참고 문헌:
1. 서강대 AI MBA 데이터마이닝 강의교재 (2023)
2. Müller, A. C., & Guido, S. (2016). *Introduction to Machine Learning with Python*. 1st Edition. O’Reilly Media, Inc., Sebastopol, CA. ISBN: 978-1449369415.
랜덤 포레스트(Random Forest)는 여러 개의 결정 트리(Decision Tree)를 모아서 더 좋은 모델을 만드는 앙상블 기법이다. 결정 트리 하나만으로는 과적합(overfitting) 문제가 생기기 쉬운데, 랜덤 포레스트는 그 문제를 해결할 수 있다. 여러 트리를 사용해서 데이터를 학습하고 예측함으로써, 과적합을 방지하면서 성능을 높일 수 있는 방법이다.
각 트리별로 N개의 feature를 사용해서 회귀, 분류하는데, N feature 값을 n 개로 지정시, 분기시마다 n개의 feature를 사용한다.
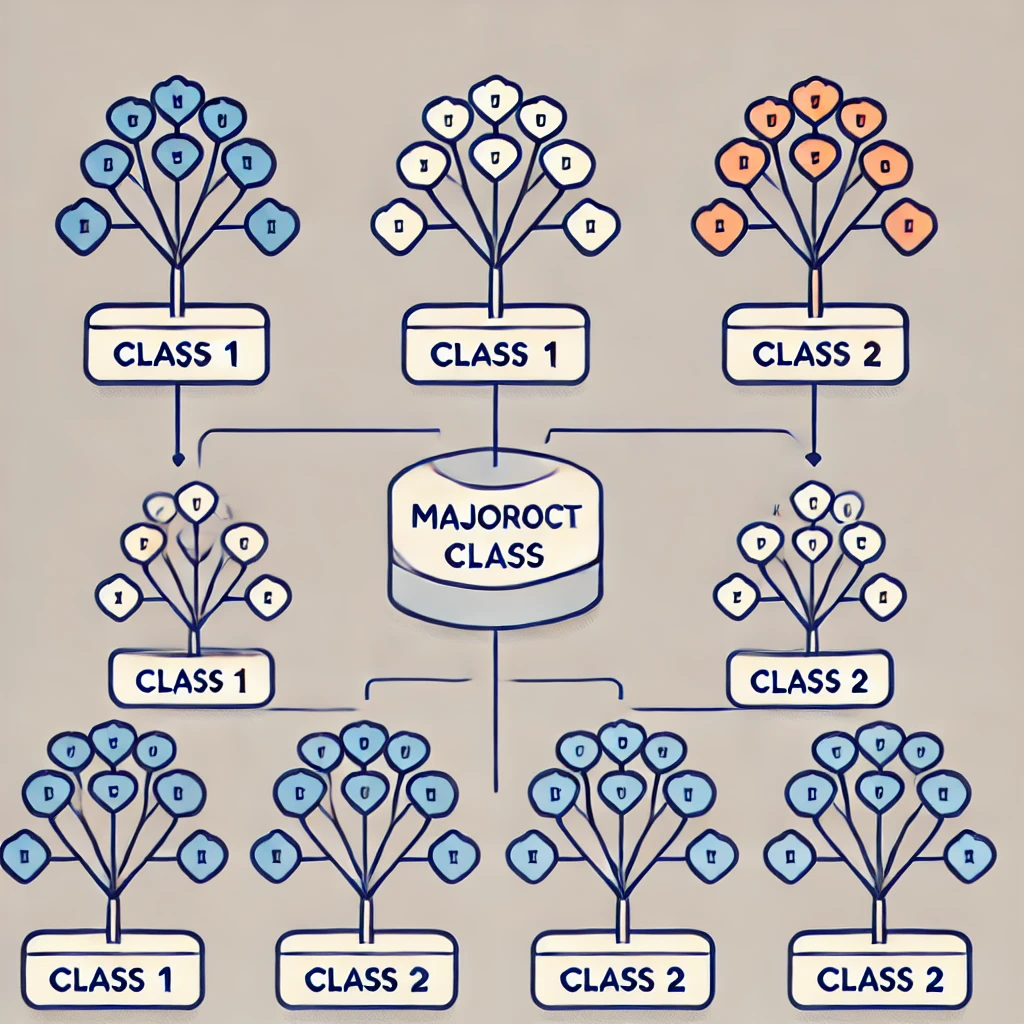
랜덤 포레스트의 주요 특징:
- 과적합 문제 해결:
- 랜덤 포레스트는 여러 트리를 학습해서 각각 독립적으로 예측을 하고, 그 결과를 종합해서 과적합을 줄이는 방식이다. 트리 하나가 과적합되어도, 여러 트리가 평균적으로 좋은 예측을 하기 때문에 문제를 덜어준다.
- 여러 결정 트리의 집합:
- 랜덤 포레스트는 여러 개의 트리가 모인 것이다. 각 트리가 무작위로 데이터를 학습해서 예측을 진행하는데, 이 무작위성 덕분에 더 일반화된 모델을 만들 수 있다.
- 분류에서는 투표:
- 분류 문제에서는 각 트리가 예측한 클래스 중에서 다수결 투표로 최종 예측을 결정한다. 여러 트리가 다른 예측을 하더라도, 가장 많은 트리가 선택한 클래스가 최종 결과가 된다.
- Hard Voting과 Soft Voting은 앙상블 기법에서 사용하는 두 가지 방식이다. 랜덤 포레스트는 기본적으로 Hard Voting을 사용하며, 각 트리가 예측한 클래스 레이블을 다수결로 결정한다. 가장 많은 트리가 선택한 클래스가 최종 결과가 된다. 예를 들어, 7개의 모델 중 4개가 Class 1을, 3개가 Class 2를 예측하면 최종 예측은 Class 1이다. Hard Voting은 단순히 레이블을 비교하고 확률을 고려하지 않는 방식이다.
- 반면, Soft Voting은 각 모델이 예측한 클래스 확률을 평균내어 최종 예측을 결정한다. 각 모델이 반환한 확률들의 평균을 구해 가장 높은 확률을 가진 클래스를 선택하는 방식이다. 확률 정보가 있는 경우 더 정교한 예측이 가능하다. 예를 들어, Class 1의 확률 평균이 0.65, Class 2가 0.35라면 최종 예측은 Class 1이 된다.
- Weighted Voting:
- Hard Weighted Voting: 각 모델이 예측한 클래스에 가중치를 곱한 후 다수결로 최종 예측을 결정한다. 가중치가 높은 모델의 예측이 더 큰 영향을 미친다.
- Soft Weighted Voting: 각 모델이 반환한 클래스 확률에 가중치를 곱하고, 그 확률들의 평균을 계산해 최종 예측을 결정한다. 이 방식은 확률이 높은 모델이 더 중요한 역할을 한다.
- Hard Voting: 각 모델의 클래스 레이블을 다수결로 결정.
- Soft Voting: 각 모델의 클래스 확률을 평균내어 결정.
- Weighted Voting: 모델별로 가중치를 부여하여 더 성능이 좋은 모델에 더 많은 영향을 주어 최종 예측을 결정.
- 회귀에서는 평균:
- 회귀 문제에서는 각 트리가 예측한 값을 평균 내어 최종 결과를 계산한다. 이렇게 함으로써 여러 트리의 예측이 평균화되어 노이즈가 줄어들고 더 정확한 예측이 가능하다.
랜덤 포레스트의 장점:
- 높은 예측 성능: 다양한 트리의 예측을 결합하기 때문에 예측 성능이 매우 뛰어나다.
- 과적합 방지: 개별 트리가 과적합되더라도, 여러 트리의 예측을 평균화함으로써 과적합을 방지할 수 있다.
- 데이터 스케일링 불필요: 데이터 스케일링이나 정규화를 필요로 하지 않는다.
- 파라미터 튜닝에 민감하지 않음: 기본 설정으로도 좋은 성능을 발휘하며, 파라미터 튜닝이 많이 필요하지 않다.
- 다양한 특성 반영: 무작위로 선택된 특성을 사용해 학습하므로, 다양한 특성을 반영할 수 있고 복잡성을 줄일 수 있다.
랜덤 포레스트의 단점:
- 해석의 어려움: 여러 트리를 결합한 앙상블 모델이므로, 개별 트리처럼 직관적으로 해석하기 어렵다.
- 메모리 사용량과 학습 시간: 많은 트리를 학습시켜야 하므로 메모리를 많이 사용하고, 학습과 예측 시간이 비교적 오래 걸린다. 특히 큰 데이터셋에서 더 많은 자원이 필요하다.
- 고차원, 희소 데이터에서 성능 저하: 매우 고차원적이거나 희소한 데이터(예: 텍스트 데이터)에서는 성능이 떨어질 수 있으며, 이런 경우 선형 모델이 더 적합할 수 있다
추가 용어 정리
- Bootstrap:
- 복원추출방식으로, 데이터를 샘플링하는 방법 중 하나이다. 원 데이터셋에서 샘플을 추출할 때, 추출된 데이터를 다시 포함시켜 다음 샘플에서도 추출될 수 있게 한다.
- Bagging:
- Bootstrap Aggregating의 줄임말이다. 여러 개의 bootstrap 샘플을 사용하여 각각 독립적인 모델을 학습한 후, 이 모델들의 예측을 결합하여 최종 예측을 만든다. 랜덤 포레스트는 Bagging의 대표적인 예이다.
- Boosting:
- 모델을 생성할 때, 이전 모델의 오차를 보완하는 방식으로 점점 더 강력한 모델을 만드는 방법이다. 각 모델에 가중치를 부여하여 성능을 향상시키는 방식이다. 대표적으로 XGBoost, AdaBoost 등이 있다.
- Ensemble:
- 여러 개의 Base 모델(기초 모델)을 학습시킨 후, 이들의 예측을 다수결, 평균 등의 방법으로 결합하여 최종 결과를 도출하는 방법이다. 앙상블 방법은 다양한 모델의 강점을 결합해 성능을 향상시킨다.
참고: '앙상블(Ensemble)'이라는 용어는 프랑스어로 '조화, 통일'을 의미한다.
'데이터분석' 카테고리의 다른 글
| CHAPTER 3: 비지도 학습(Unsupervised Learning)과 전처리(Preprocessing) (0) | 2025.03.05 |
|---|---|
| Chapter 2. 지도학습(Supervised learning): 부스팅(Boosting) (0) | 2024.09.21 |
| Chapter 2. 지도학습(Supervised learning): 의사결정나무(Decision Trees) (0) | 2024.09.02 |
| Chapter 2. 지도학습(Supervised learning): Naive Bayes classifier (1) | 2024.09.02 |
| Chapter 2. 지도학습(Supervised learning): SVM (0) | 2024.08.27 |