 클래스에 종속된 샘플을 생성하는 방식이 널리 사용되었음을 밝힌다. 이어서 조건 신호를 텍스트로 확장해, 주어진 문장과 높은 관련성을 가지는 이미지를 생성하는 접근이 최근에 주목받았음을 언급한다. 이러한 조건부 생성 아이디어는 단순 생성에 그치지 않고 도메인 전이, 초해상도 복원, 사진 편집 등 다양한 비전 과제에 성공적으로 적용되어 왔다. 마지막으로, 본 논문이 제안하는 핵심은 “조건부 도메인 정보”를 활용해 이미지 번역의 목표 도메인을 유연하게 제어할 수 있는, 확장 가능한 GAN 프레임워크라는 점으로, 다종의 목표 도메인에 대해 조향 가능성을 높이는 것을 목표로 한다.
Image to Image Translation
본 문단은 이미지-투-이미지 변환의 대표 접근들을 기능과 한계 관점에서 정리한다. 먼저 pix2pix는 cGAN 기반 지도학습으로 적대적 손실과 L1 손실을 결합하며, 그 대가로 정렬된(짝지어진) 데이터가 반드시 필요하다. 데이터 페어 수집의 부담을 줄이기 위해 등장한 UNIT, CycleGAN, DiscoGAN은 비짝지어진 설정을 채택한다. UNIT은 VAE와 가중치 공유 구조의 CoGAN을 결합해 교차 도메인의 결합분포를 학습하고, CycleGAN과 DiscoGAN은 순환 일관성 손실로 입력과 결과 사이의 핵심 속성을 보존한다. 그러나 이들 모두는 설계상 한 번에 두 도메인 사이의 관계만 모델링하므로, 도메인이 여러 개인 상황에서는 도메인 쌍마다 별도의 모델을 따로 학습해야 한다는 확장성의 병목이 존재한다. 이에 비해 저자들이 제안하는 프레임워크는 단일 모델로 다중 도메인 간 관계를 동시에 학습할 수 있음을 주장하며, 바로 이 점이 기존 방법들과의 본질적 차별점으로 제시된다.
3. Star Generative Adversarial Networks
본 문단은 단일 데이터셋 수준의 다중 도메인 변환을 출발점으로 삼고, 이후 다데이터셋·다라벨 설정으로 확장하여 라벨 기반의 조향 가능한 변환 능력을 확보하는 연구 흐름을 제시한다.
3.1 Multi-Domain Image-to-Image Translation
본 문단은 다중 도메인 번역을 위해 단 하나의 생성기 $G$를 학습하는 목표와 그 방식들을 요약한다. 핵심은 생성기가 목표 도메인 레이블 $c$에 조건부가 되도록 설계하여, $G(x, c) \to y$ 형태로 임의의 입력 $x$를 지정된 도메인의 출력 $y$로 변환하게 하는 것이다. 이를 일반화하기 위해 학습 과정에서 $c$를 무작위로 샘플링하여 $G$가 다양한 목표 도메인으로의 변환을 유연하게 익히도록 한다. 한편 판별기 $D$에는 보조 분류기를 결합하여, $D$가 동시에 진위(source: real/fake) 판단과 도메인 레이블 분류를 수행하도록 하며, 그 출력은 $D: x \mapsto \{D_{\mathrm{src}}(x),\, D_{\mathrm{cls}}(x)\}$로 기술된다. 요컨대, 생성기는 조건 $c$를 통해 “무엇으로 바꿀지”를 학습하고, 판별기는 진위와 도메인 정합성 두 신호를 제공함으로써 전체 학습이 다중 도메인에 걸쳐 일관되게 진행되도록 한다.
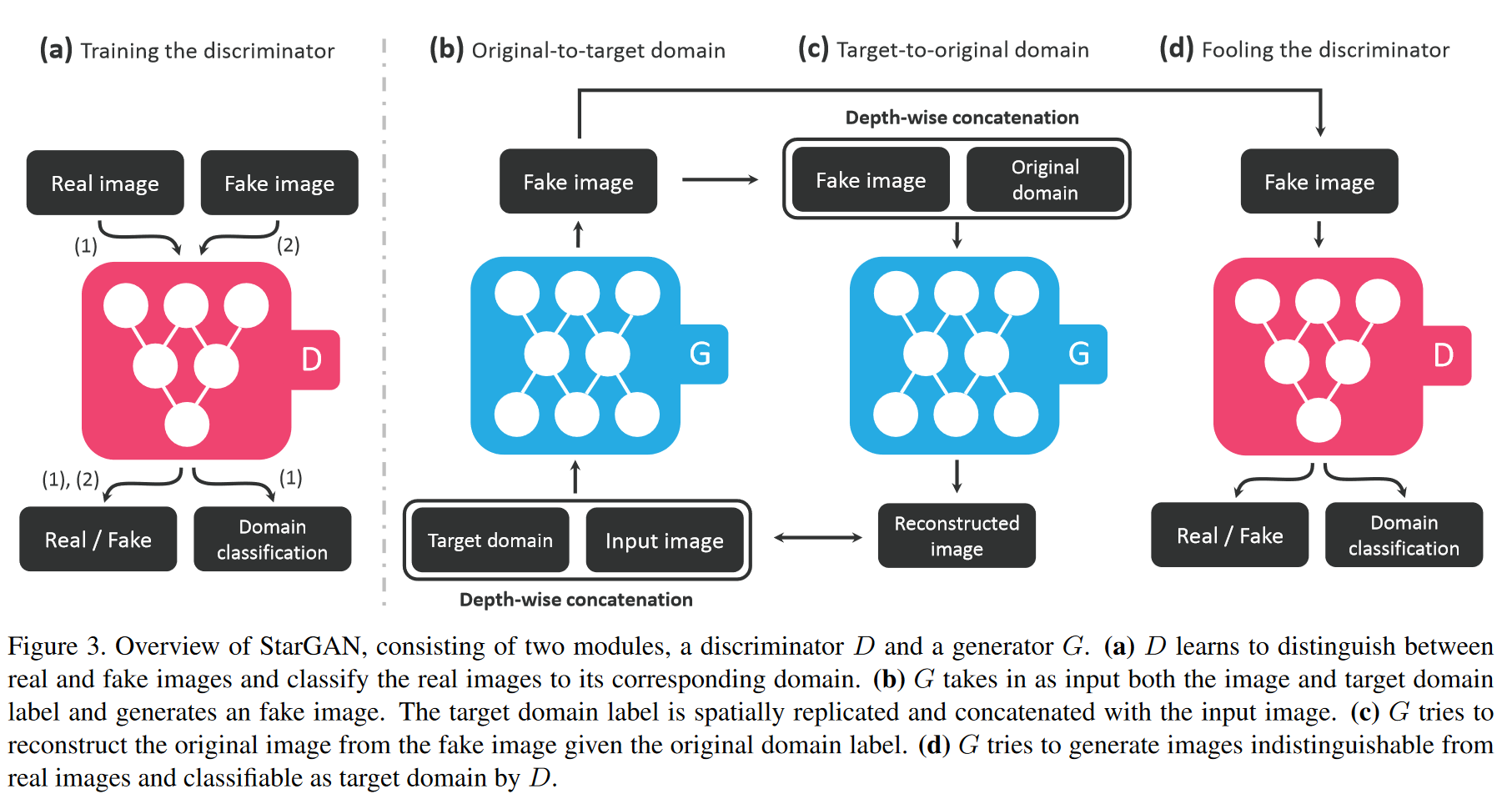
Adversarial Loss
생성된 이미지가 실제 이미지와 구분되지 않도록 만들기 위해, 다음의 적대적 손실을 채택한다:
$$
\mathcal{L}_{\text{adv}}
= \mathbb{E}_{x}\big[\log D_{\mathrm{src}}(x)\big]
+ \mathbb{E}_{x,c}\big[\log\big(1 - D_{\mathrm{src}}(G(x,c))\big)\big], \tag{1}
$$
여기서 $G$는 입력 이미지 $x$와 목표 도메인 레이블 $c$에 모두 조건부로 $G(x,c)$를 생성하고, $D$는 실제와 가짜 이미지를 구분하려 한다. 본 논문에서는 $D_{\mathrm{src}}(x)$를 판별기 $D$가 제공하는 소스(진위) 위의 확률분포로 지칭한다. 생성기 $G$는 위 목적함수를 최소화하려 하고, 판별기 $D$는 이를 최대화하려 한다.
[질문]
G는 G(x,c)가 진짜처럼 보여 D가 ‘진짜’로 판단하게 만들고, D는 G(x,c)를 ‘가짜’로 판별하려는 거지?
[답변]
네, 정확합니다. 주어진 목적식에서는
$$
\min_{G}\max_{D}\ \mathcal{L}_{\text{adv}}
=\mathbb{E}_{x}[\log D_{\mathrm{src}}(x)]
+\mathbb{E}_{x,c}\big[\log\!\big(1-D_{\mathrm{src}}(G(x,c))\big)\big].
$$
* 판별기 $D$: $\mathcal{L}_{\text{adv}}$를 최대화하므로 $D_{\mathrm{src}}(x)\!\to\!1$ (진짜는 진짜), $D_{\mathrm{src}}(G(x,c))\!\to\!0$ (가짜는 가짜)로 만들려 합니다.
* 생성기 $G$: $\mathcal{L}_{\text{adv}}$를 최소화하므로 $D_{\mathrm{src}}(G(x,c))\!\to\!1$ 쪽으로 밀어, 생성물이 진짜처럼 보이게 만듭니다.
참고로 실무에선 같은 의도를 더 강한 그라디언트로 얻기 위해 $G$에 비포화(non-saturating) 손실
$$
\mathcal{L}^{(G)}_{\text{ns}}=-\mathbb{E}_{x,c}\big[\log D_{\mathrm{src}}(G(x,c))\big]
$$
을 쓰기도 합니다. 의도는 동일하게 “가짜를 진짜처럼 보이게”입니다.
Domain Classification Loss
도메인 분류 손실. 주어진 입력 이미지 $x$와 목표 도메인 레이블 $c$에 대해, 목표는 $x$를 목표 도메인 $c$로 올바르게 분류되는 출력 이미지 $y$로 번역하는 것이다. 이를 만족시키기 위해 판별기 $D$ 위에 보조 분류기를 추가하고, $D$와 $G$를 최적화할 때 도메인 분류 손실을 부과한다. 즉, 목적함수를 두 부분으로 나눈다: $D$를 최적화할 때 사용하는 실제 이미지의 도메인 분류 손실과, $G$를 최적화할 때 사용하는 가짜 이미지의 도메인 분류 손실이다. 구체적으로, 전자는
$$
\mathcal{L}^{r}_{\mathrm{cls}}=\mathbb{E}_{x,c'}\!\left[-\log D_{\mathrm{cls}}(c'\mid x)\right], \tag{2}
$$
로 정의되며, 여기서 $D_{\mathrm{cls}}(c'\mid x)$는 $D$가 계산한 도메인 레이블에 대한 확률분포를 의미한다. 이 목적함수를 최소화함으로써, $D$는 실제 이미지 $x$를 그 원래 도메인 $c'$로 분류하도록 학습된다. 저자들은 학습 데이터가 쌍 $(x,c')$를 제공한다고 가정한다. 한편, 가짜 이미지의 도메인 분류 손실은
$$
\mathcal{L}^{f}_{\mathrm{cls}}=\mathbb{E}_{x,c}\!\left[-\log D_{\mathrm{cls}}(c\mid G(x,c))\right] \tag{3}
$$
로 정의된다. 다시 말해, $G$는 이 목적함수를 최소화하여 생성 이미지가 목표 도메인 $c$로 분류되도록 유도된다.
Reconstruction Loss
적대적 손실과 분류 손실을 최소화함으로써, $G$는 현실적이며 올바른 목표 도메인으로 분류되는 이미지를 생성하도록 학습된다. 그러나 이러한 손실(식 (1)과 (3))만 최소화하는 것으로는, 변환된 이미지가 입력의 도메인 관련 부분만 바꾸고 입력 이미지의 내용은 보존한다는 보장이 없다. 이 문제를 완화하기 위해, 우리는 생성기에 순환 일관성 손실[9, 33]을 적용하며 다음과 같이 정의한다:
$$
\mathcal{L}_{\mathrm{rec}}
= \mathbb{E}_{x,c,c'}\!\left[\left\lVert x - G\big(G(x,c),\,c'\big)\right\rVert_{1}\right], \tag{4}
$$
여기서 $G$는 변환된 이미지 $G(x,c)$와 원래 도메인 라벨 $c'$를 입력으로 받아 원본 이미지 $x$를 복원하려고 한다. 우리는 $\ell_1$ 노름을 재구성 손실로 채택한다. 주목할 점은, 단일 생성기를 두 번 사용한다는 것이다. 먼저 원본 이미지를 목표 도메인의 이미지로 변환하고, 이어서 변환된 이미지로부터 원본 이미지를 재구성한다.
“norm(노름)”의 뜻 핵심 정리
1. 의미
노름은 벡터(또는 행렬)의 “크기”를 재는 함수예요. 벡터공간 $V$에서 함수 $\|\cdot\|:V\to[0,\infty)$가 다음을 만족하면 노름이라고 합니다.
$$
\begin{aligned}
&\text{(양의성)} && \|x\|\ge 0,\quad \|x\|=0 \Leftrightarrow x=0,\\
&\text{(동차성)} && \|\alpha x\|=|\alpha|\,\|x\|,\\
&\text{(삼각부등식)} && \|x+y\|\le \|x\|+\|y\|.
\end{aligned}
$$
2. 대표적인 벡터 노름
$$
\|x\|_1=\sum_i |x_i|,\quad
\|x\|_2=\Big(\sum_i x_i^2\Big)^{1/2},\quad
\|x\|_\infty=\max_i |x_i|.
$$
예: $x=(3,4)$라면 $\|x\|_1=7,\ \|x\|_2=5,\ \|x\|_\infty=4$.
좀 더 일반적으로 $p\ge 1$에 대해
$$
\|x\|_p=\Big(\sum_i |x_i|^p\Big)^{1/p}.
$$
3. 행렬 노름(두 가지 자주 쓰는 것)
* 유도(연산자) 노름: 어떤 벡터 노름 $\|\cdot\|$에 대해
$$
\|A\|=\sup_{\|x\|=1}\|Ax\|.
$$
* 프로베니우스 노름:
$$
\|A\|_F=\sqrt{\sum_{i,j} a_{ij}^2}.
$$
4. 유용성
* 거리 정의: $d(x,y)=\|x-y\|$는 항상 metric이 됩니다.
* 머신러닝에서 손실/패널티로 사용: 예를 들어 재구성 손실에 $\|x-\hat x\|_1$ (L1), 정칙화에 $\lambda\|w\|_1$ 또는 $\lambda\|w\|_2^2$ 등.
5. “정규화(normalization)”와 구분
* 노름: “크기를 재는 함수” 그 자체.
* 정규화: 노름을 이용해 크기를 1로 맞추는 과정(예: $\hat x=x/\|x\|_2$).
둘은 개념이 달라요. 그래서 $L_1$ norm은 “$L_1$ 노름”이지 “정규화”가 아닙니다.
Full Objective
마지막으로, 생성기 $G$와 판별기 $D$를 최적화하기 위한 목적함수는 각각 다음과 같이 쓴다:
$$
\mathcal{L}_{D} = -\mathcal{L}_{\text{adv}} + \lambda_{\text{cls}}\ \mathcal{L}^{r}_{\text{cls}}, \tag{5}
$$
$$
\mathcal{L}_{G} = \mathcal{L}_{\text{adv}} + \lambda_{\text{cls}}\ \mathcal{L}^{f}_{\text{cls}} + \lambda_{\text{rec}}\ \mathcal{L}_{\text{rec}}, \tag{6}
$$
여기서 $\lambda_{\text{cls}}$와 $\lambda_{\text{rec}}$는 각각 적대적 손실과 비교했을 때 도메인 분류 손실과 재구성 손실의 상대적 중요도를 조절하는 하이퍼파라미터이다. 본 논문의 모든 실험에서는 $\lambda_{\text{cls}}=1$, $\lambda_{\text{rec}}=10$을 사용한다(※).
각 손실항에 가중치(하이퍼파라미터) $\lambda_{\text{cls}}$와 $\lambda_{\text{rec}}$를 곱해 균형을 조절한다.
$$
\mathcal{L}_{D}=-\mathcal{L}_{\text{adv}}+\lambda_{\text{cls}}\mathcal{L}^{r}_{\text{cls}},\qquad
\mathcal{L}_{G}=\mathcal{L}_{\text{adv}}+\lambda_{\text{cls}}\mathcal{L}^{f}_{\text{cls}}+\lambda_{\text{rec}}\mathcal{L}_{\text{rec}}.
$$
의도는 세 축—사실성(적대적 손실), 목표 도메인 정합성(분류 손실), 내용 보존(재구성 손실)—의 비중을 데이터와 과제에 맞게 조율하는 것이다. 논문에서는 $\lambda_{\text{cls}}=1,\ \lambda_{\text{rec}}=10$을 사용하였다.
실무적으로 $\lambda_{\text{rec}}$를 늘리면 원본 내용 보존이 강해지지만 변환 강도가 약해질 수 있고, $\lambda_{\text{cls}}$를 늘리면 목표 속성은 정확해지지만 시각적 아티팩트가 늘 수 있어 둘을 적절히 조절하며 튜닝해야 한다.
3.2. Training with Multiple Datasets
본 문단은 StarGAN의 강점과 그에 따르는 어려움을 함께 지적한다. 강점은 서로 다른 라벨 체계를 가진 여러 데이터셋을 동시에 활용하여 학습하고, 시험 단계에서 모든 라벨을 제어할 수 있다는 점이다. 반면 난점은 각 데이터셋의 라벨이 부분적이라는 사실로, 대표적으로 CelebA는 속성(머리 색, 성별)은 있지만 표정 라벨이 없고, RaFD는 반대로 표정은 있지만 속성 라벨이 없다. 이러한 불완전성은 번역 결과 $G(x, c)$에서 원본 $x$를 복원할 때 필요한 레이블 벡터 $c'$의 완전한 정보가 확보되지 않는 상황을 초래하며, 따라서 재구성 단계(식 (4))에서 필수 조건을 충족하기 어렵다는 문제를 낳는다.
Mask Vector
본 문단은 서로 다른 라벨 체계를 가진 다중 데이터셋 학습에서 발생하는 부분 라벨 문제를 해결하기 위해 마스크 벡터 $m$을 도입하는 절차를 제시한다. $m$은 데이터셋 수 $n$에 맞춘 $n$차원 원-핫 벡터로, 어떤 데이터셋의 레이블이 현재 명시적으로 제공되는지를 표시해 지정되지 않은 레이블을 무시하게 한다. 이를 기반으로 통합 라벨 $\tilde{c}=[c_1,\ldots,c_n,m]$를 정의하여, 각 데이터셋 전용 라벨 벡터 $c_i$와 마스크 $m$를 한 번에 모델에 전달한다. $c_i$는 속성 유형에 따라 이진 벡터(이진 속성) 또는 원-핫 벡터(범주형 속성)로 표현되며, 제공되지 않은 나머지 $n-1$개 데이터셋의 라벨 벡터는 0으로 채워 비활성화한다. 저자들은 실험에서 CelebA와 RaFD를 사용해 $n=2$인 경우를 다루며, 이 구성으로 모델이 명시된 라벨만 활용하고 미지정 라벨은 무시하도록 설계했음을 강조한다.
$$\tilde{c}=[c_1,\ldots,c_n,m] \tag{7}$$
※[부연설명] StarGAN은 서로 다른 라벨 체계를 가진 여러 데이터셋을 함께 학습하기 위해 마스크 벡터 $m$을 포함한 통합 라벨 $\tilde{c}=[c_1,\dots,c_n,m]$을 사용한다. 여기서 $c_i$는 $i$번째 데이터셋의 라벨 벡터(이진 또는 원-핫)이고, $m$은 길이 $n$의 원-핫 인디케이터로 현재 샘플이 어느 데이터셋에서 왔는지를 표시한다. 한 샘플을 구성할 때는 해당 데이터셋의 라벨 벡터만 실제 값으로 채우고, 나머지 $n-1$개 데이터셋의 라벨 벡터는 모두 0으로 두어 “미지정 라벨”을 비활성화한다. 중요한 점은 $m$이 모르는 라벨을 대체하는 값이 아니라, 모델이 학습·추론 시 어떤 라벨 블록을 신뢰해야 하는지 알려주는 역할을 한다는 것이다. 예를 들어 데이터셋이 두 개이고 라벨 집합이 각각 $\{a,b,c\}$와 $\{f,g,h\}$라면, 데이터셋1의 $a$ 샘플은 $c_1=[1,0,0],\ c_2=[0,0,0],\ m=[1,0]$로, 데이터셋2의 $g$ 샘플은 $c_1=[0,0,0],\ c_2=[0,1,0],\ m=[0,1]$로 표현된다. 결과적으로 $\tilde{c}$는 “각 데이터셋별 라벨 벡터를 나란히 이어 붙이고 마지막에 $m$을 덧붙인” 구조이며, 이 설계를 통해 StarGAN은 지정되지 않은 라벨을 자연스럽게 무시하고 지정된 데이터셋의 라벨만 활용해 다데이터셋 환경에서도 일관된 조건부 변환을 학습할 수 있다.
Training Strategy
본 문단은 다데이터셋 환경에서의 StarGAN 훈련 절차를 제시한다. 생성기에는 통합 레이블 $\tilde{c}$를 입력으로 주어, 값이 0인 미지정 레이블 블록은 무시하고 현재 배치에서 명시된 레이블만 활용하도록 유도한다. 이때 생성기 아키텍처는 단일 데이터셋 학습과 동일하며, 달라지는 것은 오직 $\tilde{c}$의 입력 차원뿐이다. 반면 판별기의 보조 분류기는 모든 데이터셋의 레이블 공간에 대한 확률분포를 출력하도록 확장되지만, 학습은 멀티태스크 방식으로 수행되어 각 배치에서 해당 데이터셋에 대해 알려진 레이블의 오차만 최소화한다. 즉, CelebA 배치에서는 CelebA 속성에만, RaFD 배치에서는 RaFD 표정에만 분류 손실을 적용한다. 이렇게 두 데이터셋을 교대로 투입하면 판별기는 양쪽 데이터셋의 판별적 특징을 모두 학습하고, 생성기는 두 데이터셋의 모든 레이블을 시험 단계에서 제어할 수 있도록 조건부 변환 능력을 익히게 된다.
4. Implementation
Improved GAN Training
훈련 과정을 안정화하고 더 높은 품질의 이미지를 생성하기 위해, 저자들은 식 (1)을 그래디언트 패널티가 포함된 Wasserstein GAN 목표함수로 대체한다. 그 정의는 다음과 같다.
$$
\mathcal{L}_{\mathrm{adv}}
= \mathbb{E}_{x}\!\big[D_{\mathrm{src}}(x)\big]
- \mathbb{E}_{x,c}\!\big[D_{\mathrm{src}}(G(x,c))\big]
- \lambda_{\mathrm{gp}}\ \mathbb{E}_{\hat{x}}\!\left[\left(\left\lVert \nabla_{\hat{x}} D_{\mathrm{src}}(\hat{x})\right\rVert_{2}-1\right)^{2}\right], \tag{8}
$$
여기서 $\hat{x}$는 실제 이미지와 생성 이미지 쌍을 잇는 선분 상에서 균일하게 샘플링된다. 모든 실험에서 $\lambda_{\mathrm{gp}}=10$을 사용한다.
즉, 기존의 로지스틱 형태 적대적 손실(식 (1))을 WGAN-GP 손실로 교체하여 학습을 안정화하고 샘플 품질을 향상시키는 전략을 제시한다. 새 목적식은 비판자(판별기)의 실제 이미지 점수 $\mathbb{E}_{x}[D_{\mathrm{src}}(x)]$를 높이고, 생성 이미지 점수 $\mathbb{E}_{x,c}[D_{\mathrm{src}}(G(x,c))]$를 낮추는 Wasserstein 차이를 최대화하는 한편, $\hat{x}$에서의 그래디언트 노름이 1에 가깝도록 패널티 항 $\lambda_{\mathrm{gp}}\mathbb{E}_{\hat{x}}[(\|\nabla_{\hat{x}}D_{\mathrm{src}}(\hat{x})\|_2-1)^2]$를 부여해 1-Lipschitz 제약을 유도한다. $\hat{x}$는 실제–가짜 사이 선분에서 샘플링되므로 경계 부근에서의 매끄러운 판별 함수를 학습하게 되고, $\lambda_{\mathrm{gp}}=10$으로 가중된 패널티는 그래디언트 폭주나 모드 붕괴를 억제해 더 안정적인 훈련과 높은 시각적 품질을 뒷받침한다.
Network Architecture
생성기는 CycleGAN 계열 구조를 따르며, 두 번의 스트라이드 2 합성곱으로 해상도를 낮춘 뒤, 여섯 개의 잔차 블록을 거쳐 두 번의 스트라이드 2 전치 합성곱으로 해상도를 복원하는 파이프라인을 사용한다. 정규화 전략은 모듈별로 달리 적용되어, 생성기에는 인스턴스 정규화를 쓰고 판별기에는 정규화를 쓰지 않는다. 판별기는 PatchGAN 방식을 채택하여 전체 이미지를 한꺼번에 판단하지 않고, 지역적 패치 단위로 진위 여부를 분류한다.
생성기는 마지막 출력 층을 제외한 전 층에 인스턴스 정규화(IN)를 적용하고, 판별기는 Leaky ReLU 활성함수를 사용하되 음의 기울기를 0.01로 설정한다. 또한 표기 변수들의 의미를 정의한다: nd는 도메인 수, nc는 도메인 레이블 차원으로서 CelebA와 RaFD를 함께 학습할 때만 nd+2가 되며 그 외에는 nd와 같다. 아울러 N(출력 채널 수), K(커널 크기), S(스트라이드), P(패딩), IN(인스턴스 정규화) 약어를 사용함을 명확히 한다.
가령 CelebA에서 제어할 속성 차원(총 수) dA = 5, RaFD 표정 라벨 차원(총 수) dB = 8이라고 하면, nd = dA + dB = 13이 된다. 두 데이터셋을 함께 학습하므로, nc = nd + 2(마스크 길이, [1,0] or [0,1]) = 15 다. 반면 단일 데이터셋만 사용할 경우, dA = 5 -> nd = 5, nc = 5다. 한 개의 데이터셋만 사용시엔 해당 속성 차원이 어떤 데이터셋의 라벨인지 구분할 필요가 없어서 마스크 길이를 사용하지 않는다.


5. Experiments
본 문단은 실험 설계의 세 축과 평가 원칙을 개괄한다. 첫째, 주관적 품질을 평가하기 위해 사용자 연구를 실시하여 얼굴 속성 전환에서 StarGAN을 동시대 기법들과 직접 비교한다. 둘째, 얼굴 표정 합성의 객관적 성능을 확인하기 위해 분류 실험을 수행한다(합성 결과가 올바른 표정 클래스로 분류되는지를 평가하는 맥락). 셋째, StarGAN이 서로 다른 데이터셋들을 활용해 이미지-투-이미지 변환을 학습할 수 있음을 실증적으로 제시한다. 아울러 모든 실험은 학습 시 사용하지 않은 신규 이미지(미본 데이터)에 대한 모델 출력을 기반으로 진행되어, 결과의 일반화 성과(오버피팅 배제)를 강조한다.
5.1 Baseline Models
본 문단은 StarGAN과 비교하기 위한 세 가지 베이스라인의 성격과 학습 방식, 그리고 구조적 요구사항을 정리한다. 첫째, DIAT와 CycleGAN은 모두 “두 도메인 간” 변환에 초점을 맞춘 방법으로, 공정한 비교를 위해 저자들은 도메인 쌍마다 모델을 따로 학습시켜야 했다(확장성의 한계 암시)(※). DIAT는 적대적 학습을 기반으로 하되 얼굴 인식 네트워크 $F$의 특징 공간에서 $\|x - F(G(x))\|_{1}$ 항을 추가하여 원본의 정체성 특징을 보존하는 전략을 쓴다. CycleGAN은 적대적 손실에 더해 순환 일관성 $\|x - G_{Y\to X}(G_{X\to Y}(x))\|_{1}$, $\|y - G_{X\to Y}(G_{Y\to X}(y))\|_{1}$으로 내용 보존을 강제하며, 각 도메인 쌍마다 두 생성기·두 판별기가 필요해 모델 수가 빠르게 늘어난다. 둘째, IcGAN은 cGAN의 생성 매핑 $G(\{z,c\})$ 위에 인코더 $E_z, E_c$를 추가해 입력 이미지에서 잠재 $z$와 조건 $c$를 복원한다(※). 이 구성 덕분에 $z$를 유지한 채 $c$만 바꿔 속성 전환을 수행할 수 있지만, 여전히 “두 도메인/조건” 설정을 기본 단위로 취급한다. 요컨대 세 베이스라인 모두 강점은 있으나, 도메인 쌍마다 별도 학습이 필요하거나(확장성 저하) 조건·순환 제약으로 구조가 무거워지는 특성이 있어, 다중 도메인을 단일 모델로 다루려는 StarGAN의 동기와 대비된다.
기존의 2-도메인 전용 이미지 변환 모델(DIAT, CycleGAN 등)은 한 번의 학습으로 오직 두 개의 도메인 사이에서만 변환을 수행할 수 있다. 따라서 전체 도메인 수가 $K$개일 경우, 가능한 모든 도메인 간 변환을 학습하려면 각 도메인 쌍마다 별도의 모델을 학습해야 한다. 여기서 도메인 간 변환은 방향성을 가지므로, 예를 들어 $A \to B$ 변환과 $B \to A$ 변환은 서로 다른 매핑으로 취급된다. 이 때문에 필요한 모델의 개수는 순열 공식 $P(K, 2) = K \times (K - 1)$로 계산되며, 도메인 수가 7개인 경우 총 42개의 모델이 필요하다. 이러한 구조는 도메인 수가 늘어날수록 모델 수가 기하급수적으로 증가하는 비효율성을 초래한다. StarGAN은 이러한 문제를 해결하기 위해, 모든 도메인 간 매핑을 단일 생성기와 판별기에서 처리할 수 있도록 설계되어, $K(K-1)$개의 모델을 학습해야 하는 기존 방식의 한계를 제거한다.
cGAN은 잠재 벡터 $z$와 조건 벡터 $c$를 입력으로 받아 이미지를 생성하는 구조를 가진다. 이때 $z$는 학습 과정에서 실제 데이터로부터 추출되는 것이 아니라, 주로 정규분포와 같은 사전 정의된 확률분포에서 무작위로 샘플링된다. 이러한 특성 때문에 특정한 이미지를 재생성하거나 그 이미지의 속성만 변경하려 할 때, 해당 이미지에 대응하는 $z$ 값을 알 수 없어 동일한 정체성을 유지한 채 속성만 바꾸는 것이 어렵다.
이 한계를 보완하기 위해 IcGAN은 기존 cGAN 위에 두 개의 인코더를 추가한다. 첫 번째 인코더 $E_z$는 입력 이미지로부터 잠재 벡터 $z$를 복원하고, 두 번째 인코더 $E_c$는 해당 이미지의 조건 벡터 $c$를 추출한다. 이를 위해 IcGAN은 입력 이미지와 속성 라벨을 학습 데이터로 사용하며, 생성기 $G$가 무작위 $z$와 $c$로 이미지를 생성하는 **정방향 경로**와, 생성된 이미지 및 실제 이미지를 $E_z$·$E_c$에 통과시켜 각각 $z'$와 $c'$를 복원하는 **역방향 경로**를 함께 학습한다. 이때 학습 목표는
$$
z' \approx z, \quad c' \approx c
$$
를 만족시키는 것이며, 손실 함수는 $z$ 복원 손실, $c$ 복원 손실, 그리고 cGAN의 적대적 손실을 함께 최적화한다.
이러한 설계를 통해 IcGAN은 원본 이미지에서 정체성을 결정하는 잠재 표현 $z$와 속성을 나타내는 조건 $c$를 분리해 얻을 수 있으며, $z$는 고정한 채 $c$만 변경하여 $G(z, c')$ 형태로 이미지를 다시 생성함으로써 동일한 인물이나 사물의 속성만 바꾼 이미지를 만들 수 있다. 그러나 IcGAN 역시 기본 단위가 “두 도메인 간 전환”이므로, 다중 도메인 학습에는 여전히 한계가 있다.
5.2 Datasets
StarGAN의 실험에 사용된 두 주요 데이터셋(CelebA와 RaFD)의 구성과 전처리 절차를 설명한다. CelebA는 총 202,599장의 셀러브리티 얼굴 이미지를 포함하고, 각 이미지에 대해 40개의 이진 속성 라벨이 존재한다. 실험에서는 이미지 크기를 178×178로 크롭 후 128×128로 리사이즈하고, 무작위로 2,000장을 테스트 세트로, 나머지를 학습에 사용하였다. 또한, 머리 색(3종), 성별(2종), 나이(2종) 속성을 조합하여 총 7개의 도메인을 정의하였다.
RaFD는 67명의 피실험자로부터 수집된 4,824장의 얼굴 이미지로 구성되며, 각 인물은 8가지 표정을 3가지 시선 방향과 3가지 촬영 각도로 재현한다. 모든 이미지는 얼굴이 중앙에 위치하도록 256×256으로 크롭하고, 이후 128×128로 리사이즈하여 실험에 사용한다.
5.3 Training
본 문단은 학습 설정 전반을 명시한다. 최적화는 Adam($\beta_1=0.5, \beta_2=0.999$)을 채택하고, 데이터 증강으로 수평 플립을 확률 0.5로 적용한다. 업데이트 스케줄은 판별기 5회당 생성기 1회로 비율을 두어(5:1) 안정적 훈련을 도모하며, 배치 크기는 일관되게 16을 사용한다. 학습률 스케줄은 데이터셋별로 다르게 설정된다. CelebA는 10 에폭 동안 $\text{lr}=10^{-4}$ 고정 후, 다음 10 에폭에 걸쳐 선형 감쇠로 0까지 낮춘다(총 20 에폭). 반면 표본 규모가 작은 RaFD는 동일 초기 학습률(0.0001)로 100 에폭을 학습하고, 추가 100 에폭 동안 같은 방식으로 선형 감쇠를 적용해 총 200 에폭을 수행함으로써 데이터 부족을 보완한다. 모든 실험은 단일 NVIDIA Tesla M40에서 수행되며, 전체 학습 시간은 약 1일 정도로 보고된다.
5.4 Experimental Results on CelebA
저자들은 단일·다중 속성 전이 과제에서 StarGAN을 기존 베이스라인들과 체계적으로 비교하였다. 먼저 DIAT와 CycleGAN처럼 “두 도메인 전용” 교차 도메인 모델은 가능한 모든 속성 값 쌍에 대해 각각 별도의 모델을 여러 번 학습시켰고, 다중 속성 전이는 머리색을 바꾼 뒤 성별을 바꾸는 식의 다단계 번역으로 처리했다. 반면 StarGAN은 목표 도메인 라벨을 무작위로 샘플링하며 멀티태스크 학습을 수행해, 고정된 한 쌍의 변환에 과적합되기보다 다양한 라벨 조합에 공통적으로 유효한 표현을 학습한다. 그 결과 정성 평가에서 StarGAN은 테스트 셋에서 더 자연스럽고 안정적인 전이 품질을 보였고, IcGAN 대비 얼굴 정체성 보존에서도 우위를 보였는데, 이는 IcGAN의 저차원 잠재 벡터 대신 합성곱 활성화 맵을 잠재 표현으로 사용해 공간 정보를 유지했기 때문이라고 저자들은 추정한다. 정량 평가는 Amazon Mechanical Turk 기반 사용자 연구 두 건으로 수행되었으며(단일 전이: 검증된 참여자 146명, 다중 전이: 100명), 참여자들은 지각적 사실성·전이 품질·정체성 보존을 기준으로 네 방법의 결과 중 최적을 선택했다. StarGAN은 모든 설정에서 최다 득표를 기록했으며, 단일 속성(예: 성별)에서는 격차가 비교적 작았지만, 다중 속성 전이(예: 성별+나이)에서는 큰 폭으로 경쟁 모델을 앞서 StarGAN의 다속성 처리 강점이 분명히 드러났다. 이러한 성과는 학습 단계에서 **임의의 목표 라벨을 지속적으로 주입**해 다중 속성 변화를 일관되게 학습하는 StarGAN의 훈련 전략에서 비롯된다.

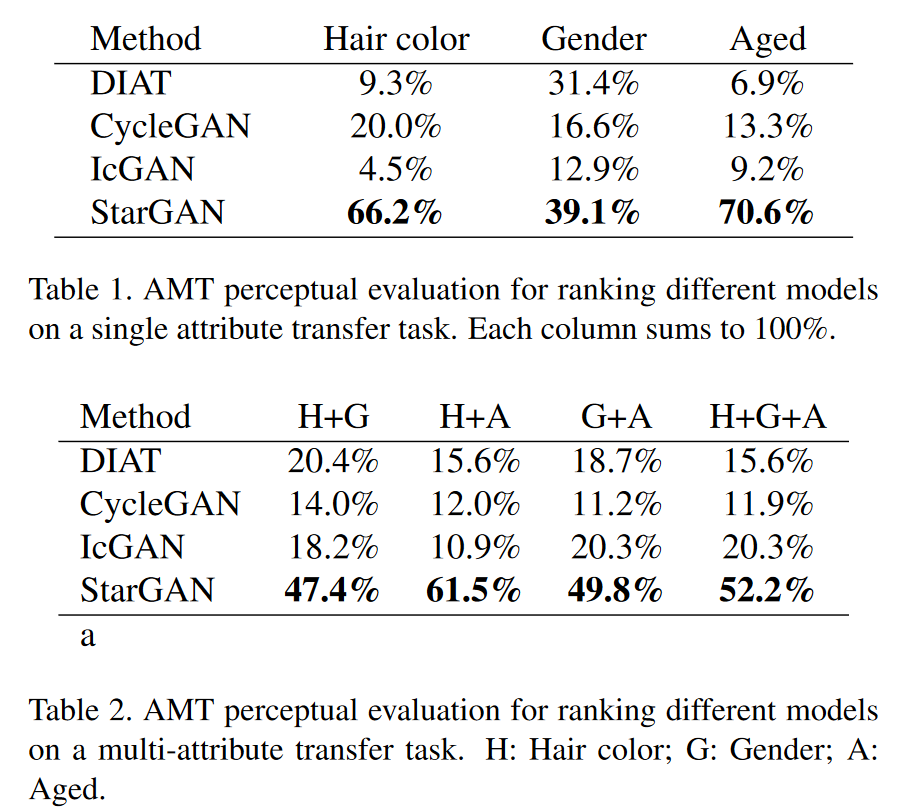
5.5. Experimental Results on RaFD
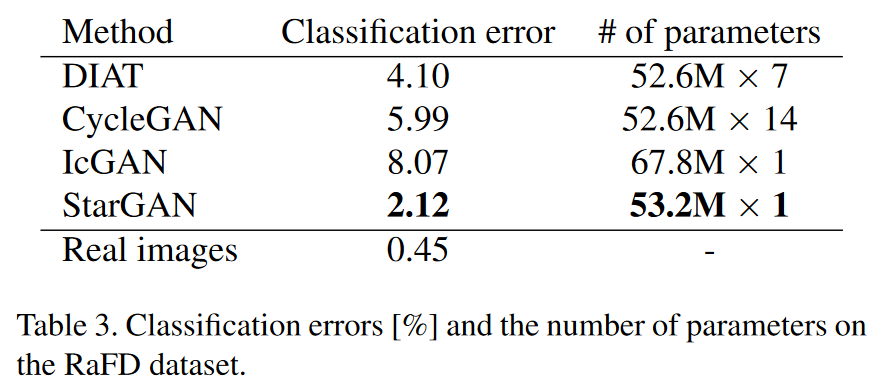
본 문단은 RaFD에서의 표정 합성 실험을 통해 StarGAN의 장점을 정성·정량·자원 측면에서 입증한다. 실험 설계는 입력을 중립 표정으로 고정하고 목표를 7개 표정으로 설정하여 공정 비교를 보장했다. 정성 결과에서 StarGAN은 정체성과 얼굴 특징을 유지하면서 가장 자연스럽고 선명한 출력을 내는 반면, DIAT·CycleGAN은 흐릿함이 잦고, IcGAN은 정체성 붕괴 사례까지 보였다. 이는 도메인당 500장 수준의 소규모 데이터셋에서 StarGAN이 멀티태스크 학습으로 모든 도메인의 4,000장을 동시에 활용해 암묵적 데이터 증강 효과를 누린 데 기인한다. 정량 평가에서는 RaFD로 학습한 고정 분류기(ResNet-18, 99.55% 정확도)를 이용해 합성 이미지의 표정을 판정했으며, StarGAN이 최저 분류 오차로 가장 현실적인 표정 합성을 달성했다. 마지막으로 파라미터 규모 비교에서 StarGAN은 단일 모델로 모든 변환을 처리하므로, 도메인 쌍마다 별도 모델을 갖춰야 하는 DIAT·CycleGAN 대비 각각 7배, 14배 더 효율적임을 보여 확장성 우위까지 입증한다.

5.6. Experimental Results on CelebA+RaFD
본 문단은 다데이터셋 공동 학습과 마스크 벡터의 작동 원리를 실험으로 입증한다. 저자들은 CelebA·RaFD를 함께 학습한 StarGAN-JNT와, RaFD 단독으로 학습한 StarGAN-SNG를 대비시켜, CelebA 표정 합성에서 JNT가 더 선명하고 자연스러운 표정을 생성함을 보인다. 이는 JNT가 두 데이터셋을 아우르며 얼굴 키포인트·분할 같은 저수준 표현을 더 풍부하게 학습하기 때문으로 해석된다. 이어서 마스크 벡터 실험을 통해, 표정 레이블이 두 번째 데이터셋(RaFD)에 속할 때 올바른 마스크 $[0,1]$을 주면 표정 합성이 제대로 수행되는 반면, 잘못된 마스크 $[1,0]$을 주면 모델이 표정을 무시하고 나이 속성을 조작함을 보여준다. 이는 마스크가 “현재 배치에서 어느 데이터셋의 라벨이 유효한지”를 명시해, 미지정 라벨 블록(0 벡터)을 무시하고 지정된 라벨만 반영하도록 역할을 수행한다는 증거다. 종합하면, StarGAN은 마스크 벡터를 통해 다데이터셋의 라벨 공간을 일관되게 통제하며, 공동 학습을 통해 저수준 표현 학습이 강화되어 표정 합성 품질이 유의미하게 향상된다.


6. Conclution
결론적으로 StarGAN의 핵심 기여를 세 가지로 요약할 수 있다. 첫째, 단일 G–D 구성으로 다수 도메인 간 변환을 수행하는 확장성을 확보했다. 둘째, 멀티태스크 학습을 통해 도메인 전반에 통용되는 표현을 학습하여, 기존 기법 대비 더 높은 시각적 품질을 달성했다. 셋째, 마스크 벡터를 도입해 서로 다른 라벨 체계를 가진 복수 데이터셋을 공동 활용할 수 있게 함으로써, 가용한 모든 라벨을 일관되게 제어할 수 있도록 했다. 요컨대 StarGAN은 모델 수·학습 비용을 줄이면서 품질을 높이고, 데이터셋 경계를 넘나드는 응용 가능성을 넓힌 접근으로 제시된다.
