본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
Abstract
최근 공개된 DeepSeek-R1 모델은 일부 벤치마크에서 GPT-4o·Claude에 필적하는 성능을 훈련 비용의 일부만으로 달성해 주목받았다. 본 논문은 “짧은 텍스트로부터의 결과 예측”이라는 공통 프레임을 설정하고, 두 분류 과제 ① 저자 판별(Authorship Classification, AC) ② 인용 유형 분류(Citation Classification, CC)에서 DeepSeek-R1을 Claude-3.5-Sonnet, Gemini-1.5-Flash, GPT-4o-mini, Llama-3.1-8B와 동일 조건으로 비교한다.
- 정확도 : DeepSeek-R1은 대부분 Gemini·GPT·Llama보다 낮은 오류율을 기록하지만 Claude보다 높다.
- 속도·비용 : DeepSeek-R1이 가장 느리지만 비용이 최저이며, Claude는 최고 정확도·최고 비용을 보인다.
- 데이터 자산 : 저자들은 MadStatAI(저자 판별용)와 CitaStat(인용 분류용) 두 공개 데이터셋을 구축하여 후속 연구의 벤치마크로 제시한다.
1. Introduction
1) 연구 배경
(1) DeepSeek-R1은 2025-01-20 공개 직후 “GPT-급 정확도·저비용”이라는 평판을 얻었으나
체계적 비교 연구가 부족하였다 .
(2) LLM은 별도 학습 없이 프롬프트만으로 분류를 수행할 수 있으므로, 짧은 텍스트 분류가
합리적 비교 척도다 .
2) 연구 목표
(1) DeepSeek-R1과 4대 LLM(Claude, Gemini, GPT, Llama)을 정확도·연산 시간·비용·예측 유사도
측면에서 비교.
(2) 비교 과제:
a) Authorship Classification(AC)
b) Citation Classification(CC)
3) 연구 기여
(1) 두 과제 제안과 통일된 실험 프로토콜.
(2) 두 공개 데이터셋:
a) MadStatAI – 1746건 초록 삼중 데이터(세 가지 버전[hum, AI, humAI가 한 세트인 초록 582세트)
b) CitaStat – 2980건 완전 라벨 인용 데이터(3000건에서 확실하지 않은 20건의 라벨 제거)
1.1 Authorship Classification
1) 데이터 생성
(1) 원천: MADStat(1975 - 2015 기간동안 36개의 저널에 출판된 통계학 논문 83,331편).
(2) 작업 절차:
a) 논문 ≥ 30편 저자 15명 무작위 추출 후 공저 확인 제거 → 582 편 초록 확보 .
b) 각 초록에 대해 세 버전 제작:
(a) hum (원문 초록)
(b) AI – GPT-4o-mini로 제목만 주어 새 초록 생성
(c) humAI – 원문 초록을 GPT-4o-mini로 부분 편집
→ 총 1 746 문서 → MadStatAI .
2) 실험 설계
(1) AC1 – hum vs AI
(2) AC2 – hum vs humAI
(3) 각 실험 샘플 1 164 개(클래스 50 %씩), 동일 프롬프트: “human or ChatGPT” 사용 .
1.2 Citation Classification
1) 데이터 생성
(1) 대상: 1996-2020 통계학 4대 저널(Annals of Statistics 외) PDF 전수 → 인용구 포함 367K 문장 추출.
(2) 표본·라벨링: 3 000건 무작위 추출 후 4개 범주 수작업 라벨(FI·TB·BG·CP)
→ FI (Fundamental Idea)
: 해당 인용문은 인용된 논문이 현재 연구의 핵심 개념 또는 근본 이론을 제공하고 있음을 나타냄
→ TB (Technical Basis)
: 인용된 논문이 도구, 알고리즘, 분석 방법, 데이터 등을 제공하여 현재 연구의 기술적 기반이 되었음을 의미
→ BG (Background)
: 인용된 논문이 연구 배경이나 관련 문헌으로써 기능하며, 직접적으로 현재 연구에 영향을 주지는 않음
→ CP (Comparison)
: 인용된 논문이 현재 연구와 성능·결과·접근법 등을 비교하는 데 사용된다.
→ ‘불확실’ 20건 제외 → 2 980 건 CitaStat 완성 .
(3) 클래스 분포: BG(57.8 %) > TB(26 %) > CP(10.6 %) > FI(5.7 %) .
2) 실험 설계
(1) CC1 – 4-class(FI, TB, BG, CP)
(2) CC2 – 2-class(S = FI+TB, I = BG+CP)
(3) DeepSeek-R1은 실행 시간 문제로 5 % 표본(149건)에만 평가, 대신 DeepSeek-V3 전량 평가
1.3 Results & Contributions
1) 분류 정확도 (Classification Error)
- Claude는 4개 실험 모두에서 최저 오류율을 기록하며 일관된 최고 성능을 보였다.
- DeepSeek-R1은 Claude보다는 다소 낮은 성능이지만, 대부분의 경우 Gemini, GPT, LLaMA보다 우수했다.
- GPT는 AC1·AC2에서 오류율이 무작위 추측 수준이었으나, CC1·CC2에서는 더 나은 성능을 보였다.
- LLaMA는 랜덤 수준이거나 그보다 나쁜 오류율을 기록하며 성능이 전반적으로 저조했다.
2) 추론 속도 (Computing Time)
- Gemini와 GPT는 가장 빠른 모델이다.
- DeepSeek-R1은 가장 느린 모델이며, 구버전인 DeepSeek-V3는 다소 빠르지만 성능은 R1보다 낮다.
3) 비용 (Cost)
- Claude는 CC1과 CC2 기준으로 $12.30으로 가장 비쌌다.
- LLaMA는 $1.20,
- DeepSeek, Gemini, GPT는 모두 $0.30 이하로 상대적으로 저렴했다.
3)출력 유사도 (Output Similarity)
- DeepSeek는 출력 패턴이 Claude 및 Gemini와 유사했다.
- GPT와 LLaMA는 AC1·AC2에서 서로 높은 유사도를 보였으나, 전반적으로 낮은 성능을 기록했다.

2. Main results
이 장에서는 저자들이 수행한 네 가지 실험(AC1, AC2, CC1, CC2)에 대해 DeepSeek와 Claude, Gemini, GPT, LLaMA 등 5개 LLM을 정량적으로 비교한 결과를 제시한다
2.1 Authorship classification results
1) 목적
- 인간이 작성한 초록(hum)과 AI가 생성하거나 편집한 초록(AI, humAI)을 구별하는 2-class 분류 문제
- AC1: hum vs AI
- AC2: hum vs humAI
2) 데이터: MadStatAI
- 원천: MADStat 메타데이터 (1975–2015년 36개 통계학 저널, 총 83,331편 논문)
- 저자 15명 무작위 추출(논문 수 ≥ 30), 공저 제거
- 각 초록에 대해 세 버전 생성:
(a) hum (원문 초록)
(b) AI (제목만 주고 GPT-4o-mini가 작성)
(c) humAI (원문 초록을 GPT-4o-mini가 부분 편집) - 최종: 582개의 삼중항(triplet) → 총 1,746개 문서
3) 실험 설계
- AC1, AC2 각각 1,164개 샘플
- 동일 프롬프트: "human" 또는 "ChatGPT" 중 하나만 출력
- Zero-shot (학습 없음)
4) 실험 결과
(1) 오류율(Error Rate)
AC1 (hum vs AI):
- Claude: 0.218 → 가장 낮은 오류율, 최고 성능
- DeepSeek-R1: 0.286 → Claude 다음으로 우수
- Gemini: 0.468, GPT-4o: 0.511, LLaMA: 0.511 → 0.468 이상으로 사실상 랜덤 추측 수준
AC2 (hum vs humAI):
- DeepSeek-R1: 0.405 → 가장 낮은 오류율, Claude(0.435)보다 우수
- Claude: 0.435
- Gemini: 0.500, GPT-4o: 0.502, LLaMA: 0.501 → 판별 성능 낮음(사실상 무작위 선택, 즉 찍기 수준임)
(2) 추론 시간(Inference Time)
- 가장 빠른 모델:
- Gemini: 6분
- GPT-4o: 7–8분
- 가장 느린 모델:
- DeepSeek-R1: 183–235분 (약 3–4시간 소요)
- 중간권 모델:
- Claude: 7분
- LLaMA: 11–12분
(3) 비용(Cost, USD)
- 가장 비용 효율적:
- DeepSeek-R1: $0.04–$0.05
- 중간권 모델:
- Gemini: $0.09–$0.10
- GPT-4o: $0.10–$0.12
- LLaMA: $0.17–$0.20
- 가장 고가:
- Claude: $0.30–$0.50
(4) 예측 유사도
- GPT·Gemini·LLaMA는 대부분 “human”으로 응답 → 서로 거의 유사
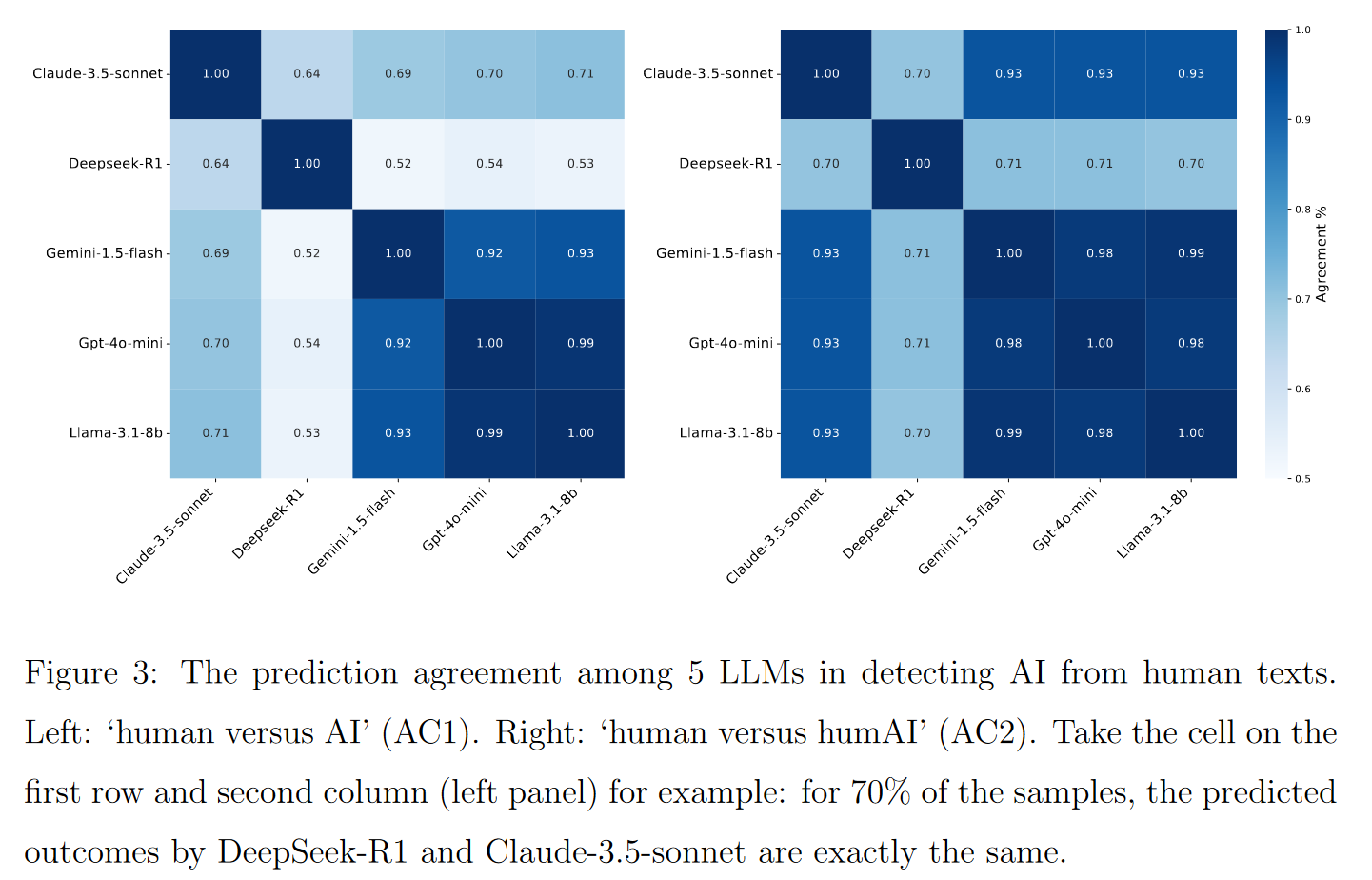
- Claude와 DeepSeek는 판단 기준이 다름(예측 경향이 다르다) → 하기 표의 예측 일치율이 64%(AC1), 70%(AC2) 에 불과함을 알 수 있다.
2.2 Citation Classification
1) 목적
- 인용문의 문맥에 따라 인용이 중요(Salient)한지 부차(Incidental)한지를 분류
- CC1: 4-class (FI, TB, BG, CP)
- CC2: 2-class (S = FI+TB, I = BG+CP)
2) 데이터: CitaStat
- 출처: 통계학 4대 저널 PDF 전체 (1996–2020)
- 총 367,000건 인용문 중 무작위 3,000건 추출
- ‘불확실’ 라벨 20건 제외 → 2,980건 라벨링 완료
- 클래스 분포: BG(57.8%), TB(26%), CP(10.6%), FI(5.7%)

3) 실험 구성
- 모든 모델 동일 프롬프트

- DeepSeek-R1은 5% 표본(149건)만 실행
- DeepSeek-V3는 전체 샘플에 대해 실행
4) 실험 결과
(1) 오류율(Error Rate)
CC1 (4-class):
- Claude: 0.327 → 가장 낮은 오류율, 최고 성능
- Gemini: 0.347, GPT-4o: 0.363 → 중간 성능
- DeepSeek-R1: 0.403 (5% 샘플 기준) → Claude·GPT 사이
- DeepSeek-V3: 0.432
- LLaMA: 0.576 → 가장 낮은 성능
CC2 (2-class):
- Claude: 0.261 → 가장 낮은 오류율
- DeepSeek-R1: 0.275 → Claude 다음으로 우수
- Gemini: 0.313, DeepSeek-V3: 0.332, GPT-4o: 0.371 → 중간 성능
- LLaMA: 0.457 → 최하위
(2) 추론 시간(Inference Time)
- 가장 빠른 모델:
- GPT-4o: 15분, Gemini: 25분
- 가장 느린 모델:
- DeepSeek-V3: 3–4시간, LLaMA: 4–5시간
- 중간권 모델:
- Claude: 1–2시간, DeepSeek-R1: 전체 미실행 (5% 샘플만 평가)
(3) 비용(Cost, USD)
- 가장 비용 효율적:
- DeepSeek-V3: $0.08
- DeepSeek-R1: $0.04–$0.05 수준으로 추정 (전체 비용 미기재)
- 중간권 모델:
- Gemini: $0.12, GPT-4o: $0.30, LLaMA: $1.20
- 가장 고가:
- Claude: $12.30 (CC1 + CC2 전체 실행 기준)

5) 난이도별 오류율
CitaStat 데이터셋 내 인용문 2,980건을 오류율 기준으로 세 구간으로 나눔:
- Easy (하위 30%) / Medium (중간 40%) / Difficult (상위 30%)
※ DeepSeek-R1은 전체 샘플에 대한 실행이 아니므로 분석에서 제외됨. - Easy 그룹에서는 대부분 모델이 오류율 0.01 미만 (예외: LLaMA는 0.063)
- Medium 그룹에서 가장 낮은 오류율은 Claude (0.177), 다음은 Gemini (0.211)
- Difficult 그룹에서는 모든 모델 성능이 급락
→ GPT가 가장 낮은 오류율(0.832), DeepSeek-V3는 가장 높은 오류율(0.956)

6) 예측 유사도 분석
- DeepSeek-R1은 전체 샘플을 실행하지 않았기 때문에 유사도 분석에서 제외됨
- 5개 모델(Claude, DeepSeek-V3, Gemini, GPT, LLaMA) 간 예측 일치율을 4-class(CC1), 2-class(CC2) 각각에 대해 계산
- Claude–Gemini, Claude–DeepSeek-V3, Gemini–DeepSeek-V3 간 유사도가 높음 (최대 83%)
- LLaMA는 모든 모델과의 유사도가 낮음, 특히 2-class에서도 < 67%
- GPT는 Claude 및 Gemini와는 중간 수준 유사도 유지

3. Discussion
(1) 연구 동기 및 비교 대상
- DeepSeek은 2025년 1월 20일 최신 버전 공개 이후 AI 커뮤니티 안팎에서 큰 관심을 받음.
- 이에 따라 Claude, Gemini, GPT, LLaMA 등 기존의 대표적인 LLM들과 DeepSeek을 비교하는 것이 중요함.
- 비교 과제는 짧은 텍스트 기반 예측에 초점을 둔 두 분류 문제:
- 저자 판별 (Authorship Classification)
- 인용 유형 분류 (Citation Classification)
(2) 주요 발견
- 정확도 측면에서:
- DeepSeek은 Gemini, GPT, LLaMA보다 항상 우수
- 하지만 Claude보다는 일관되게 낮은 성능
(3) 향후 확장 방향 제안
- 다양한 과제 확장
- 예: 자연어처리(NLP), 컴퓨터비전(CV) 과제
- 예시로 ImageNet 분류 정확도 비교 실험 제안
- 프롬프트 개선을 위한 통계 기법 결합
- 예: 저자 판별에서 AI-작성 vs 인간-작성 텍스트 간 판별력 있는 단어 집합을 통계적으로 선별
- 이를 기존 프롬프트에 삽입하여 성능 향상 기대
- 데이터셋 활용 확대
- MadStatAI: AI 생성 문서의 특징 분석에 활용 가능
- CitaStat: 저자 영향력 측정, 연구 주제 추정 등에 활용 가능 (예: Ji et al., 2022; Ke et al., 2024)