본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
Abstract
현재까지 기계 번역 분야에서 주류를 이루던 모델은 인코더와 디코더를 포함한 RNN 또는 CNN 기반 구조였으며, 최상위 성능 모델들도 인코더-디코더 사이에 attention 매커니즘을 적용해 왔다. Transformer 모델은 오직 attention 만으로 구성된 단순한 네트워크 구조를 제안하여, 기존 연구 문헌상의 최상위 모델들보다 학습 비용을 절감하면서 더 우수한 성능을 보였으며, 일반화 능력 역시 뛰어남을 입증하였다.
- WMT2014 영어_독일어 번역 과제에서 28.4 BLUE를 기록: 기존 최고치 대비 2 BLEU 이상 개선
- WMT2014 영어_프랑스 번역 : 8개의 GPU로 3.5일 학습하여 41.8 BLEU를 달성
- Engilish constituency parsing 과제 성공적으로 적용
1. Introduction
재귀 신경망(Recurrent Neural Network, RNN), 특히 장단기 메모리(Long Short-Term Memory, LSTM)와 게이트 순환 유닛(Gated Recurrent Unit, GRU) 기반 모델은 언어 모델링(language modeling) 및 기계 번역(machine translation)과 같은 시퀀스 모델링(sequence modeling) 및 시퀀스-트랜스덕션(transduction) 문제에서 오랫동안 학계의 최첨단(state-of-the-art) 접근법으로 확립되어 왔으며, 이후에도 수많은 연구가 이러한 재귀 언어 모델과 인코더-디코더 아키텍처의 성능을 지속적으로 개선해 왔다. 그러나 RNN 계열 모델은 입력 및 출력 시퀀스의 각 기호 위치를 시간 단계에 맞춰 순차적으로 출력하기 때문에, 각 시점 t에서 은닉 상태 $h_t$ 는 이전 시점의 은닉 상태 $h_{t-1}$ 와 해당 시점의 입력 $X_(t)$ 의 함수로 계산되어야만 하며, 이러한 순차적인 계산 특성은 훈련시 연산 병렬화를 원천적으로 제한한다.
최근 연구에서는 factorization과 conditional computation을 통해 연산 효율을 획기적으로 개선하고, 모델 성능을 동시에 향상시키는 시도가 이어졌으나, 궁극적으로 "순차적 계산"이라는 근본적인 제약은 여전히 남아 있었다. 한편, 어텐션(attention) 매커니즘은 입력 및 출력 시퀀스 내 장거리(long-distance) 의존성을 효율적으로 포착할 수 있어, 여러 시퀀스 모델 및 트랜스덕션 모델에서 필수적인 요소로 자리잡았지만, 대부분의 경우 어텐션(attention)은 여전히 RNN 네트워크와 결합해 사용되었다.
본 논문에서는 재귀(RNN)와 합성곱(CNN)을 전혀 사용하지 않고, 오직 어텐션(attention) 매커니즘만을 기반으로 전역적(global) 의존 관계를 모델링하는 새로운 네트워크 구조인 Transformer를 제안한다.
2. Background
순차적 연산(sequential computation)을 줄이려는 목표는 Extended Neural GPU (Kalchbrenner et al., 2016), ByteNet (Kalchbrenner et al., 2016), ConvS2S (Gehring et al,, 2017)의 기본 원리를 형성하며, 이들 모델은 모두 CNN을 기본 building block으로 사용하여, 입력 및 출력의 모든 위치에 대해 은닉 표현(hidden representation, hidden vector)를 병렬로 계산한다. 그러나 ConvS2S 에서는 두 임의의 위치간 신호를 연결하는데 필요한 연산 수가 거리(distance)에 따라 선형적으로 증가하고, ByteNet에서는 로그 함수에 따라 증가(logarithmically)하기 때문에, 장거리 의존성(long-distance dependencies)을 학습하기 어려운 문제를 내포하고 있다. Transformer는 이러한 연산을 위치간 거리와 무관하게 일정한 수로 감소시키지만, 어텐션(attention) 가중치가 반영된 위치들(attention-weighted positions)을 평균함으로써, 유효 해상도(effective resolution)가 감소하는 단점이 발생(3.2 Scaled Dot-Product Attention 에서 자세하게 언급)했다.
이를 보완하기 위해 3.2절에서 설명하는 Multi-Head attention을 도입하였다. Self-Attention, 때로는 intra-attention이라고도 불리는 이 메커니즘은 단일 시퀀스(sequence) 내 서로 다른 위치(position) 관계를 고려하여, 시퀀스(sequence)의 표현(representation)을 계산하며, 독해(reading comprehension), 추상적 요약(abstractive summarization), 텍스트 함축(textual entailment), 태스크 독립 문장 표현 학습(task-independent sentence representation learning) 등의 과제에서 성공적으로 사용되었다. 또한, Sukbaatar et al. (2015)의 End-to-end Memory Network는 sequence-aligned recurrence 대신 recurrent attention mechanism을 기반으로 하며, simple-language question answering 및 language modeling 과제에서 우수한 성능을 보였다. 하지만 우리가 아는 한, Transformer는 sequence-aligned RNN 이나 convolution을 전혀 사용하지 않고, 오직 Self-Attention만으로 입력과 출력을 표현하는 최초의 transduction 모델이다.
[추가]
장거리 의존성이란? 자연어 문장에서 서로 멀리 떨어진 단어들 사이에서도 의미적·문법적으로 강한 관계가 나타나는 것을 지칭한다. 예를 들어, "그 호수는, 달빛을 받아 은은하게 빛나고 있어서 매우 매력적이야" 라는 문장에서 호수와 매력적이야는 멀리 떨어져있지만, 주어 ·동사관계다. 이런 관계를 놓치면 문장의 의미를 이해하기 어렵게 된다.
3 Model Architecture
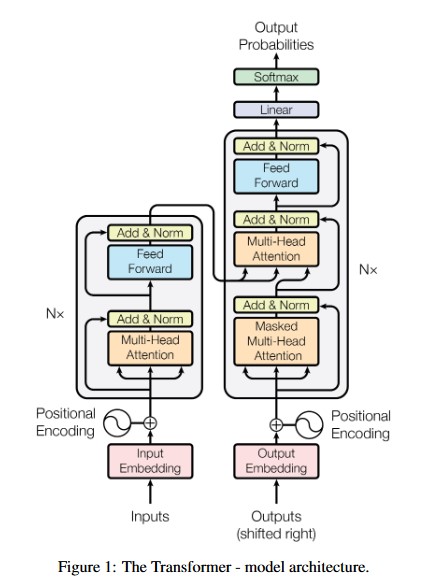
다수의 경쟁력 있는 신경망 기반 시퀀스 변환 (neural sequence transduction, 딥러닝 신경망을 이용해 입력 시퀀스를 다른 출력 시퀀스로 변환하는 기술 ) 모델은 인코더-디코더 구조를 갖고 있으며, 여기서 인코더는 기호 표현 $(x_1, x_2, ..., x_n)$ 의 입력 시퀀스를 연속 표현인 z = $(z_1, z_2, ...., z_n)$ 로 매핑한다. 이렇게 얻은 z를 바탕으로 디코더는 출력 시퀀스 $(y_1, y_2, ...., y_n)$ 를 한 번에 한 기호씩 생성하며, 이 과정에서 자기회귀적(auto-regressive)하게 "이전까지 생성된 출력 기호들 $(y_1, y_2, ...., y_n)$"을 추가 입력으로 사용해, 다음 기호 $y_t$ 를 예측한다. Transformer는 이와 같은 전통적 인코더-디코더 아키텍처를 따르되, 인코더-디코더 양쪽에 모두 여러 개의 self-attention 블록을 쌓은 뒤, 이어서 position-wise fully connected 층을 적용하여 구현된다.
Input Embedding 과 Positional Encoding 예시
“호수가 매우 고요하다” 문장에 대해 입력 임베딩(word embedding)과 포지셔널 인코딩(positional encoding)을 결합하여 Transformer의 입력 $X$를 얻는 과정을 보여준다.
가정
1. 임베딩 차원: $d_{\mathrm{model}} = 4$.
2. 어휘 집합과 원-핫 인코딩
“호수가”→ 인덱스 0 → $[1,0,0]$
“매우” → 인덱스 1 → $[0,1,0]$
“고요하다”→ 인덱스 2 → $[0,0,1]$
3. 임베딩 행렬 $E \in \mathbb{R}^{3\times4}$
$$
E =
\begin{bmatrix}
0.5488 & 0.7152 & 0.6028 & 0.5449 \\
0.4237 & 0.6459 & 0.4376 & 0.8918 \\
0.9637 & 0.3834 & 0.7917 & 0.5289
\end{bmatrix}
$$
계산
1. 단어 임베딩 계산
각 원-핫 벡터 $h_i$와 임베딩 행렬 $E$의 곱으로,
$$
x_i = h_i\,E,\quad i = 1,2,3.
$$
$$
X_{\mathrm{embed}} =
\begin{bmatrix}
[1,0,0]\,E \\[4pt]
[0,1,0]\,E \\[4pt]
[0,0,1]\,E
\end{bmatrix}
=
\begin{bmatrix}
0.5488 & 0.7152 & 0.6028 & 0.5449 \\[4pt]
0.4237 & 0.6459 & 0.4376 & 0.8918 \\[4pt]
0.9637 & 0.3834 & 0.7917 & 0.5289
\end{bmatrix}.
$$
2. 포지셔널 인코딩 계산
Transformer 원논문 공식( $d_{\mathrm{model}}=4$ ):
$$
\begin{aligned}
\mathrm{PE}(pos,2k) &= \sin\!\Bigl(\tfrac{pos}{10000^{2k/4}}\Bigr),\\
\mathrm{PE}(pos,2k+1) &= \cos\!\Bigl(\tfrac{pos}{10000^{2k/4}}\Bigr),
\end{aligned}
\quad k=0,1;\;pos=0,1,2.
$$
* $k=0$ ($10000^{0/4}=1$) → dims 0,1: $\sin(pos),\cos(pos)$
* $k=1$ ($10000^{2/4}=100$) → dims 2,3: $\sin(pos/100),\cos(pos/100)$
위치별 실제 값
1. $pos=0$:
$\mathrm{PE}_0 = [\,\sin0,\cos0,\sin0,\cos0\,] = [0,1,0,1]$.
2. $pos=1$:
$\mathrm{PE}_1 = [\sin1,\cos1,\sin0.01,\cos0.01]\approx[0.8415,0.5403,0.0100,0.99995]$.
3. $pos=2$:
$\mathrm{PE}_2 = [\sin2,\cos2,\sin0.02,\cos0.02]\approx[0.9093,-0.4161,0.0200,0.99980]$.
$$
P =
\begin{bmatrix}
0 & 1 & 0 & 1 \\[4pt]
0.8415 & 0.5403 & 0.0100 & 0.99995\\[4pt]
0.9093 & -0.4161 & 0.0200 & 0.99980
\end{bmatrix}.
$$
3. 임베딩 + 포지션 인코딩 결합
최종 입력 행렬 $X\in\mathbb{R}^{3\times4}$:
$$
X = X_{\mathrm{embed}} + P
=
\begin{bmatrix}
0.5488 & 0.7152 & 0.6028 & 0.5449\\
0.4237 & 0.6459 & 0.4376 & 0.8918\\
0.9637 & 0.3834 & 0.7917 & 0.5289
\end{bmatrix}
+
\begin{bmatrix}
0 & 1 & 0 & 1 \\
0.8415 & 0.5403 & 0.0100 & 0.99995\\
0.9093 & -0.4161 & 0.0200 & 0.99980
\end{bmatrix}.
$$
토큰별 계산 결과
1. “호수가”:
$$
[0.5488,0.7152,0.6028,0.5449]+[0,1,0,1]
=[0.5488,1.7152,0.6028,1.5449].
$$
2. “매우”:
$$
[0.4237,0.6459,0.4376,0.8918]+[0.8415,0.5403,0.0100,0.99995]
\approx[1.2652,1.1862,0.4476,1.8918].
$$
3. “고요하다”:
$$
[0.9637,0.3834,0.7917,0.5289]+[0.9093,-0.4161,0.0200,0.99980]
\approx[1.8730,-0.0327,0.8117,1.5287].
$$
따라서 최종
$$
X =
\begin{bmatrix}
0.5488 & 1.7152 & 0.6028 & 1.5449\\
1.2652 & 1.1862 & 0.4476 & 1.8918\\
1.8730 & -0.0327& 0.8117 & 1.5287
\end{bmatrix},
$$
이 값이 인코더 입력으로 들어간다.
3.1 Encoder and Decoder Stacks
인코더는 N=6개의 동일한 레이어로 구성되어 있으며, 각 레이어는 두 개의 서브 레이어로 이루어져 있다. 첫 번째 서브 레이어는 Multi-Head Self-Attention 매커니즘이고, 두번째 서브 레이어는 간단한 position-wise fully connected feed-forward network이다. 각 서브 레이어 주변에 residual connection을 적용하고, 그 결과에 대해 Layer Normalization을 수행한다. 즉, 입력 x가 특정 서브 레이어를 통과하면 해당 서브 레이어가 구현한 함수 Sublayer(x)와 원래 입력 x 를 더한 뒤, 그 합에 대해 LayerNorm을 적용한다:
$$\mathrm{output} = \mathrm{LayerNorm}\bigl(x + \mathrm{Sublayer}(x)\bigr)$$
이러한 residual connection을 원활히 구현하기 위해, 모델 내 모든 sub-layer와 embedding layer는 출력 차원을 ${\text{model}}$ = 512로 고정하였다.
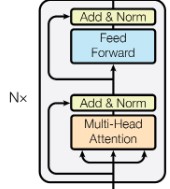
디코더는 N=6개의 동일한 레이어로 구성되어 있다. 각 디코더 레이어는 인코더 레이어와 마찬가지로 두 개의 서브 레이어가 존재하는데, 여기에 인코더 스택의 출력을 대상으로 Multi-Head Attention을 수행하는 세번째 서브 레이어가 추가된다(이미지 가운데 위치한 레이어). 인코더와 마찬가지로, 모든 서브 레이어 주변에는 residual connection을 적용한 뒤 그 결과에 대해 Layer Normalization을 수행한다. 또한 디코더의 self-attention 서브 레이어는 subsequent positions가 참조되지 않도록 마스킹(masking) 한다. 이 마스킹은 "출력 임베딩(output embeddings)이 한 포지션씩 뒤로(offset) 이동되어 있다"는 사실과 결합되어, i 번째 토큰을 예측할 때는 반드시 이전 포지션( x < i)에 해당하는 출력만을 참조하도록 보장한다.
3.2 Attention
어텐션(attention) 함수는 쿼리(query)와 키-값(key-value) 쌍들의 집합을 입력으로 받아, 출력 벡터를 생성하는 방식으로 정의할 수 있다. 여기서 쿼리(query) , 키(key), 값(value), 그리고 출력(output)은 모두 벡터이다. 출력은 값(value) 벡터들의 가중합으로 계산되며, 각 값에 할당되는 가중치는 쿼리와 해당 키 간의 호응도(compatibility function)에 의해 결정된다.
3.2.1 Scaled Dot-Product Attention
우리는 이 어텐션(attention)을 Scaled Dot-Product Attention이라고 부른다. 입력으로는 차원이 d_k인 쿼리(query)와 키(key), 그리고 차원이 $d_v$ 인 값(value) 벡터가 주어진다. 먼저 각 쿼리와 모든 키 간의 내적(dot product)를 계산한 뒤, 그 결과를 $\sqrt{d_k}$ 로 나눈다. 그런 다음 소프트맥스(softmax) 함수를 적용하여, 값 벡터에 대한 가중치(weight)를 얻는다.
실제로, 여러 개의 쿼리를 하나의 행렬 Q에, 키를 행렬 K에, 값을 행렬 V에 각각 모아 동시에 병렬로 계산한다. 이 때 출력 행렬은 다음과 같이 구한다:
$$
\text{Attention}(Q, K, V) = \text{softmax}\Bigl(\tfrac{QK^T}{\sqrt{d_k}}\Bigr)\,V.
$$
가장 널리 쓰이는 두 가지 어텐션(attention) 함수는 additive attention과 dot-product (multiplicative) attention이다. Dot-product attention은 기본적으로 위 수식과 동일하나, $\tfrac{1}{\sqrt{d_k}}$라는 스케일링 계수를 적용하지 않는 점이 다르다. 반면 additive attention은 단일 은닉층을 갖는 feed-forward 네트워크를 이용해 호환도 (compatibility) 함수를 계산한다. 이론적으로 두 방식은 연산 복잡도가 비슷하지만, 실전에서는 dot-product attention이 고도로 최적화된 행렬 곱(matrix multiplication) 코드로 구현될 수 있어, 훨씬 빠르고 메모리도 더 효율적이다. 단 $d_k$ 값이 커지면, dot-product의 크기가 매우 크게 증가해 소프트맥스 출력이 그래디언트가 거의 없는 영역으로 치우치는 문제가 발생한다. 이를 완화하기 위해 내적 결과를 $\sqrt{d_k}$로 나누어 스케일한다.

[추가]
Transformer의 Scaled Dot-Product Attention은 키와 쿼리간 유사도를 계산해 얻은 가중치로 값 벡터들을 가중평균한다는 점에서, 어떤 위치의 정보가 "어떻게" 평균화되어 희석될 수 있는 한계가 있다. 구체적으로 살펴보면:
- 가중합(Weighted Sum)의 특성으로 인한 정보 희석
각 쿼리 $q$ 에 대해 $\alpha_j = \text{softmax}(q \cdot k_j / \sqrt{d_k})$ 형태의 가중치가 계산되면, 최종 출력은
$$
o\text{(attention result vector)}= \sum_{j=1}^n \alpha_j \, v_j
$$
와 같이 여러 값 $v_j$ 벡터를 $\alpha_j$ 비율로 평균한 형태가 된다. 여기서 $v_j$ 는 입력 시퀀스 $j$번째 토큰(또는 이전 레이어 $j$번째 위치)의 정보를 담고 있는 벡터다.
→ 일반적으로, $v_j$ 벡터 를 구하기 위해 입력 시퀀스의 각 위치 $j$에 대해 먼저 “히든 표현(hidden representation)” 혹은 임베딩(embedding) 벡터 $\mathbf{z}_j$를 계산한다. 그 벡터 $\mathbf{z}_j$에 학습된 선형 투영 행렬 $W^V$를 곱해 값 $v_j$을 얻는다: $v_j \;=\; W^V\,\mathbf{z}_j.$ 또한 전체 어텐션(attention) 결과는 $\{o_1, o_2, \dots, o_n\}$ 형태의 벡터 시퀀스가 된다. 따라서 attention result vector는 각 쿼리 $q_i$별 출력 $\,o_i$ 로 구성되며, 이를 하나의 행렬로 정리하면 $n \times d_v$ 크기의 행렬이 된다.
이 때, $\alpha_j$ 들이 분산되어 있으면(여러 위치에 골고루 attention을 둘수록), 특정한 위치의 세밀한 정보가 다른 위치와 함께 섞여서 세부적인 차이를 표현하기 어려워질 수 있다. 예컨대, 두 개의 토큰 $v_2, v_3$ 가 문맥상 거의 비슷한 역할을 하지만 미묘하게 다른 정보를 담고 있을 때, 가중치가 0.5씩 균등하게 부여되면 $0.5\, v_2 + 0.5\,v_3$ 처럼 두 벡터가 섞여 버려, 개별 토큰만의 고유한 특징이 모호해질 수 있다. - 유효 해상도(Effective Resolution)" 감소 문제
이처럼 여러 위치의 정보를 가중 평균하면, "어떤 위치에서 온 정보인지"를 세밀하게 구분하기 어려워지는 현상을 유효 해상도 감소라고 부른다. 특히 값(value) 벡터 하나에 "문장의 문법적·의미적 특징"이 압축되어 있다면, 가중합된 결과는 "중간값(mixture)"처럼 해석되어 버린다. Transformer 논문에 언급된 바와 같이, 단일 헤드(single-head) 로만 attention을 수행하면 유사한 위치 간 정보가 평균되면서 세부 표현력이 떨어질 수 있기 때문에, 다중 헤드(Multi-Head Attention)을 도입하여, 서로 다른 선형 투영(projection) 하위 공간(subspace)에서 병렬로 뽑아낸 후 다시 합치는 방식으로 해상도를 보완한다. - 해결 방법 : Multi-Head Attention
Multi-Head Attention은 서로 다른 $h$개의 선형 투영 행렬 $\{W_i^Q,\,W_i^K,\,W_i^V\}$을 이용해 쿼리·키·값을 각기 $d_k$, $d_k$, $d_v$ 차원으로 변환한 뒤,
$$
\text{head}_i = \text{Attention}\bigl(QW_i^Q,\;K W_i^K,\;V W_i^V\bigr),
$$
를 병렬로 수행한다.
이렇게 하면, 각 헤드가 서로 다른 하위 표현 공간에서 정보를 뽑아오기 때문에, 가중평균 시에도 “다양한 시각에서 본 문맥 정보”가 포착되어, 단일 헤드에서는 평균으로 희석되는 정보를 보완할 수 있다.
[추가] self-attention 계산
예를 들어, 입력 문장이 “호수가 매우 고요하다” 라고 하자. 이 세 토큰에 대해, 원래는 임베딩 후 포지셔널 인코딩까지 더해야 하지만 여기서는 편의상 임의로 생성하고, 차원 $d_{\mathrm{model}}=4$, $d_k=d_v=2$로 임의로 설정하여 Self-Attention 계산 과정을 단계별로 정리한다.
[요약]
“‘호수가 매우 고요하다’ 문장에서 ‘매우’ 토큰의 어텐션 값을 계산하려면, 먼저 학습된 $Q_{\text{매우}}$ 벡터와 ‘호수가’ 및 ‘고요하다’ 토큰의 $K$ 벡터들에 대해 각각 내적을 수행한 뒤, 차원 수 $d_k$의 제곱근으로 나누고 소프트맥스 함수를 적용합니다. 그 결과 얻은 어텐션 가중치들을 ‘호수가’와 ‘고요하다’의 $V$ 벡터에 곱하여 합산한 값이 바로 ‘매우’ 토큰의 셀프어텐션 출력입니다.
[자세한 설명]
“‘호수가 매우 고요하다’ 문장에서 ‘매우’ 토큰의 어텐션 값을 계산하려면, 먼저 학습된 $Q_{\text{매우}}$ 벡터와 ‘호수가’ 및 ‘고요하다’ 토큰의 $K$ 벡터들에 대해 각각 내적을 수행한 뒤, 차원 수 $d_k$의 제곱근으로 나누고 소프트맥스 함수를 적용합니다. 그 결과 얻은 어텐션 가중치들을 ‘호수가’와 ‘고요하다’의 $V$ 벡터에 곱하여 합산한 값이 바로 ‘매우’ 토큰의 셀프어텐션 출력입니다.
1. 입력 임베딩
위에서 구한 입력 임베딩을 사용한다.
$$
\begin{aligned}
x_1 &= [\,0.5488,\;1.7152,\;0.6028,\;1.5449\,]\quad(\text{“호수가”}),\\
x_2 &= [\,1.2652,\;1.1862,\;0.4476,\;1.8918\,]\quad(\text{“매우”}),\\
x_3 &= [\,1.8730,\;-0.0327,\;0.8117,\;1.5287\,]\quad(\text{“고요하다”}).
\end{aligned}
$$
이를 행렬 $X\in\mathbb{R}^{3\times 4}$로 표현하면,
$$
X =
\begin{bmatrix}
x_1 \\[6pt]
x_2 \\[6pt]
x_3
\end{bmatrix}
=
\begin{bmatrix}
0.5488 & 1.7152 & 0.6028 & 1.5449 \\
1.2652 & 1.1862 & 0.4476 & 1.8918 \\
1.8730 & -0.0327 & 0.8117 & 1.5287
\end{bmatrix}.
$$
2. 학습 가능한 가중치 행렬 $W_Q, W_K, W_V$
각각 $\mathbb{R}^{4\times 2}$ 크기로 랜덤 초기화된 뒤 학습되는 파라미터이며, 예시에서는 다음 값을 사용:
$$
W_Q =
\begin{bmatrix}
0.7610 & 0.1217 \\
0.4439 & 0.3337 \\
1.4941 & -0.2052 \\
0.3131 & -0.8541
\end{bmatrix},\quad
W_K =
\begin{bmatrix}
-2.5530 & 0.6536 \\
0.8644 & -0.7422 \\
2.2698 & -1.4544 \\
0.0458 & -0.1872
\end{bmatrix},\quad
W_V =
\begin{bmatrix}
1.5328 & 1.4694 \\
0.1549 & 0.3782 \\
-0.8878 & -1.9808 \\
-0.3479 & 0.1563
\end{bmatrix}.
$$
* 크기: 모두 $4\times 2$.
* 초기값: 예시를 위해 고정된 랜덤 값.
3. Query, Key, Value 계산
$$
q_i = x_i\,W_Q,\quad
k_i = x_i\,W_K,\quad
v_i = x_i\,W_V\quad (i=1,2,3).
$$
행렬 형태:
$$
Q = X\,W_Q,\quad
K = X\,W_K,\quad
V = X\,W_V,
\quad
Q,\,K,\,V \in \mathbb{R}^{3\times 2}.
$$
3.1. 실제 계산 결과
1. $Q = X\,W_Q$
$$
Q =
\begin{bmatrix}
2.5634 & - 0.8040 \\
2.7505 & - 1.1578 \\
3.1022 & -1.2258
\end{bmatrix}.
$$
2. $K = X\,W_K$
$$
K =
\begin{bmatrix}
1.5205 & - 2.0802 \\
-1.1021 & -1.0586\\
-2.8976 & -0.2182
\end{bmatrix}.
$$
3. $V = X\,W_V$
$$
V =
\begin{bmatrix}
0.0342 & 0.5025\\
1.0675 & 1.7168\\
1.6134 & 1.3709
\end{bmatrix}.
$$
4. 스케일된 닷 프로덕트 점수 계산
$$
\tilde{\alpha}_{ij}
= \frac{q_i \cdot k_j^\top}{\sqrt{d_k}}
\quad(d_k = 2).
$$
행렬 형태:
$$
\tilde{\alpha}
= \frac{Q\,K^\top}{\sqrt{2}}
=
\begin{bmatrix}
3.9388 & -1.3958 & -5.1281\\
4.6603 & -1.2768 & -5.4568\\
5.1818 & -1.4780 & -6.1626
\end{bmatrix}.
$$
5. 어텐션 가중치 $\alpha$ 계산 (소프트맥스)
$$
\alpha_{ij}
= \frac{\exp(\tilde{\alpha}_{ij})}{\sum_{m=1}^{3}\exp(\tilde{\alpha}_{im})}.
$$
실제 결과:
$$
\alpha_{11}
= \frac{\exp(3.93388)}{\exp(3.93388)+\exp(-1.3958)+\exp(-5.1281)}
\approx 0.9951.
$$
$$
\alpha
=
\begin{bmatrix}
0.9951 & 0.0048 & 0.0001\\
0.9973 & 0.0026 & 0.0001\\
0.9987 & 0.0013 & 0.0000
\end{bmatrix}.
$$
6. Self-Attention 최종 출력
$$
z_i
= \sum_{j=1}^{3} \alpha_{ij}\,v_j,
\quad
Z = \alpha\,V \in \mathbb{R}^{3\times 2}.
$$
실제 결과:
$$
Z
=
\begin{bmatrix}
0.0394 & 0.5085\\
0.0370 & 0.5058\\
0.0356 & 0.5041
\end{bmatrix}.
$$
* 최종 결과
z_1 = 0.9951* [ 0.0342, 0.5025 ] - 0.0048 * [ 1.0675, 1.7168] - 5.13 * [ 1.6134, 1.3709] = [0.0394, 0.5085]
import numpy as np
# 1. 입력 임베딩 (Word Embedding)
# 어휘 크기 3, 임베딩 차원 4
E = np.array([
[0.5488, 0.7152, 0.6028, 0.5449], # "호수가"
[0.4237, 0.6459, 0.4376, 0.8918], # "매우"
[0.9637, 0.3834, 0.7917, 0.5289] # "고요하다"
])
# 원-핫 벡터
h = np.eye(3)
# 단어 임베딩 계산
X_embed = h.dot(E) # shape (3, 4)
# 2. 포지셔널 인코딩 (Positional Encoding)
d_model = 4
def positional_encoding(max_len, d_model):
PE = np.zeros((max_len, d_model))
for pos in range(max_len):
for k in range(d_model//2):
angle = pos / (10000 ** (2*k / d_model))
PE[pos, 2*k] = np.sin(angle)
PE[pos, 2*k+1] = np.cos(angle)
return PE
P = positional_encoding(max_len=3, d_model=d_model) # shape (3, 4)
# 최종 입력 행렬
X = X_embed + P # shape (3, 4)
# 3. 학습 가능한 가중치 행렬 정의
W_Q = np.array([[0.7610, 0.1217],
[0.4439, 0.3337],
[1.4941, -0.2052],
[0.3131, -0.8541]])
W_K = np.array([[-2.5530, 0.6536],
[0.8644, -0.7422],
[2.2698, -1.4544],
[0.0458, -0.1872]])
W_V = np.array([[1.5328, 1.4694],
[0.1549, 0.3782],
[-0.8878, -1.9808],
[-0.3479, 0.1563]])
# 4. Query, Key, Value 계산
Q = X.dot(W_Q) # shape (3, 2)
K = X.dot(W_K) # shape (3, 2)
V = X.dot(W_V) # shape (3, 2)
# 5. 스케일된 닷 프로덕트 어텐션
d_k = Q.shape[1]
scores = Q.dot(K.T) / np.sqrt(d_k) # shape (3, 3)
weights = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True) # softmax
Z = weights.dot(V) # shape (3, 2)
# 출력
print("X (입력 임베딩 + 포지션 인코딩):\n", X)
print("\nQ:\n", Q)
print("\nK:\n", K)
print("\nV:\n", V)
print("\nScores:\n", scores)
print("\nAttention Weights (alpha):\n", weights)
print("\nSelf-Attention Output Z:\n", Z)[추가]
디코더 블록의 두 번째 어텐션은 인코더–디코더 어텐션(cross-attention)이라고 부른다. 구체적으로:
1. 첫 번째 서브레이어: 디코더 입력(앞단계 출력)에 대해 마스크드(Self-)어텐션을 수행
$$
\mathrm{SelfAttn}(Q_{\text{dec}},\,K_{\text{dec}},\,V_{\text{dec}})
$$
2. 두 번째 서브레이어: 여기서 나오는 쿼리 $Q_{\text{dec}}$와, 인코더에서 계산된 $K_{\text{enc}},V_{\text{enc}}$를 사용하여
$$
\mathrm{CrossAttn}(Q_{\text{dec}},\,K_{\text{enc}},\,V_{\text{enc}})
$$
를 수행한다. 즉,
쿼리: 현재 디코더 스텝의 디코더 내부 표현
키/값: 인코더의 출력 전체를 담고 있는 $K_{\text{enc}},V_{\text{enc}}$
3. 세 번째 서브레이어: Feed-Forward 네트워크
따라서 “디코더의 두 번째 self-attention”이라고 부르는 모듈은 사실 셀프가 아니라 인코더 출력에 집중하는 크로스 어텐션이며,
$$
Q = X_{\text{dec}}W_Q,\quad
K = X_{\text{enc}}W_K,\quad
V = X_{\text{enc}}W_V
$$
를 이용해 scaled-dot-product attention을 계산하게 된다.
3.2.2 Multi-Head Attention

single attention function을 $d_{\text{model}}$-차원 키(key), 값(value), 쿼리(query)에 대해 수행하는 대신, 쿼리, 키, 값을 각각 $d_k$, $d_k$, $d_v$ 차원으로 매번 서로 다른 학습된 선형 투영(linear projection)을 $h$회 수행하는 것이 더 유리함을 발견하였다. 이렇게 투영된 각 쿼리, 키, 값에 대해 병렬로 어텐션(attention)을 계산해 $d_v$-차원 출력값을 얻고, 이 $h$개의 출력값을 이어 붙인 뒤(concatenate) 다시 선형 투영하여 최종 출력을 만든다. 즉,
$$
\mathrm{MultiHead}(Q,K,V)=\mathrm{Concat}(\mathrm{head}_1,\ldots,\mathrm{head}_h)\,W^O,\quad
\mathrm{head}_i=\mathrm{Attention}(QW_i^Q,\;KW_i^K,\;VW_i^V),
$$
여기서 $W_i^Q\in\mathbb{R}^{d_{\text{model}}\times d_k},\,W_i^K\in\mathbb{R}^{d_{\text{model}}\times d_k},\,W_i^V\in\mathbb{R}^{d_{\text{model}}\times d_v},\,W^O\in\mathbb{R}^{h\,d_v\times d_{\text{model}}}$이다.
본 논문에서는 $h=8$개의 병렬 attention head를 사용하였고, 각 head에 대해 $d_k=d_v=d_{\text{model}}/h=64$로 설정하여, 개별 head 차원을 줄임으로써 전체 연산량이 $d_{\text{model}}$-차원 단일 head attention과 대략 유사해지도록 하였다.
[추가]
1. Self-Attention 기본 흐름
1) 입력 임베딩 $\{x_1,\dots,x_n\}\in\mathbb{R}^{n\times d_{\mathrm{model}}}$
2) 선형 투영 (학습 파라미터 $W_Q,W_K,W_V ∈ \mathbb{R}^{d_{\mathrm{model}}×d_k}$)
$$
Q = XW_Q,\quad K = XW_K,\quad V = XW_V
$$
3) 스케일된 닷프로덕트 점수
$$
\tilde α = \frac{QK^T}{\sqrt{d_k}}
$$
4. 소프트맥스 → 어텐션 가중치
$$
α_{ij} = \frac{e^{\tilde α_{ij}}}{\sum_m e^{\tilde α_{im}}}
$$
5. Value 가중합
$$
Z = αV,\quad Z_i = \sum_j α_{ij} v_j
$$
2. Multi-Head Attention
아이디어: 단일 512차원 헤드 대신, $h$개의 64차원 “헤드”로 분산 처리
구조:
1. $h$개의 서로 다른 $\{W_Q^{(h)},W_K^{(h)},W_V^{(h)}\}$로 $Q^{(h)},K^{(h)},V^{(h)}$ 계산
2. 각 헤드별로 독립적 Self-Attention → $\mathrm{head}^{(h)} = \mathrm{Attention}(Q^{(h)},K^{(h)},V^{(h)})$
3. $\mathrm{head}^{(1)}\Vert\cdots\Vert\mathrm{head}^{(h)}\in\mathbb{R}^{n×(h·d_v)}$ 이어붙이기
4. 최종 투영 $W_O\in\mathbb{R}^{(h·d_v)×d_{\mathrm{model}}}$
계산량:
$$
O(h\,n^2\,d_k)\;=\;O\bigl(n^2\,(h\,d_k)\bigr)\;=\;O\bigl(n^2\,d_{\mathrm{model}}\bigr)
$$
→ 단일 헤드(512)와 동등
장점:
계산량 유지 + 다양한 시각(국소 vs. 장거리 의존성 등) 병렬 학습
3. CNN 필터와의 비유
필터: CNN이 여러 필터로 서로 다른 패턴(에지·질감 등)을 추출하듯,
헤드: Multi-Head Attention은 여러 헤드로 문맥 속 다양한 의존성 패턴을 추출
차이점: CNN은 위치 불변 필터, 어텐션은 동적 유사도 기반 가중합
Multi-Head Attention은 “여러 개의 작은 Self-Attention”을 병렬로 수행해 단일 헤드와 동일한 계산량으로 다양하고 풍부한 문맥 표현을 얻는 핵심 메커니즘이다.
[추가]
선형 투영(linear projection)의 의미와 Transformer에서의 역할
“선형(linear)”이라는 용어는 행렬 곱(matrix multiplication)이 곧 수학적으로 “선형 변환(linear transformation)”에 해당하기 때문에 붙는다. 즉, 임의의 벡터 $\mathbf{a}, \mathbf{b}$와 스칼라 $c$에 대해, 행렬 $W$가
$$
W(\mathbf{a} + \mathbf{b}) \;=\; W\mathbf{a} + W\mathbf{b},
\quad
W(c\,\mathbf{a}) \;=\; c\,(W\mathbf{a})
$$
라는 두 가지 성질을 모두 만족하면 “선형 변환”이라 부르며, 이를 이용해 “선형 투영(linear projection)”을 수행한다고 말할 수 있다. 반면 ReLU나 tanh 같은 활성화 함수까지 끼어들면(“linear + non-linear”) “비선형 변환”이 된다.
Transformer에서 선형 투영은 쿼리(query), 키(key), 값(value) 벡터를 원래의 $d_{\text{model}}$ 차원에서 더 작은 차원 $d_k$·$d_v$로 각각 매번 학습 가능한 행렬을 곱해 변환하는 과정을 의미한다. 예컨대 $d_{\text{model}}=512$이고, 멀티헤드 수 $h=8$이라면 각 head마다
$$
d_k \;=\; d_v \;=\; \frac{d_{\text{model}}}{h} \;=\; 64
$$
로 차원을 줄여 $8$개의 서로 다른 “하위 공간(sub-representation subspace)”에서 동시다발적으로 Attention 연산을 수행한다. 이때 각각의 head는 서로 다른 선형 투영 행렬 $\{W_i^Q,\,W_i^K,\,W_i^V\}$를 학습하여, “512차원짜리 정보를 8개의 서로 다른 64차원 서브스페이스로 나누어” 다양한 관점에서 문맥적 패턴을 포착할 수 있다.
Attention 연산이 끝나면 각 head에서 얻은 출력 $\mathrm{head}_i \in \mathbb{R}^{d_v}$를 병렬로 모아
$$
[\mathrm{head}_1; \dots; \mathrm{head}_h] \;\in\; \mathbb{R}^{h\,d_v}
$$
형태로 Concatenate(이어 붙임) 하고, 이후 최종 선형 투영 행렬 $W^O \in \mathbb{R}^{h\,d_v \times d_{\text{model}}}$를 곱해 원래의 $d_{\text{model}}$ 차원으로 되돌린다. 이 마지막 단계 역시 행렬 곱만 사용하므로 “선형 투영”이라 부른다.
결과적으로, 선형 투영은 Transformer가 서로 다른 표현 서브스페이스를 병렬로 탐색하면서도 계산 비용을 단일 헤드 어텐션(Single Head Attention)과 비슷하게 유지할 수 있게 해 주는 핵심 메커니즘이다.
[추가]
[질문]
“$W_i^Q$와 같은 선형 투영 행렬 $W$는 어떻게 만들고 초기화하는가?”
[답변]
$W_i^Q$를 포함한 모든 투영 행렬 $W^Q_i,\,W^K_i,\,W^V_i,\,W^O$ 등은 모델의 학습 파라미터로서, 아래 과정을 거쳐 만들어진다:
1. 형상(shape) 결정
우선, 모델 설정에서 각 헤드의 차원 $d_k,\,d_v$와 전체 모델 차원 $d_{\text{model}}$을 정한다. 예를 들어, Transformer base에서는 $d_{\text{model}}=512$, 헤드 수 $h=8$이므로
$$d_k \;=\; d_v \;=\; \frac{d_{\text{model}}}{h} \;=\; 64.$$
이때 각 헤드 $i$의 쿼리 투영 행렬 $W_i^Q$는 크기가 $\mathbb{R}^{d_{\text{model}}\times d_k}$가 된다. 마찬가지로,
$$
W_i^K \in \mathbb{R}^{d_{\text{model}}\times d_k},
\quad
W_i^V \in \mathbb{R}^{d_{\text{model}}\times d_v},
\quad
W^O \in \mathbb{R}^{(h\,d_v)\times d_{\text{model}}}.
$$
2. 무작위 초기화(Random Initialization)
일단 해당 모양대로 행렬을 생성한 뒤, Xavier/Glorot 초기화나 He 초기화 등 표준적인 방법으로 무작위 초기값(random values)을 채운다. 예를 들어 PyTorch나 TensorFlow에서 `torch.nn.Linear(d_model, d_k)` 혹은 `tf.keras.layers.Dense(d_k)`를 호출하면, 내부적으로 “표준 Xavier 분포” (또는 프레임워크 기본)로 가중치가 초기화된다.
3. 학습 중 업데이트(Update via Backpropagation)
이후 역전파(backpropagation) 과정에서, 손실(loss)에 대한 기울기(gradient)가 계산되어 이 $W$행렬의 값들이 최적화 알고리즘(예: Adam)으로 조금씩 조정된다. 훈련 데이터에 맞춰 반복해서 업데이트가 이루어진 뒤, Transformer가 충분히 학습되면 각 $W_i^Q$가 “쿼리 벡터를 적절한 하위 공간으로 투영”할 수 있도록 학습된다.
이 과정을 통해 “$W_i^Q$ 같은 선형 투영 행렬”이 학습 가능한 파라미터로 만들어지고, 점차 “헤드별 쿼리 하위 표현”을 잘 뽑아내도록 조정된다.
3.2.3 Applications of Attention in our Model
Transformer는 Multi Head Attention을 세 가지 방식으로 활용한다.
- 인코더 - 디코더 Attention 레이어
이 레이어에서 쿼리(query)가 이전 디코더 레이어의 출력에서 오고, 메모리 키(key) · 값(value)은 인코더의 최종 출력에서 온다. 덕분에 디코더의 각 위치(position)는 입력 시퀀스의 모든 포지션을 참조할 수 있다. 이는 전형적인 시퀀스-투-시퀀스 모델에서의 인코더-디코더 attention 메커니즘을 모방한 것이다. - 인코더의 Self-Attention 레이어
인코더 내부에는 여러 개의 self-attention 레이어가 쌓여 있는데, 이 레이어들에서는 쿼리·키·값(Q, K, V 모두)이 바로 이전 인코더 레이어의 출력으로부터 온다. 따라서, 인코더의 각 위치는 곧바로 이전 인코더 레이어의 모든 위치를 참조할 수 있다. - 디코더의 Self-Attention 레이어
디코더에서도 마찬가지로 sefl-attention 레이어를 사용하되, '미래 토큰(future positions)'을 참조하지 못하도록 마스킹(masking)을 적용한다. 구체적으로, 디코더의 각 위치는 '이전 디코더 레이어'의 해당 위치 및 그 이전 위치들만 참조할 수 있다. 이렇게 해야 auto-regressive(자기 회귀) 속성이 보존되는데, 구현 방식은 'scaled dot-product attention 내부에서 불법적인 연결(illegal connections)에 해당하는 소프트맥스 입력값을 $-\infty$로 설정하는 것이다.
[추가]
여기서 “쿼리(query)”라는 것은 현재 처리해야 하는 단어를 의미하는가? 이 단어를 처리할 때 메모리에 있는 키(key)·값(value)을 참조한다는 뜻인가?
Transformer에서 쿼리는 “디코더가 지금 생성(또는 디코딩)하고자 하는 단어 위치의 잠정적 표현(잠정적 hidden state)”을 가리킨다. 이 쿼리를 이용해 메모리(key·value)에서 필요한 정보를 꺼내 오는 과정은 다음과 같다:
1. 쿼리(query):
디코더가 시점 $t$에서 “다음에 생성해야 할 단어”를 예비적으로 나타내는 벡터. 실제로는 디코더의 이전 레이어 출력(또는 현재 위치에서의 임시 표현)이 쿼리 역할을 수행한다.
2. 메모리(memory)의 구성:
인코더가 입력 시퀀스 $\{x_1, x_2, \dots, x_n\}$를 처리한 뒤 최종 레이어에서 생성한 벡터 $\{\mathbf{z}_1, \mathbf{z}_2, \dots, \mathbf{z}_n\}$를 기반으로,
키(key) $\mathbf{k}_j = W^K\,\mathbf{z}_j$ (차원 $d_k$)
값(value) $\mathbf{v}_j = W^V\,\mathbf{z}_j$ (차원 $d_v$)
를 각각 얻는다. 여기서 $W^K$와 $W^V$는 학습 가능한 선형 투영 행렬이다.
3. 쿼리–키 매칭 및 가중합:
디코더의 쿼리 $\mathbf{q}_t\in\mathbb{R}^{d_k}$와 메모리 키 $\{\mathbf{k}_1,\dots,\mathbf{k}_n\}$를 각각 내적(dot product)하여 “어떤 입력 위치가 중요한지”를 나타내는 스칼라 가중치 $\alpha_{t,j}$를 구한다. 내적 결과를 $\sqrt{d_k}$로 나누고(스케일링), 소프트맥스(softmax)를 적용해 $\alpha_{t,j}$를 계산한다. 마지막으로, 이 가중치 $\alpha_{t,j}$를 메모리 값 $\mathbf{v}_j$에 곱해 합산하면
$$
\mathbf{o}_t \;=\; \sum_{j=1}^n \alpha_{t,j}\,\mathbf{v}_j
$$
와 같이 “현재 디코딩 위치가 인코더 메모리에서 꺼내 온 정보”를 얻을 수 있다. 이 $\mathbf{o}_t$가 디코더 다음 레이어로 전달되어 실제 단어 생성에 사용된다.
따라서 “쿼리”는 디코더 입장에서 “현재 생성 중인(또는 처리할) 단어를 나타내는 벡터”이며, 이 쿼리를 통해 인코더 측 메모리에 저장된 키·값을 참조하여 필요한 정보를 가져오는 구조다.
3.3 Position-wise Feed-Forward Networks
attention sub-layer 외에도, 인코더와 디코더의 각 레이어는 각 위치(position)에 대해 별도로 동일하게 적용되는 fully connected feed-forward network를 갖는다.
이 네트워크는 ReLU 활성화 함수를 사이에 둔 두 개의 선형 변환(linear transformation)으로 이루어지며, 식으로는
$$
\mathrm{FFN}(x) = \max\bigl(0,\,xW_1 + b_1\bigr)\,W_2 + b_2
$$
와 같다. 선형 변환은 모든 위치에 대해 동일하게 적용되는 반면, 레이어마다 서로 다른 학습 파라미터 $(W_1,\,b_1,\,W_2,\,b_2)$를 사용한다.
다른 관점에서는, 이것을 커널 크기 1의 1D convolution 두 번 수행하는 것과 동일한 연산으로 볼 수 있다. 입력과 출력 차원은 $d_{\text{model}}=512$, 은닉층 차원은 $d_{\text{ff}}=2048$이다.
3.4 Embeddings and Softmax
시퀀스-트랜스덕션(sequence transduction) 모델과 마찬가지로, 입력 토큰과 출력 토큰을 $d_{\text{model}}$-차원 벡터로 변환하기 위해 학습된 embeddings을 사용했다. 또한 디코더 출력을 예측된 다음 토큰 확률로 변환하기 위해, 일반적인 학습된 선형 변환(linear transformation)과 소프트맥스(softmax) 함수를 사용했다. 이 모델에서는 두 개의 임베딩 레이어와 pre-softmax 선형 변환 사이에서 동일한 가중치 행렬을 공유한다.("weight tying"). 임베딩 레이어를 구성할 때는 해당 가중치 행렬에 $\sqrt{d_{\text{model}}}$를 곱해 사용한다.
3.5 Positional Encoding
Transformer 모델은 recurrence나 convolution을 사용하지 않기 때문에, 시퀀스 순서를 인식하려면 각 토큰의 상대적·절대적 위치 정보를 추가해야 한다. 이를 위해 인코더와 디코더 스택의 맨 아래에 있는 입력 임베딩에 positional encoding을 더한다. 이 positional encoding은 임베딩과 동일하게 $d_{\text{model}}$ 차원을 가지므로, 두 벡터를 그대로 합할 수 있다. positional encoding에는 학습 가능한 방식과 고정된 방식이 각각 존재할 수 있다. 본 논문에서는 서로 다른 주파수의 사인·코사인 함수를 사용한 고정된 방식을 채택했다. 구체적으로, 위치 $pos$와 차원 인덱스 $i$에 대해
$$
\begin{aligned}
P\!E(pos,\,2i) &= \sin\Bigl(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\Bigr),\\
P\!E(pos,\,2i+1) &= \cos\Bigl(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\Bigr).
\end{aligned}
$$
여기서 $pos$는 시퀀스 내 위치(0부터 시작하는 인덱스)를, $i$는 차원 인덱스를 가리킨다. 즉 positional encoding의 각 차원은 서로 다른 주파수의 sinusoid에 대응하며, 파장은 $2\pi$에서 $10000 \times 2\pi$까지 기하급수적으로 늘어난다. 이런 함수를 선택한 이유는 “임의의 오프셋 $k$만큼 위치를 이동했을 때 $P\!E(pos+k)$가 $P\!E(pos)$의 선형 함수로 표현될 수 있어, 모델이 상대적 위치 정보를 쉽게 학습할 수 있기 때문”이다. 또한 학습된 positional embedding을 사용해 실험해 본 결과 두 버전 모두 거의 동일한 성능을 보여(표 3, 행 (E) 참고), 본 논문에서는 훈련 시 접하지 못한 더 긴 시퀀스 길이로도 외삽(extrapolate)할 수 있다는 장점 때문에 sinusoidal 방식을 최종 선택하였다.
4 Why Self-Attention
이 절에서는 전형적인 sequence transduction 인코더나 디코더의 은닉층처럼, 길이가 가변적인 기호 벡터 시퀀스 $(x_1, \dots, x_n)$를 동일한 길이의 다른 시퀀스 $(z_1, \dots, z_n)$로 매핑하는 데 흔히 사용되는 recurrent 및 convolutional 계층과, 이와 비교해 self-attention 계층의 여러 특성을 살펴본다. 여기서 $x_i, z_i \in \mathbb{R}^d$이다.
Self-attention을 선택한 동기를 설명하기 위해 세 가지 바람직한 조건(desiderata)을 제시한다.
1. 레이어당 전체 계산 복잡도(total computational complexity per layer)
2. 병렬화 가능한 연산량(amount of computation that can be parallelized) – 이를 “필요한 순차 연산(sequential operations)의 최소 개수”로 측정한다.
3. 네트워크 내 장거리 의존성(long-range dependencies) 간에 신호가 통과해야 하는 경로(path) 길이
장거리 의존성을 학습하는 것은 많은 sequence transduction 과제에서 핵심적인 도전 과제이다. 이러한 의존성을 제대로 학습하려면, 네트워크 안에서 신호가 전방(forward)과 역방향(backward)으로 이동해야 하는 경로가 짧을수록 유리하다. 즉, 입력 시퀀스의 어떤 위치에서 출력 시퀀스의 어떤 위치로도 경로가 짧을수록 모델이 장거리 의존성을 더 쉽게 학습할 수 있다.
따라서 본절에서는 서로 다른 계층 유형(layer type)으로 구성된 네트워크들에서 임의의 입력 위치와 출력 위치 사이의 최대 경로 길이를 비교한다.
표 1에 보듯, self-attention 계층은 모든 위치를 일정한 수의 순차 연산(constant number of sequential operations)만으로 연결하지만, recurrent 계층은 $O(n)$개의 순차 연산을 필요로 한다.
계산 복잡도(computational complexity) 측면에서 보자면, sequence 길이 $n$이 표현 차원 $d$보다 작을 때($n < d$), self-attention 계층이 recurrent 계층보다 속도가 빠르다. 이는 최첨단 machine translation 모델들이 흔히 쓰는 word-piece나 byte-pair 등의 문장 표현에서 주로 성립하는 조건이다.
만약 매우 긴 시퀀스를 다루는 과제에서 계산 성능을 더 높이고 싶다면, self-attention을 “각 출력 위치를 중심으로 입력 시퀀스의 반경 $r$에 해당하는 부분만 참조하도록” 제한할 수 있다. 이렇게 하면 임의의 두 입력·출력 위치 간 최대 경로 길이가 $O(n/r)$로 늘어나지만, 전체 계산량은 여전히 제어할 수 있다. 이 접근법은 후속 연구로 더 깊이 살펴볼 예정이다.
단일 convolutional layer에서 커널 너비 $k < n$일 경우, 모든 입력 위치와 출력 위치를 직접 연결할 수 없다. 이를 모두 연결하려면, contiguous kernels의 경우에는 $O(n/k)$개의 convolutional layer를 쌓아야 하고, dilated convolutions의 경우에는 계층 수가 $O(\log_k n)$만큼 필요하게 되어 네트워크 내 임의의 두 위치 사이를 잇는 최장 경로 길이가 커진다.
또한 일반적인 convolutional layer는 계산 비용이 RNN 계층보다 약 $k$배 더 높다. 반면, separable convolution을 사용하면 계산 복잡도를 $O(k \cdot n \cdot d + n \cdot d^2)$로 크게 줄일 수 있다. 심지어 $k = n$인 경우에도, separable convolution의 계산 복잡도는 self-attention layer + point-wise feed-forward layer 조합의 복잡도와 동일하다. 따라서 본 논문에서는 self-attention + point-wise feed-forward 방식을 채택한다.
부가적 이점으로, self-attention은 모델을 더 해석 가능하게 만든다. 우리는 부록에서 모델의 attention 분포(attention distributions)를 분석한 뒤 예시를 제시하고 논의했다. 개별 attention 헤드는 서로 다른 역할을 수행하도록 학습되는 것이 뚜렷하며, 많은 헤드가 문장의 구문적·의미적 구조와 관련된 동작을 보이는 것으로 나타났다.
[추가]
[질문] 장거리 의존성(long-range dependencies)을 학습하는 것이 중요한 과제인 이유는 무엇인가?
[답변] RNN처럼 순차적으로 연결된 구조는 경로가 길어질수록 기울기 소실(gradient vanishing) 문제가 심해져, 멀리 떨어진 위치 간 관계를 학습하기 어려워지기 때문이다. 경로가 짧을수록 신호가 안정적으로 전달되므로 장거리 의존성을 잘 학습할 수 있다.
[질문] RNN(Recurrent Neural Network) 계층이 $O(n)$개의 순차 연산을 필요로 하는 이유는 무엇인가? “예를 들어 ‘나 → 학교 → 에 → 간다’라는 입력이 들어오면, self-attention은 한 번에 처리되지만 RNN은 3번(혹은 4번) 순차적으로 처리해야 하나?”
[답변] 맞다. RNN은 각 시점 $t$에서 “이전 시점의 은닉 상태(hidden state)”를 받아야 새로운 은닉 상태를 계산하므로, 길이 $n$인 시퀀스를 처리하려면 $n$번의 순차 계산을 거쳐야 한다. 예시로 길이가 4인 문장을 처리하려면 “토큰1 → 토큰2 → 토큰3 → 토큰4” 순서대로 $4$번의 은닉 상태 업데이트가 필요하므로, RNN은 $O(n)$개의 순차 연산이 필요하다.
[질문] 계산 복잡도(computational complexity) 관점에서 “sequence 길이 $n$이 표현 차원 $d$보다 작을 때, 왜 self-attention 계층이 RNN 계층보다 빠른가?”
[답변] Self-Attention 한 레이어의 연산 복잡도는 $O(n^2 \, d)$이고, RNN 한 레이어는 $O(n \, d^2)$입니다. 따라서 $n < d$일 때는
$$
n^2 \, d \;<\; n \, d^2,
$$
즉 Self-Attention이 계산량 면에서 더 효율적이다. 대부분의 machine translation 모델에서는 "문장 길이($n$)"가 "표현 차원($d$)"보다 작으므로, Self-Attention이 RNN보다 빠르다.
[질문] “각 출력 위치를 중심으로 입력 시퀀스의 반경 $r$만 참조하도록 제한”하면, 왜 “최대 경로 길이”가 $O(n/r)$로 늘어나는 건가? $n/r$는 $n$보다 작은 값 아닌가?
[답변] Full Self-Attention에서는 “쿼리 위치 $i$”가 “모든 입력 위치 $j$”를 한 번에 참조할 수 있어, 어떤 두 위치 $i, j$ 사이를 잇는 경로 길이가 항상 1이다($O(1)$). 그러나 반경 $r$로 제한하면 “한 번에 $r$칸만 이동”할 수 있으므로, 가장 먼 두 위치 $1$과 $n$을 연결하려면 $\sim n/r$단계의 hop이 필요하다. 따라서 경로 길이가 $1$ → $\,n/r$로 증가하므로 “최대 경로 길이”를 $O(n/r)$라고 표현한다.
5 Training
5.1 Training Data and Batching
본 논문에서는 약 450만 쌍의 문장으로 구성된 표준 WMT 2014 영어-독일어 데이터셋에서 학습을 진행했다. 문장들은 약 3만 7천 개의 공유 소스-타겟 어휘를 갖는 byte-pair encoding을 사용해 인코딩되었다. 영어-프랑스어의 경우, 훨씬 큰 3,600만 개 문장으로 이루어진 WMT 2014 영어-프랑스어 데이터셋을 사용했으며, 토큰을 3만 2천 개 크기의 word-piece 어휘로 분할했다. 문장 쌍은 대략적인 시퀀스 길이에 따라 배치되었고, 각 학습 배치에는 약 25,000개의 소스 토큰과 25,000개의 타겟 토큰을 포함하는 문장 쌍들이 담겼다.
[추가]
[질문]
“소스-타겟 어휘를 갖는 byte-pair encoding(BPE)”이란 무엇인가? 예를 들어 “hello”의 토큰화 결과는?
[답변]
Byte-Pair Encoding(BPE)은 모든 문장을 처음에 “문자(character)” 단위로 분리한 뒤, 말뭉치(corpus)에서 가장 빈번하게 함께 등장하는 문자 쌍(pair)을 반복적으로 합쳐 나가면서 어휘(vocabulary)를 구축하는 방법이며, 구체적으로는 다음과 같다:
1. 초기 문자 분리
말뭉치 내 모든 단어를 개별 문자로 분해한다. 예를 들어 “hello”라면 처음에는 `h e l l o`로 분리(보통 끝에 $/w$ 표시도 붙여 `h e l l o $/w$` 형태)한다.
2. 빈도 기반 병합 반복
말뭉치 전체에서 가장 자주 등장하는 문자 쌍(예: `l l`, `e r`, `th` 등)을 찾아 합치고, 이 과정을 원하는 어휘 크기(예: 37,000개)만큼 계속 반복한다.예를 들어 말뭉치에서 “ll”이 가장 빈번하다면, `l l` → `ll`로 병합한다. 다음 단계에서는 “he”가 빈도가 높다면 `h e` → `he`로 병합하는 식이다.
3. 공유 어휘(Shared Vocabulary)
영어와 독일어(또는 영어-프랑스어) 양쪽 말뭉치를 합쳐 하나의 BPE 과정을 수행해, 최종적으로 얻은 37,000개의 하위어(subword) 토큰 집합을 소스와 타겟이 모두 공유한다. 이렇게 하면 예컨대 “un”이나 “tion” 같은 형태소를 두 언어가 동시에 재사용할 수 있어 번역 모델이 언어 간 유사성을 효율적으로 활용할 수 있다.
4. “hello” 토큰화 예시
초기:
h e l l o
1차 병합 (말뭉치 빈도에 따라 “ll” 먼저 병합될 경우):
h e ll o
2차 병합 (다음으로 “he”가 병합된다면):
he ll o
3차 병합 (말뭉치에서 “llo”가 자주 보인다면):
he llo
최종적으로는 말뭉치 빈도에 따라 `hello` 자체가 하나의 토큰이 될 수도 있고, `he` + `llo` 두 개의 토큰으로 남을 수도 있다. 이 과정을 37,000개의 어휘 개수가 갖춰질 때까지 반복하면, “hello”를 포함한 모든 단어가 “언어적 빈도에 기반한 하위어 토큰”들로 효율적으로 분해된다.
5. 이점 정리
OOV(Unknown Word) 문제 완화: 완전한 단어 사전에 없더라도, 하위어 단위 토큰화로 유사 형태의 토큰을 조합해 처리할 수 있다.
어휘 크기 축소: 빈도가 높은 하위어만 선택해 어휘에 포함하므로, 전체 어휘 크기를 작게 유지하면서도 표현력을 확보한다.
언어 간 정보 공유: 서로 다른 언어에서도 유사한 하위어를 공유해, 번역 모델이 효율적으로 학습할 수 있다.
따라서 “소스-타겟 어휘를 갖는 BPE”란, 영어와 독일어(또는 영어와 프랑스어) 양쪽에서 같은 37,000개 하위어 어휘를 사용해 입력과 출력을 토큰화하는 기법이며, “hello”는 위 방식대로 단계별 병합을 거쳐 예컨대 `he` + `llo` 혹은 단일 `hello` 토큰으로 표현될 수 있다.
5.2 Hardware and Schedule
본 논문에서는 8개의 NVIDIA P100 GPU가 장착된 한 대의 머신에서 모델을 학습시켰다. 논문 전반에 걸쳐 설명된 하이퍼파라미터를 사용한 기본 모델의 경우, 각 학습 단계는 약 0.4초가 소요되었다. 기본 모델은 총 10만 단계, 즉 12시간 동안 학습했다. 표 3의 하단에 설명된 대형 모델의 경우, 학습 시간은 1.0초였다. 대형 모델은 30만 단계(3.5일) 동안 학습했다.
5.3 Optimizer
우리는 Adam 옵티마이저를 $\beta_1 = 0.9$, $\beta_2 = 0.98$, $\epsilon = 10^{-9}$의 하이퍼파라미터로 사용했다. 학습률(learning rate)은 훈련 과정에서 다음 식에 따라 변동시켰다:
$$
\text{lrate} = d_{\text{model}}^{-0.5} \cdot \min\bigl(\text{step_num}^{-0.5},\; \text{step_num} \times \text{warmup_steps}^{-1.5}\bigr).
$$
이 식은 처음 $\text{warmup_steps}$ 단계 동안 학습률을 선형적으로 증가시킨 뒤, 그 이후에는 학습 단계 수의 역제곱근에 비례하여 감소시키는 방식을 의미한다. 우리는 $\text{warmup_steps} = 4000$을 사용했다.
5.4 Regularization
본 논문에서는 훈련 중에 세 가지 유형의 정규화를 사용하였다.
Residual Dropout
각 서브레이어의 출력에 Dropout을 적용한 후, 이를 서브레이어 입력에 더하고 정규화한다. 또한 인코더와 디코더 스택에서 임베딩과 포지셔널 인코딩의 합에도 Dropout을 적용한다. 베이스 모델에서는 Dropout 비율 $P_{\text{drop}} = 0.1$을 사용했다.
-> 즉, 출력 Dropout 과 임베딩 Dropout 두 개 사용되었으며, 레이블 스무딩과 합쳐 총 3개가 사용됨
레이블 스무딩(Label Smoothing)
훈련 중에 값 $\epsilon_{\text{ls}} = 0.1$의 레이블 스무딩을 적용했다. 이는 모델이 더 불확실한 예측을 하도록 만들어 퍼플렉서티(perplexity)를 다소 높이지만, 정확도와 BLEU 점수를 개선하는 효과가 있다.
6 Results
6.1 Machine Translation
WMT 2014 영어→독일어 번역 과제에서, Big Transformer 모델(표 2의 “Transformer (big)”)은 이전에 보고된 모든 모델(앙상블 포함)보다 2.0 BLEU 이상 높은 새로운 최첨단 BLEU 점수인 28.4를 기록했다. 이 모델의 구성은 표 3 마지막 줄에 나와 있으며, 8개의 P100 GPU에서 3.5일간 학습했다. 심지어 우리의 Base 모델도 이전에 발표된 모든 단일 모델 및 앙상블 모델을 능가하면서, 경쟁 모델들에 비해 훨씬 적은 학습 비용(시간·자원)으로 동작한다.
WMT 2014 영어→프랑스어 번역 과제에서는, Big Transformer 모델이 BLEU 41.0을 달성하여 이전까지 발표된 모든 단일 모델을 능가했으며, 이전 최첨단 모델 학습 비용의 1/4 이하로 학습을 마쳤다. 프랑스어 모델 학습 시에는 drop-out 비율을 $P_{\text{drop}} = 0.1$로 설정했고, Base 모델의 경우 마지막 \\5개 체크포인트(checkpoint)\\를 10분 간격으로 저장한 뒤 이 5개를 평균해 최종 단일 모델을 얻었다. Big 모델에서는 마지막 20개 체크포인트를 평균했다.
추론 시에는 빔 서치(beam search)를 빔 크기 $= 4$에 길이 패널티(length penalty) $\alpha = 0.6$\[38]로 사용했으며, 하이퍼파라미터는 개발 데이터셋에서 실험을 통해 결정했다. 출력 문장은 “입력 길이 + 50”을 최대치로 설정하되, 더 일찍 종료해도 가능하면 그 시점에 멈추도록 하였다.
표 2에는 우리의 번역 품질(BLEU 점수)과 학습 비용을 기존 문헌의 다른 모델 아키텍처와 비교해 요약하였다. 또한 “각 모델 학습에 사용된 플로팅포인트 연산량”은 “학습 시간 × 사용된 GPU 수 × GPU당 지속(single-precision) 연산 능력 추정치”를 곱하여 산출했다.
6.2 Model Variations
Transformer의 다양한 구성 요소가 얼마나 중요한지 평가하기 위해, 우리는 Base 모델을 여러 방식으로 변형하여 English→German 번역(dev 셋: newstest2013)에서 성능 변화를 측정했다. 이전 절에서 설명한 대로 빔 서치(beam search)를 사용했으나, 체크포인트 평균화는 적용하지 않았다. 이 결과를 표 3에 제시한다.
표 3 행 (A)에서는 섹션 3.2.2에서 설명한 대로 계산량을 일정하게 유지하면서 어텐션 헤드 수와 어텐션 키·값 차원($d_k, d_v$)을 바꿔 실험했다. 단일 헤드(single-head) 어텐션은 최상의 설정에 비해 약 0.9 BLEU 낮았으며, 반대로 헤드 수가 너무 많아도 성능이 떨어졌다.
표 3 행 (B)에서는 어텐션 키 크기 $d_k$를 줄였을 때 모델 품질이 저하되는 것을 확인했다. 이는 “호환도(compatibility)를 측정하는 것이 쉽지 않으며, 단순한 내적(dot product) 대신 더 정교한 호환도 함수를 사용하는 편이 도움이 될 수 있음을 시사”한다.
표 3 행 (C)·(D)에서 예상대로, 모델 크기를 키우면 성능이 향상되며(dimension 확대 시 번역 품질 개선), 드롭아웃(dropout)을 적용하면 과적합(overfitting)을 방지하는 데 매우 효과적임을 확인했다.
표 3 행 (E)에서는 원래 사용한 사인·코사인 기반 포지셔널 인코딩을 학습 가능한 포지셔널 임베딩(learned positional embeddings)으로 바꿔 실험했으며, Base 모델과 거의 동일한 성능을 보였다.
6.3 English Constituency Parsing
본 논문에서는 Transformer가 다른 과제에도 일반화할 수 있는지 평가하기 위해, 영어 구성 트리 파싱(English constituency parsing) 실험을 수행했다. 이 과제는 다음과 같은 구체적 도전 과제를 제시한다. 출력 구조에는 강력한 구조적 제약이 있고, 출력 시퀀스가 입력보다 훨씬 길다. 게다가, RNN 기반 시퀀스-투-시퀀스 모델은 적은 데이터 환경(small-data regime)에서 최첨단 결과를 달성하지 못했다.
본 논문은 Penn Treebank의 Wall Street Journal(WSJ) 부분, 약 40,000개의 훈련 문장으로 구성된 데이터셋에서 $d_{\text{model}} = 1024$인 4층 Transformer를 학습시켰다. 또한, 준지도(semisupervised) 설정에서는 고신뢰(high-confidence) 데이터와 BerkeleyParser 코퍼스(약 1,700만 문장)를 추가로 사용해 학습했다. WSJ 전용 설정에서는 16,000개 토큰 어휘를, 준지도 설정에서는 32,000개 토큰 어휘를 사용했다.
훈련 시에는 섹션 5.4에 언급된 대로 드롭아웃(dropout)–어텐션 및 잔차(residual)–, 학습률(learning rate), 빔 크기(beam size) 등을 Section 22 개발(dev) 세트에서 소수의 실험만으로 선정했으며, 그 밖의 모든 하이퍼파라미터는 English→German 기본 번역 모델과 동일하게 유지했다. 추론(inference) 단계에서는 최대 출력 길이를 “입력 길이 + 300”으로 늘렸고, WSJ 전용 및 준지도 설정 모두에서 빔 크기 21과 길이 패널티 $\alpha = 0.3$을 사용했다.
표 4의 결과를 보면, 과제 특화(task-specific) 튜닝 없이도 우리의 모델이 놀라울 정도로 우수한 성능을 보이며, Recurrent Neural Network Grammar을 제외한 이전 보고된 모든 모델보다 더 나은 결과를 낸다. 특히, RNN 기반 시퀀스-투-시퀀스 모델과 달리, Transformer는 WSJ 훈련 세트(40K 문장)만으로 학습했을 때조차도 BerkeleyParser를 능가한다.
7 Conclusion
본 논문에서는, 전적으로 어텐션(attention)에 기반한 최초의 시퀀스 트랜스덕션(sequence transduction) 모델인 Transformer를 제안했다. 이 모델은 인코더-디코더 아키텍처에서 일반적으로 사용되던 순환 계층(recurrent layers)을 다중 헤드(self-attention) 어텐션으로 대체한다. 번역 과제에서 Transformer는 순환 또는 합성곱 계층을 사용하는 아키텍처보다 훨씬 빠르게 학습될 수 있다. WMT 2014 영어→독일어 및 WMT 2014 영어→프랑스어 번역 과제 모두에서 새로운 최첨단 성능(state of the art)을 달성했으며, 특히 전자의 경우 우리의 최상위 모델은 이전에 보고된 모든 앙상블 모델조차 능가했다. 우리는 어텐션 기반 모델의 미래에 큰 기대를 가지고 있으며, 이를 다른 과제에도 적용할 계획이다. 또한 텍스트 이외의 입력·출력 모달리티(modality)를 포함하는 문제로 Transformer를 확장하고, 이미지·오디오·비디오와 같은 대규모 입력 및 출력을 효율적으로 처리하기 위한 국소 제한적(local, restricted) 어텐션 메커니즘 연구를 진행할 예정이다. 생성 과정을 덜 순차적으로 만드는 방법도 연구 목표 중 하나다. 본 논문에서 사용한 학습 및 평가용 코드는 https://github.com/tensorflow/tensor2tensor에서 확인할 수 있다.


[추가] Beam search
★정의
1. Beam Search는 순차적 생성(sequence generation) 문제에서 가능한 모든 후보를 탐색(exhaustive search)하지 않고, 매 시점마다 가장 유망한 상위 $k$개(beam width)만 선택하여 다음 단계로 넘기는 근사 탐색 알고리즘이다.
2. 주로 기계번역, 음성인식, 언어 모델 디코딩 등에서 쓰이며, 빔 폭 $k=1$일 때는 Greedy Search(매 단계 가장 높은 확률 하나만 선택), $k$를 크게 하면 완전 탐색에 가까워진다.
★ 알고리즘 절차
1. 초기화
(1) 시작 토큰 $\langle s \rangle$로 이루어진 빈 시퀀스를 하나의 빔(beam)으로 두고, 누적 점수를 $\log 1 = 0$으로 설정한다.
2. 반복 단계 (출력 길이 $t=1,2,\dots$ 순서대로 수행)
(1) 현재 빔에 속한 각 시퀀스 $\bigl(y_{1\!:\!t-1}\bigr)$에 대해, 모델로부터 다음 토큰 분포 $p(y_t \mid y_{1\!:\!t-1}, x)$를 계산한다. 여기서 $x$는 입력 시퀀스(예: 번역의 경우 원문)이다.
(2) 각 시퀀스마다 상위 $|V'|$개의 후보 토큰을 뽑아 새로운 후보 시퀀스 $y_{1:t} = [y_{1\!:\!t-1},\, w]$를 생성하고, 누적 로그 점수
$$
s' = s\bigl(y_{1\!:\!t-1}\bigr) + \log p\bigl(w \mid y_{1\!:\!t-1}, x\bigr)
$$
를 계산한다. 여기서 $s(y_{1\!:\!t-1})$은 이전 단계까지의 누적 로그 점수다. 일반적으로 $|V'| = |V|$(전체 어휘)이지만, 구현상 효율을 위해 제한된 개수만 고려하기도 한다.
(3) 전체 후보(기존 빔 크기 $\times |V'|$ 개) 중 누적 점수 $s'$가 높은 상위 $k$개만 골라 새로운 빔으로 유지하고, 나머지는 제거한다.
★ 종료 조건
1. 빔에 속한 모든 시퀀스가 종료 토큰 $\langle /s \rangle$를 포함하게 되거나, 미리 정해둔 최대 길이 $L_{\max}$에 도달하면 반복을 중단한다.
2. 종료 후, 빔에 남은 완전한 시퀀스들 중 누적 점수가 가장 높은 것을 최종 결과로 출력한다.
★ 수학적 성질
1. 최적해 비보장(Theorem)
* Beam Search는 근사(approximate) 알고리즘이므로, 항상 전체 공간에서 확률이 최대인 시퀀스를 찾는 것을 보장하지 않는다.
* 예를 들어, 빔 폭 $k$가 작으면 한 단계에서 제거된 경로가 이후에 더 좋은 전체 시퀀스로 이어질 수 있음에도, 그 후보가 제거되어 전역 최적해(global optimum)를 놓칠 수 있다.
★ 빔 폭에 따른 상한(Upper-bound) 정리
* $k_1 < k_2$일 때, 빔 폭 $k_2$를 사용할 경우 얻을 수 있는 최종 시퀀스의 확률(점수)은 빔 폭 $k_1$을 쓸 때의 점수보다 낮아지지 않는다.
* 증명:
1. 빔 폭 $k_1$로 탐색할 때, 단계별로 유지되는 상위 $k_1$개의 후보는 빔 폭 $k_2$ ($k_2 > k_1$)에서도 후보 집합에 포함될 수 있다.
2. 따라서 $k_2$에서는 $k_1$ 때 제거된 경로가 새롭게 추가되더라도, 최소한 $k_1$로 얻었던 최고 점수를 얻을 수 있으므로, 최고 점수는 감소하지 않는다.
3. 길이 편향(Length Bias)
* Beam Search는 누적 로그 확률을 기준으로 후보를 선택하기 때문에, 상대적으로 짧은 문장이 높은 평균 확률을 얻게 되어, 결과가 너무 짧아지는 편향이 생길 수 있다. 이 문제는 ‘길이 정규화(length normalization)’ 기법으로 보정한다.
★ 시간 및 공간 복잡도
1. 시간 복잡도(Time Complexity)
* 매 시점마다 빔 크기 $k$개의 시퀀스에서 다음 토큰 점수를 계산하고, 각 시퀀스당 상위 $|V'|$개를 뽑은 뒤 $\mathcal{O}(k \cdot |V'|)$개의 후보 중 상위 $k$개를 다시 선별한다.
* 보통 $|V'| = |V|$ (전체 어휘)라고 하면, 한 단계 계산 비용이 $\mathcal{O}(k \cdot |V|)$가 된다. 출력 길이가 최대 $T$라면 전체 $\mathcal{O}(T \cdot k \cdot |V|)$ 연산이 필요하다.
2. 공간 복잡도(Space Complexity)
* 매 시점 $t$마다 후보 $k$개를 메모리에 유지하므로, $\mathcal{O}(k \cdot T)$ 만큼 시퀀스를 저장해야 한다.
★ 주요 변형 및 확장 기법
1. 길이 정규화(Length Normalization)
* 원본 Beam Search는 누적 로그 확률 $\sum_{t=1}^T \log p(y_t \mid y_{1\!:\!t-1}, x)$로 순위를 매기므로, 짧은 시퀀스가 유리해지는 문제가 있다.
* 이를 보완하기 위해, 길이에 따라 점수를 정규화하여 비교한다. 대표적으로
$$
\text{score}_{\text{norm}}(y_{1:T}) \;=\; \frac{1}{T^\alpha} \sum_{t=1}^T \log p(y_t \mid y_{1\!:\!t-1}, x) \qquad (\alpha \ge 0)
$$
* $\alpha=0$일 때 원본 방식이고, $\alpha>0$일 때 짧은 문장에 가해진 누적 로그 확률이 감소하여 길이 편향을 완화한다.
2. 커버리지 패널티(Coverage Penalty)
* 기계번역 같은 과제에서 “소스 문장의 모든 단어가 충분히 번역되었는가”를 평가해, 만약 일부 단어가 적게 참조되었다면 점수를 벌점(penalty)으로 주는 방식이다.
* 예를 들어, 디코더가 각 디코딩 단계에서 생성된 단어에 대해 인코더의 어텐션(attention) 가중치를 계산하므로, 소스 단어별 누적 어텐션 합이 지나치게 작으면 페널티를 부여한다.
3. 다양성 확보 Beam Search (Diverse Beam Search)
* 일반 Beam Search는 상위 확률에 집중하여 매우 유사한 $k$개의 후보를 선택한다.
* 이를 방지하기 위해, 빔을 여러 그룹으로 나눈 뒤 그룹 간 보상(reward)·패널티(penalty)를 적용하여 서로 다른 유형의 후보를 유지하도록 한다.
4. 제약(decoding) Beam Search
* Constrained Beam Search 또는 Prefix Beam Search라고도 불리며, 외부 규칙(예: 특정 단어 반드시 포함, 금지어 제외, 운율 패턴)을 만족하도록 디코딩한다.
5. 확률 기반 변형(Stochastic/Sampling-based Beam Search)
* 토큰을 확률 분포에서 단순히 뽑는(random sampling) 대신, 가중치를 고려해 후보를 유지하며 빔을 갱신해 다소 무작위성을 도입한다.
* 이로써 하나의 상위 확률 시퀀스만 출력하는 대신, 다양한 결과를 생성할 수 있다.
★ 장단점
1. 장점
(1) 연산 효율성: 전체 공간을 탐색하는 것에 비해 계산량이 크게 줄어들면서도 Greedy Search보다 더 나은 품질의 시퀀스를 얻을 수 있다.
(2) 품질-속도 절충 조절: 빔 폭 $k$를 조절하면, 작게 할수록 빠르고 크게 할수록 품질이 상승하는 트레이드오프를 쉽게 관리할 수 있다.
2. 단점
(1) 최적해 비보장: 특히 빔 폭이 작으면, 전역적으로 가장 좋은 시퀀스를 놓칠 가능성이 높다.
(2) 길이 편향: 짧은 문장에 불리하게 작용하는 경우가 있어 별도의 정규화가 필요하다.
(3) 메모리·시간 증가: 빔 폭 $k$와 어휘 크기 $|V|$에 선형으로 비례하기 때문에, $k$가 커지면 연산량과 메모리 사용량이 급증한다.
(4) 출력 다양성 부족: 보통 상위 확률 시퀀스만 남기므로, 여러 다양한 후보를 생성해야 하는 과제에는 단순 Beam Search만으로는 충분치 않을 수 있다.
★ 간단한 예시 의사코드(Pseudo-code)
다음은 Python 유사 코드 형태로, 빔 폭 $k=5$, 최대 디코딩 길이 $L_{\max}$인 경우다.
def beam_search(model, input_x, beam_width=5, max_len=50):
# 빔은 리스트 형태로, 각 원소는 (sequence, 누적 로그 점수)
beam = [(['<s>'], 0.0)] # 시작 토큰만 가진 시퀀스, 점수 0
for t in range(1, max_len + 1):
all_candidates = []
# 빔에 있는 각 시퀀스를 확장
for seq, score in beam:
if seq[-1] == '</s>':
# 이미 종료 토큰이 있으면 그대로 후보에 유지
all_candidates.append((seq, score))
else:
# 다음 토큰 분포 계산 (log 확률)
log_probs = model.get_log_probs(input_x, seq)
# 상위 V' (또는 |V|)개 토큰 선택
top_tokens = select_top_k(log_probs, k=beam_width)
for token, logp in top_tokens:
new_seq = seq + [token]
new_score = score + logp
all_candidates.append((new_seq, new_score))
# 전체 후보 중 누적 점수 상위 beam_width 개만 선택해 빔 갱신
beam = sorted(all_candidates, key=lambda x: x[1], reverse=True)[:beam_width]
# 모든 빔 시퀀스가 종료 토큰으로 끝나면 중단
if all(seq[-1] == '</s>' for seq, _ in beam):
break
# 최종 빔에서 점수가 가장 높은 시퀀스 반환
best_sequence, best_score = max(beam, key=lambda x: x[1])
return best_sequence, best_score
* `model.get_log_probs(input_x, seq)`: 입력 $x$와 현재 시퀀스 $y_{1\!:\!t-1}$를 주면 다음 토큰 $y_t$의 모든 어휘에 대한 로그 확률 분포 $\log p(y_t \mid y_{1\!:\!t-1}, x)$를 반환하는 함수다.
* `select_top_k(log_probs, k)`: 주어진 로그 확률 딕셔너리에서 가장 높은 $k$개의 토큰과 그 값을 뽑아 리스트로 반환한다.
★ 결론
Beam Search는 순차적 생성 작업에서 완전 탐색 대비 계산량을 줄이면서도 좋은 품질의 결과를 얻을 수 있게 해주는 근사 탐색 기법이다. 그러나 빔 폭과 어휘 크기에 따라 연산량과 메모리 사용량이 급격히 증가하고, 전역 최적해를 항상 찾지 못하며, 길이 편향 문제가 있다는 한계가 있다. 이를 극복하기 위해 길이 정규화, 커버리지 패널티, 다양한 빔 그룹화 기법 등 여러 확장 기법이 제안되고 실제 응용에서 널리 사용되고 있다.