* 본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다
ABSTRACT
인공지능 기술의 발전으로 청소년 스포츠 자세 교정용 3D 포즈 추정 시스템에 대한 관심이 높아지고 있다. 기존 기법들은 복잡한 동작, 실시간 피드백 제공, 다양한 자세 처리에서 특히 가림(occulusion), 빠른 움직임, IoT 장치의 연산 자원 제약으로 인해 정확도와 실시간 성능 간 균형을 이루기 어렵다. 이를 해결하기 위해 본 논문에서는 IoT 환경과 $\textbf{GTA-Net}$을 제안한다.
- $\textbf{핵심 구성}$
- 관절 및 뼈대 정보 모델링을 위한 Graph Convolution Networks, 시계열 특성 학습을 위한 Temporal Convolution Networks, 중요 시공간 특징 강조를 위한 Hierachical Attention을 결합 - $\textbf{실시간 교정}$
- IoT 장치에서 실시간으로 자세 추정 및 교정 피드백 제공 - $\textbf{우수한 성능}$
- Human3.6M, HumanEva-T, MPI-INF-3DHP 데이터셋에서 각각 MPJPE 32.2mm, 15.0mm, 48.0mm를 달성, 기존 방법 대비 유의미한 성능 향상 - $\textbf{강인성}$
- 가림 및 빠른 동작 상황에서도 높은 정확도 유지
이를 통해 GTA-Net은 청소년 스포츠 및 헬스케어 분야에서 실시간 자세 교정과 건강 관리에 폭넓게 활용될 수 있는 실용적 솔루션임을 입증한다.
Introduction
현대 사회에서 건강 의식 확산과 교육 정책 강화로 청소년의 스포츠 참여율이 크게 증가하였다. 학교 체육 수업은 물론 방과 후 스포츠 클럽 및 훈련 프로그램에서 다양한 운동을 접하는 청소년들은 신체 발달과 팀워크 · 경쟁심 함양에 이바지하지만, 전문지도 부재로 잘못된 자세를 유지하다가 장기적으로 근육 긴장, 관절염, 척추 측만증 등 부상 위험이 높아진다. 청소년기는 골격과 근육이 미성숙한 시기로, 부정확한 운동 자세는 성장에 치명적 영향을 미칠 수 있어 즉각적으로 정확한 자세 교정이 필수적이다.
전통적 자세 교정은 코치나 교사의 시각적 관찰 및 영상 분석에 의존하는데, 이는 시간 · 노력 소모가 크고 인간 오류에 취약하여 대규모 학급이나 훈련 환경에서 실시간 · 정확한 모니터링이 어렵다. 반면 IoT와 AI 기술 발전으로 고성능 센서와 3D 포즈 추정 알고리즘을 결합하면, 운동 중인 청소년의 자세를 실시간으로 정밀하게 캡처 · 분석하고 자동으로 교정 제안을 제공할 수 있는 기반이 마련되었다.
그러나 기존 연구들은 2D 프레임별 DNN 기반 접근 이나, CNN, FCN, 단일 시점 CNN 등을 이용해 2D 키포인트나 단일 뷰 3D 포즈를 예측했으나, 이들은 다음과 같은 한계로 실용화에 제약을 받는다.
- $\textbf{시간 정보 결여}$
: 동적 움직임에서 연속 프레임 간 변화 포착 미흡 - $\textbf{2D 정보 의존}$
: 깊이 정보 부족으로 복잡 3D 자세 처리 한계 - $\textbf{입력 품질 민감}$
: 노이즈 · 가림 · 시점 변화 시 정확도 및 안정성 저하 - $\textbf{실시간 피드백 부재}:$
: 대규모 집단에 대한 저지연 교정 지원 어려움
따라서 본 연구에서는 IoT 환경과 통합된 3D 포즈 추정 시스템 $\textbf{GTA-Net}$을 제안한다. 이 시스템은 Graph Convolution Network, Temporal Convolution Network, 계층적 어텐션 메커니즘을 결합하여 청소년 스포츠 자세를 실시간으로 고정밀 교정 ·피드백할 수 있는 새로운 솔루션을 제시한다.
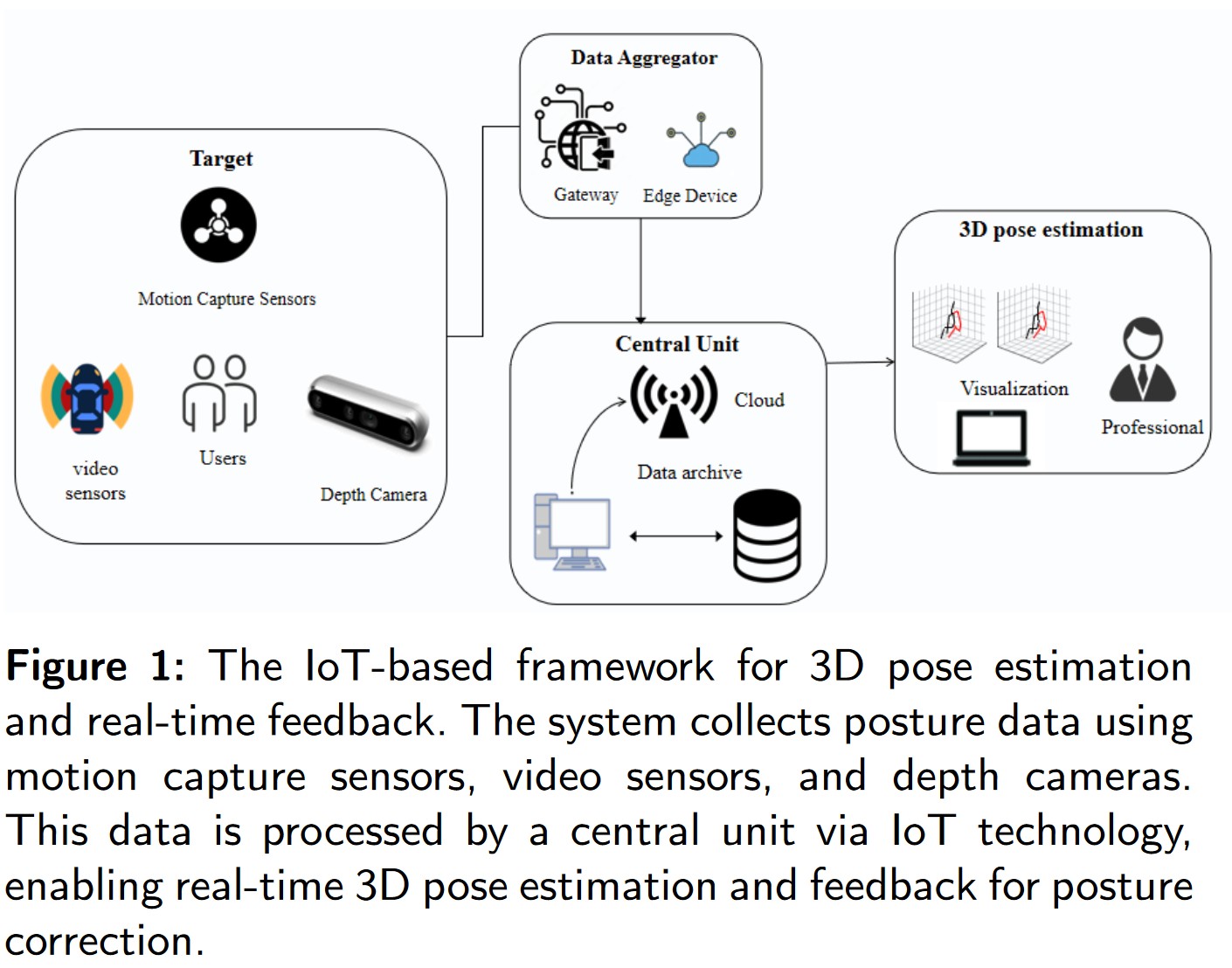
2. Related Work
2.1. The Evolution from 2D to 3D Pose Estimation
컴퓨터 비전 기술의 발전에 따라 인간 포즈 추정은 단일 시점 2D 키포인트 검출 (Hough Transform, HOG)에서 시작하여, CNN 기반 다중 해상도 특징 맵을 활용한 2D 추정으로 주류가 되었다. 그러나 2D 방식은 깊이 정보 부재로 복잡 동작과 깊이 변화 처리에 한계가 있었다. 이를 극복하기 위해 2D 키포인트를 FCN으로 3D 좌표로 직접 회귀하는 기법이 제안되었으나, 입력 품질 (노이즈 · 가림 · 시점 변화)에 민감하여 안정성이 떨어졌다.
후속 연구에서는 인간 스켈레톤 위상 정보를 활용한 GCN을 도입하여 3D 공간 매핑과 구조적 강인성을 개선했으며, Conditional GAN을 통해 생성된 3D 포즈를 보정함으로써 정확성과 안정성을 더욱 향상시켰다.
또한, TCN · LSTM 기반 시계열 기법을 도입하여 연속 프레임 간 동작 변화를 모델링함으로써 3D 추정의 일관성과 정확도를 높였고, 다중 시점 융합 기법을 통해 다양한 카메라 뷰를 결합하여 3D 재구성 정확도를 대폭 향상시켰다. 다만, 다중 시점 융합은 높은 연산 복잡도를 야기하여 효율적 비용 절감 방안이 여전히 중요한 연구 과제로 남아 있다.
2.2. Applications and Technical Challenges of 3D Pose Estimation in Complex Scenarios
3D 포즈 추정은 다음과 같은 복잡한 환경에서 주요 기술적 어려움을 겪는다.
- $\textbf{다중 대상 및 밀집 장면}$에서는 객체 간 가림(Occlustion)과 상호 간섭으로 단일 대상 전용 기법이 부정확해지고, 실시간 다중 대상 추적 · 예측이어려움
- $\textbf{빠른 동작 · 큰 회전}$ 상황에서는 연속 프레임 간 급격한 자세 변화 포착 실패로 추정 오차가 커짐.
- $\textbf{광학 흐름 · 다중 프레임 융합}$ 및 $\textbf{TCN/LSTM 시계열 모델링}이 안정성과 정확도를 높이나, 여전히 높은 연산량과 지연(latency) 문제가 남음
- $\textbf{Occlusion 처리}$를 위해 문맥 인식 및 부분 복원 기법으로 누락된 관절을 추론하지만, 복잡 상호작용 장면에서 완전 보정은 불가능에 가까움
- $\textbf{실시간 · 고정밀 · 저연산}$을 동시에 달성하기 위해서는 하드웨어 가속, 모델 경량화(프루닝 · 양자화 · 지식 증류), 효율적 데이터 처리 기법의 결합적 연구가 필요
- $\textbf{어플리케이션별 요구}$ (VR/AR의 동기화, 자율주행의 보행자 포즈 인식 등)가 다양해, 분야별 최적화가 필수적
이처럼 3D 포즈 추정의 실용화를 위해서는 정확도, 응답 속도, 계산 효율성 간 균형을 이루는 통합적 해결책이 요구된다.
3. Method
3.1 Overview of our network
본 연구에서는 청소년 스포츠 자세 및 교정 실시간 피드백을 위해 $\textbf{GTA-Net}$(Graph-Temporal Attention Network)을 제안한다. 이 모델은 다음 세 가지 모듈로 구성된다.
- $\textbf{Joint-GCN}$
: 동영상에서 추출된 2D 키포인트 간의 국소 공간적 관계를 그래프 컨볼루션으로 모델링하여 각 관절의 세부 특징을 추출 - $\textbf{Bone-GCN}$
: 관절을 연결하는 뼈대 구조의 전역 정보를 그래프 컨볼루션으로 학습해, 복잡한 동작에서도 전체 자세의 일관성과 안정성을 확보 - $\textbf{Hierarchical Attention-argumented TCN}$: GCN으로부터 얻은 3D 키포인트 특징을 시계열 컨볼루션(TCN)에 입력하여 관절 위치 변화와 연속적 동역학을 포착하고, Temporal Attention과 Spartial Attention으로 정확도와 강인성을 동시에 향상
- Temporal Attention
: 프레임별 주요도를 동적으로 가중치로 반영 - Spartial Attention
: 핵심 관절 · 뼈대 영역에 집중
- Temporal Attention
또한, Iot 인프라를 통해 카메라 및 센서 데이터를 엣지 클라우드로 분산 처리함으로써 실시간 교정 피드백을 가능케 한다. 이에 따라, 빠른 움직임에서도 정밀하고 일관된 3D 포즈 추정을 제공하며, 청소년 스포츠 자세 교정에 최적화된 솔루션을 구현하였다.
3.2 Joint-GCN and Bone-GCN
Joint-GCN과 Bone-GCN은 인간 스켈레톤의 국소 및 전역 공간 정보를 각각 학습하도록 설계된 그래프 컨볼루션 네트워크(GCN) 변형이다. 아래 수식 단계별로 그 역할과 필요성을 정리한다.
- 자기 연결 추가(Self - Loop)
노드가 자신의 특징을 유지하도록 인접 행렬에 단위 행렬을 더한다.
$$\mathbf{A} = \mathbf{A} + \mathbf{I}, \tag{2}$$
이후 GCN 연산시,
$$\mathbf{A}' \, \mathbf{H}^{(l)} =\mathbf{A} \, \mathbf{H}^{(l)} \;+\; \mathbf{I} \, \mathbf{H}^{(l)} = \sum_{j \in \mathcal{N}(i)} H_j^{(l)} \;+\; H_i^{(l)} $$
여기서
$\mathbf{A} \, \mathbf{H}^{(l)} $ 는 이웃 노드들의 특징 집계이고,
$\mathbf{I} \, \mathbf{H}^{(l)} $ 는 자기 자신 노드 ${i}$의 특징 $H_{i}^{(l)}$ 를 그대로 더해 주는 부분이다.
따라서 단위 행렬 $I$ 를 더함으로써 "자신의 고유 특징 $H_i^{(l)}"$ 가 이웃 정보와 함께 항상 보존된다.
예를 들어 노드 $i$가 “목(neck)” 위치라고 하고, 이웃 노드들이 “머리(head)”, “왼쪽 어깨(shoulder\_L)”, “오른쪽 어깨(shoulder\_R)” 등이라고 하면,
* 자기 자신 특징: $H_i^{(\ell)} = H_{\text{neck}}^{(\ell)}$
* 이웃 특징: $H_{a}^{(\ell)} = H_{\text{head}}^{(\ell)},\; H_{b}^{(\ell)} = H_{\text{shoulder\_L}}^{(\ell)},\; H_{c}^{(\ell)} = H_{\text{shoulder\_R}}^{(\ell)},\dots$
이때
$$
\mathbf{A}\,\mathbf{H}^{(\ell)}
= \sum_{j\in\mathcal{N}(i)}H_j^{(\ell)}
= H_{\text{head}}^{(\ell)} + H_{\text{shoulder\_L}}^{(\ell)}
+ H_{\text{shoulder\_R}}^{(\ell)} + \cdots
$$
로 표현되는 것이고, 이 합산된 이웃 특징을 $\mathbf{A}\,\mathbf{H}^{(\ell)}$로 간단히 쓴 것이다.
여기에 $\mathbf{I}\,\mathbf{H}^{(\ell)} = H_{\text{neck}}^{(\ell)}$ 을 더해 주는 것이 바로 자기 연결(self‐loop)이고,
$
(\mathbf{A} + \mathbf{I})\,\mathbf{H}^{(\ell)}
= \underbrace{\sum_{j\in\mathcal{N}(i)}H_j^{(\ell)}}_{\mathbf{A}\mathbf{H}^{(\ell)}}
\;+\; \underbrace{H_i^{(\ell)}}_{\mathbf{I}\mathbf{H}^{(\ell)}}
$가 되는 원리다. - 인접 행렬 정규화(Normalization)
각 노드 차수 차이에 따른 정보 편중을 막고, 수치적 안정성 확보를 위해 정규화를 수행한다.
$$\hat{\mathbf{A}} =\mathbf{D}^{-\tfrac12}\,\mathbf{A}'\,\mathbf{D}^{-\tfrac12}$$
$$\mathbf{D}_{ii} = \sum_j \mathbf{A}'_{ij} \tag{3}$$
$\mathbf{D}_{ii}$는 각 노드의 차수(degree)로 이루어진 대각행렬이다. 즉, 노드 i가 연결된(이웃인) 총 개수를 나타낸다.
정리하면, 인접행렬 $A$ (자기 연결 없이)의 머리(head, 노드 0)은 목(neck, 노드 1) 하고만 연결되어 있으니
$$A_{0,\colon} \;=\; \begin{bmatrix}0 & 1 & 0 & 0 & \cdots\end{bmatrix}$$
목(neck, 노드 1)은 머리 · 몸(torso) · 왼쪽 어깨 · 오른쪽 어깨와 연결되어 있으니
$$A_{1, \colon} \;=\; \begin{bmatrix}1 & 0 & 1 & 1 & \cdots\end{bmatrix}$$
여기에, 자기 연결을 더한 행렬 $A' = A + I$를 계산하면, 머리와 목은 자기 자신 연결까지 더해져서
$$A_{0,\colon} \;=\; \begin{bmatrix}1 & 1 & 0 & 0 & \cdots\end{bmatrix}$$
$$A_{1, \colon} \;=\; \begin{bmatrix}1 & 1 & 1 & 1 & \cdots\end{bmatrix}$$
이 되고, 차수 매트릭스 $D$는 $D$의 대각 원소 $D_{ii}$는 $A'$ 행 합이고, 비대각 원소는 모두 0이므로
머리 노드(0) 의 차수: $D_{00} = \sum_j A'_{0j} = 1+1 = 2$ 이고, 목 노드(1)의 차수 : $D_{11} \;=\; \sum_j A'_{ij} = 1+1+1+1 = 4$ 이다.
이렇게 정의된 $A'$와 $D$를 이용해 정규화된 인접 행렬 $\hat A$를 만들고, GCN 연산에 활용하게 된다. 즉 각 노드가 보내는 행방향 정보량을 $\mathbf{D}^{-\tfrac12}$ 만큼 줄여주고, 받는 열 방향 정보량도 $\mathbf{D}^{-\tfrac12}$ 만큼 줄여 주어, 결과적으로 "이웃 개수가 많은 노드도, 적은 노드도 모두 같은 스케일에서 정보를 주고 받도록" 만드는 것이다.
- GCN 레이어 연산(Feature Propagation)
GCN 기본 연산은 이웃 노드들로부터 정보를 집계하여 노드 특징을 갱신하는 과정을 포함한다. 이 논문에서는 Joint-GCN, Bone-GCN 모두 3개의 레이어를 사용하였다. 이 레이어들이 얼마나 인접 이웃을 보는지 논문에 기재되어 있지 않지만 이 레이어들은 CNN과 비슷하게 레이어들을 거치면서 수용 영역(receptive field)가 넓어져, 더 먼 거리의 노드들 간 상호 작용도 학습했을 것이라 예상한다.
$\mathbf{H}^{(l+1)}=\sigma\!\bigl(\hat{\mathbf{A}}\,\mathbf{H}^{(l)}\,\mathbf{W}^{(l)}\bigr) \tag{1}$
$\mathbf{Z} = \hat{\mathbf{A}}\,\mathbf{H}^{(0)}\,\mathbf{W}^{(0)}\tag{4}$
여기서 $\mathbf{H}^{(l)}$는 $l$번째 레이어의 특징 행렬이고, $\hat{\mathbf{A}}$는 정규화된 인접 행렬이며, $\mathbf{D}$는 차수(정점)행렬(대각행렬), $\mathbf{W}^{(l)}$는 $l$ 번째 레이어에서 학습되는 가중치 행렬, 그리고 $\sigma$는 활성화 함수다. $\mathbf{Z}$는 처음 GCN 레이어를 통과한 출력 특징 행렬이고, $H^{(0)}$는 입력 특징 행렬(초기 레이어의 노드 특징), $W^{(0)}$는 첫 번째 레이어에서 학습되는 가중치 행렬이다. - 손실 함수(Loss Function)
cross-entropy loss function은 학습동안 모델 최적화, 실제값과 예측값의 비교에 사용된다.
$$\mathcal{L} = -\sum_{i \in \mathcal{V}_L}\sum_{c=1}^C Y_{ic}\,\log Z_{ic} \tag{5}$$
여기서 $\mathcal{L}$은 cross-entropy loss, $\mathcal{V}_{L}$는 레이블이 붙어 있는 노드들의 집합이며, $C$는 클래스의 총 개수, $Y_{i c}$는 노드 $i$가 클래스 $c$일 때 1, 아니면 0을 갖는 라벨 지표(label indicator), $Z_{i c}$는 노드 $i$가 클래스 $c$일 것으로 예측된 확률(predicted probability)이다.
Joint-GCN과 Bone-GCN을 결합함으로써, 국소(관절 간) 움직임과 전역(스켈레톤 구조) 정보를 동시에 추출할 수 있다. Joint-GCN은 관절 사이의 세밀한 관계를 학습하여 미세한 동작 변화도 정확히 포착하고, Bone-GCN은 뼈대 연결을 통해 전신 구조의 일관성을 유지하여 자세 추정의 안정성을 높인다. 이 두 모듈이 협력적으로 작동함으로써, GTA-Net은 동적인 움직임 속에서도 정밀하면서 왜곡없는 3D 포즈를 추정할 수 있다.


3.3. Temporal Convolutional Network
3D 사람 포즈 추정에서 시간 축의 변화, 즉 "관절이 어떻게, 언제 움직이는지"를 정확히 파악하는 것은 중요하다. 전통적인 RNN 계열 모형은 순서를 잘 처리하지만, 병렬화가 어렵고 긴 시퀀스에서는 학습이 불안정하다는 단점이 있다. 이 문제를 해결한 것이 바로 Attention-Augmented Temporal Convolutional Network(TCN)이다.
Attention-Augmented TCN은 시계열 데이터 처리에서 RNN의 한계를 극복하기 위해 고안된 구조로, 크게 세 가지 핵심 요소를 융합한다. 첫째, 인과적 컨볼루션을 적용하여 출력이 오직 현재와 과거 정보에만 의존하도록 함으로써 시계열의 자연스러운 순서를 보존하고, 미래 정보가 섞이지 않도록 보장한다. 둘째, 확장 컨볼루션을 사용해 필터의 간격을 넓히면 층을 깊게 쌓지 않고도 보다 먼 과거의 입력까지 한 번에 참조할 수 있어, 장기 의존성을 효과적으로 학습할 수 있다. 셋째, 계층적 어텐션을 도입해 각 레이어 내·외부에서 시간축과 채널별로 중요한 특징을 강조함으로써, 복잡하고 길게 이어지는 동작 패턴 속에서도 핵심 정보를 놓치지 않는다. 이 세가지 메커니즘이 결합된 TCN은 입력되는 관절 위치의 시간적 변화를 고차원 특징으로 정교하게 변환하며, 그 결과 실시간으로도 연속적인 움직임을 정확하게 추적하고 예측할 수 있어, GTA-Net의 포즈 교정 및 실시간 피드백 기능을 강력하게 지원한다.
- 인과성을 보장하는 컨볼루션
첫 번째 핵심은 "인과성"을 보장하는 컨볼루션이다.
$$y_t = \sum_{i=0}^{k-1} \omega_i * x_{t-i}$$
여기서 $y_t$는 시점 $t$에서의 출력, $x_{t-i}$ 시점 $t-i$ 의 입력, $k$는 필터 크기, $\omega_i$는 학습 가능한 필터 가중치다. 즉 출력 $y_t$는 미래 정보 없이, 오직 현재 $x_t$와 과거 $(x_{t-1},\,x_{t-2},\,\dots)$만을 참고해 계산되므로, "미래가 현재를 예측하는 일이 없다"는 물리적 의미를 잘 지킬 수 있다. - 확장 컨볼루션
두 번째 핵심은 "확장" 이다.
$$y_t \;=\;\sum_{i=0}^{k-1} w_i\,x_{\,t - d\,i} \tag{7}$$
$d$는 dilation factor고, $t - d\,i$는 필터가 ‘건너뛰며’ 본 입력 위치다. 이렇게 하면 레이어 깊이를 늘리지 않고도, 넓은 시간 범위의 의존성을 학습할 수 있다. 여기서 한 레이어만으로 보면 필터가 d 시점 간격으로 건너뛰며 보기 때문에 일부 시점은 누락될 것이라 생각할 수 있지만, 여러 레이어를 쌓으며 각 레이어마다 다른 dilation factor를 사용하면 서로 다른 해상도로 징검다리처럼 연결되어, 최종적으로 모든 시점을 커버할 수 있다. 또한 잔차 연결(residual connection) 덕분에 누락된 중간 정보도 원본 입력($x$)로 바로 흐를 수 있어, 모델이 필요한 시점의 세부 신호를 언제든 가져다 쓸 수 있다. - 레이어 전체 연산
완성된 한 레이어의 연산은 다음과 같이 요약된다.
$$Y \;=\; W \,\ast_d\, X\tag{8}$$
여기서 $X$는 전체 입력 시퀀스 벡터, $W$는 convolution 필터, $\ast_d$는 dilation이 적용된 1D 컨볼루션이다. - 잔차 연결(Residual Connection)
깊은 네트워크에서는 기울기 소실( gradient vanishing)이 일어나기 쉬운데, 이를 막기 위해 "입력 그대로 더하기"를 사용한다.
$$Z \;=\; Y + X\tag{9}$$ - 손실함수:MSE(회귀용)
포즈 추정은 수치(regression)이므로 평균제곱오차(MSE)를 사용한다.
$$\mathcal{L}\;=\;\frac1N\sum_{t=1}^N\bigl(Z_t - \hat Y_t\bigr)^2\tag{10}$$
여기서 $Z_t$는 예측한 값, $\hat Y_t$은 실제(feature) 값, $N$은 총 시점 수다. - 계층적(Hierarchical) 어텐션
여기에 계층적 어텐션을 더하면, “매 순간, 매 관절 위치에서 정말 중요한 특징”만 뽑아서 더 선명하게 살릴 수 있다.- Within-Layer Attention: 같은 레이어 내에서 중요한 시간대와 채널에 가중치 집중
- Across-Layer Attention: 레이어 간에도 “어느 단계의 정보가 더 중요한가”를 동적으로 조정
이 조합 덕분에 Attention-Augmented TCN은 실시간으로도 복잡한 동작 패턴을 놓치지 않고 포착할 수 있다. 3D 포즈 추정에서 “관절이 언제 어떻게 움직이는지”를 정밀하게 분석해야 할 때, TCN + 어텐션은 직관적이고 강력한 구조다.

3.4. Hierarchical Attention Mechanism
계층적 어텐션 메커니즘은, 복잡한 3D 포즈 추정에서 “지역적” 정보(관절 단위)와 “전역적” 정보(뼈대 전체 구조)를 동시에 강조하기 위해 설계되었다. 요약하면 다음과 같은 단계로 구성된다.
- 은닉 표현 계산
각 입력 특징 $x_i$는 선형 변환과 ReLU 활성화 함수를 거쳐 은닉 벡터 $h_i$로 매핑된다.
$$ h_i = \mathrm{ReLU}(W_h\,x_i + b_h)$$
이 과정은 원시 입력을 어텐션 계산에 적합한 공간으로 변환한다. - 어텐션 점수 산출
노드 $i$와 $j$ 사이의 상호 영향력을 측정하기 위해, 두 은닉 표현에 각각 쿼리(query)·키(key) 변환을 적용한 뒤 점곱(dot product)으로 연산하고, 스케일링($\sqrt{d_k}$로 나눔)한다.
$$e_{ij} = \frac{(h_iW_q)\,(h_jW_k)^\top}{\sqrt{d_k}}$$
이 값이 클수록 노드 $j$가 노드 $i$ 표현에 중요한 정보를 제공함을 의미한다.
– 노드 $i$와 $j$의 은닉 표현 $h_i, h_j$를 각각 쿼리($W_q$)와 키($W_k$)로 선형 변환한 뒤 내적해서 “얼마나 주목해야 할지” 점수 $e_{ij}$를 구한다.
– 루트 $\sqrt{d_k}$ 로 나누는 것은 스케일 조정(“스케일드 닷 프로덕트”)으로, 차원이 커질수록 점수가 너무 커지는 걸 막는다. - 어텐션 가중치 정규화
계산된 점수 $e_{ij}$는 소프트맥스 함수로 정규화되어, 모든 이웃 $j\in\mathcal{N}(i)$에 대한 상대적 중요도 $\alpha_{ij}$로 변환된다.
$$\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k\in\mathcal{N}(i)}\exp(e_{ik})}$$
이 단계는 정보 편중을 막고, 각 이웃이 차지하는 기여도를 합이 1이 되도록 조정한다.
– 모든 이웃 노드 $j$에 대한 점수 $e_{ij}$에 softmax를 씌워, “노드 $i$가 각 이웃 $j$에 얼마나 가중치를 줄지” $\alpha_{ij}$로 변환한다.
– $\sum_j \alpha_{ij}=1$이 되므로, 중요도가 자동으로 배분된다. - 특징 집계
정규화된 가중치 $\alpha_{ij}$를 이용해, 노드 $i$는 주변 이웃들의 은닉 표현을 가중합하여 업데이트된 표현 $h'_i$를 얻는다.
$$h'_i = \sum_{j\in\mathcal{N}(i)} \alpha_{ij}\,h_j$$
이를 통해 노드 $i$는 “중요도가 높은” 이웃 특징을 더 많이 반영한 새로운 표현을 갖게 된다.
– 정규화된 가중치 $\alpha_{ij}$를 곱해, 이웃 노드들의 은닉 표현 $h_j$를 “주의(attention) 기반으로” 가중 합산하여 노드 $i$의 업데이트된 표현 $h'_i$를 만든다. - 최종 표현 생성
모든 노드의 업데이트된 표현 $h'_i$를 합산한 뒤, 다시 선형 변환과 ReLU를 적용하여 전체 그래프(혹은 시퀀스)의 최종 집합 표현 $z$를 만든다.
$$z = \mathrm{ReLU}\!\bigl(W_z\,\sum_{i=1}^N h'_i + b_z\bigr)$$
이 벡터 $z$는 이후 TCN 모듈로 전달되어, 시간축 상에서도 유사한 어텐션이 적용된다.
– 모든 노드 $i$의 업데이트된 표현 $h'_i$를 합친 뒤, 또 한 번 선형 변환($W_z,b_z$)과 ReLU 활성화를 거쳐 그래프 전체 또는 시퀀스 전체를 대표하는 하나의 벡터 $z$를 구다.
이처럼 계층적 어텐션은
- 관절 레벨(로컬): 개별 관절별 특징에 집중하고,
- 뼈대 레벨(글로벌): 전체 스켈레톤 구조의 일관성을 유지하며,
- 시간 레벨(동적): 다양한 시점 간 중요도를 동적으로 조정해가며
복합적으로 작용한다. 결과적으로 GTA-Net은 국소적·전역적·시간적 정보를 모두 활용해, 복잡한 움직임 속에서도 정확하고 안정적인 3D 포즈 추정을 실현할 수 있다.

4. Experiments
4.1 데이터셋
- Human3.6M
- 연구실 내 4대 카메라로 촬영된 약 360만 장의 이미지
- 11명 배우가 15가지 동작(걷기, 앉기, 대화 등)을 수행
- 각 프레임에 2D / 3D 키포인트 정밀 어노테이션 제공
- 대규모·다양한 시나리오 덕분에 모델 일반화 능력 강화
- MPI-INF-3DHP
- 실내 / 실외·복합 환경에서 다중 피사체 촬영
- 다양한 조명·배경·포즈 조건을 포함한 2D / 3D 어노테이션
- 실제 환경 적응력을 검증하기에 적합
- HumanEva-I
- 소규모지만 엄격히 제어된 세트에서 걷기·달리기·손 흔들기 등 동작 수집
- 모션캡처+다중 카메라 동기화로 얻은 고품질 3D 어노테이션
- 알고리즘 성능 벤치마크용으로 널리 사용
이 세 가지 데이터셋을 통합 학습 / 검증함으로써 GTA-Net의 강인성, 안정성, 정확성을 확보
4.2 구현 세부사항
- 데이터 전처리
- 2D 키포인트 검출 후 $[0,1]$로 정규화
- 데이터 증강
- 랜덤 회전(±30°), 좌 / 우 반전, 밝기 조절, 노이즈 추가
- MPI-INF-3DHP에는 추가로 조명 정규화 적용
- HumanEva-I는 소규모이므로 5fold cross validation 적용
- 학습 설정
- 가중치 초기화: He initialization (ReLU와 호환)
- 최적화: Adam, 초깃값 lr=0.001, weight decay
- 스케줄러: 검증 손실 5 epoch 연속 개선 없으면 lr 절반
- 배치 크기: 32, Epoch: 최대 100, Early Stopping: 10 epoch 개선 없으면 중단
- 하드웨어: NVIDIA A100 GPU, epoch 당 약 10분 소요
- 하이퍼파라미터 튜닝
- Joint-GCN / Bone-GCN: 3 layer, 각 128 채널
- Attention-TCN: 8 attention heads, kernel size=5
- Dropout 0.3 / BatchNorm 적용
4.3 Ablation Study
- oint-GCN 제거 → 정확도 ↓
- Bone-GCN 제거 → 구조 일관성 ↓
- Attention-TCN → 일반 TCN → 시공간 패턴 포착 ↓
- 각 모듈을 하나씩 제거하며 3D 자세 추정 정확도 및 안정성 기여도 평가
4.4 평가 지표
- MPJPE (Mean Per Joint Position Error)
- 프로토콜 #1: 중힙(midhip) 정렬 후 평균 거리 오차
- 프로토콜 #2: rigid alignment 후 계산
- MPI-INF-3DHP 일반화 평가
- 학습: Human3.6M → 테스트: MPI-INF-3DHP
- PCK (Percentage of Correct Keypoints)
- AUC (Area Under Curve)
- HumanEva-I: MPJPE로만 평가
이상의 실험 설정과 지표를 통해, GTA-Net의 정확도, 강인성, 실시간성, 일반화 능력이 입증되었다.
5. Results
5.1 State of the Art 비교
- Human3.6M 데이터셋
- Protocol #1 (원위치 정렬 MPJPE)
- GTA-Net(GT 입력): 모든 동작 평균 MPJPE 최저 → 최고 성능
- GTA-Net(CPN 입력): GT 버전보다는 다소 높지만, 특히 WalkD/WalkT 같은 동적 동작에서 기존 기법들보다 우수
- 비결: Joint-GCN + Bone-GCN의 조합으로 국소·전역 스파이오-템포럴 관계를 정밀 포착
- Protocol #2 (rigid alignment 후 MPJPE)
- GTA-Net(GT) 여전히 대다수 동작에서 최저 MPJPE 달성
- 계층적 어텐션(Hierarchical Attention)이 멀티레벨 중요한 특징에 집중
- 결과: 복합 동작 인식에서 더욱 두드러진 이점
- HumanEva-I 데이터셋
- Walk 시퀀스: S1 = 11.7 mm, S2 = 9.4 mm, S3 = 25.7 mm ⇒ 평균 15.0 mm (기존 기법 비교 우위)
- Jog 시퀀스: S1/S3는 일부 기법에 근소하게 뒤처지지만, 전체 평균 여전히 15.0 mm 유지
- 의미: 다양한 동작 유형에 걸쳐 일관된 성능 우위
- MPI-INF-3DHP 데이터셋
- PCK: 95.2% → 기존 최고(94.4%) 대비 우위
- AUC: 70.8% → 전반적 안정성·정확성 개선
- MPJPE: 48.0 mm → 기존 최고(54.9 mm) 대비 낮음
- 의미: 복잡·다양한 장면에서 정밀하고 안정적인 3D 포즈 추정
- Protocol #1 (원위치 정렬 MPJPE)
5.2 추론 속도 비교 (FPS)
| Receptive Field | GTA-Net (layer) | GTA-Net (frame) | VPoseNet (LKyer) | GraFormer (Layer) |
| 32 | 1200 FPS | 100 FPS | 950 FPS | 900 FPS |
| 64 | 1050 FPS | 75 FPS | 820 FPS | 800 FPS |
| 128 | 900 FPS | 50 FPS | 680 FPS | 700 FPS |
* GTA-Net은 레이어별 순차 처리 / 단일 프레임 처리 모두에서 월등히 빠름
* 저전력 IoT 기기에서도 실시간 피드백 가능
5.3 Ablation Study
| 구성 요소 제거 | Human3.6M | HumanEva-I | MPI-INF-3DHP |
| 원본 GTA-Net | 32.2 mm | 15.0 mm | 48.0 mm |
| – Joint-GCN | 38.1 mm | 21.2 mm | 50.6 mm |
| – Bone-GCN | 37.8 mm | 20.8 mm | 50.1 mm |
| – Attention-TCN | 39.3 mm | 22.1 mm | 52.4 mm |
| – Hierarchical Attn | 37.5 mm | 20.5 mm | 50.3 mm |
Joint-GCN, Bone-GCN, Attention-TCN, Hierarchical Attention 각각이 성능 향상에 핵심적 기여
5.4 시각화 결과
- Human3.6M / HumanEva-I / MPI-INF-3DHP: 입력 이미지 ↔ GTA-Net 추정 ↔ 정답 일치
- 실제 스포츠 장면(축구, 야구, 웨이트, 스프린트 등): 복잡·고속 동작에서도 정밀한 관절 위치 및 전신 구조 포착
- 결론: GTA-Net은 다양한 환경·시나리오에서 안정적이고 정확한 3D 포즈 추정을 달성하며, 실시간 자세 교정 및 퍼포먼스 분석에 탁월한 잠재력을 지님.
6. Discussion
본 연구에서는 3D 포즈 추정과 IoT 기반 실시간 피드백을 결합한 청소년 스포츠 자세 교정 시스템 GTA-Net을 제안하였다. Joint-GCN + Bone-GCN을 통해 국소 관절 움직임과 전역 스켈레톤 구조를 동시에 포착하고, Attention-Augmented TCN으로 시간적 의존성을 섬세히 모델링함으로써 역동적인 실시간 자세 추정 문제를 해결했다. IoT 인프라를 통해 여러 카메라·센서 데이터를 분산 처리하여 실시간 교정을 가능케 했으며, 이는 전문 코치가 부족한 대규모 수업이나 캠프, 가정용 피트니스 기기, 재활치료 등 다양한 환경에서 응용될 수 있다.
GTA-Net은 MPJPE, PCK, AUC 등 주요 지표에서 뛰어난 견고성과 정확성을 보였으며, 복잡한 동작·부분 가림 상황에서도 안정적으로 동작했다. 다만 연산량 최적화(모델 프루닝·양자화)와 센서 융합·콘텍스트 인식 알고리즘 개선을 통해 저전력 IoT 기기에 최적화하는 후속 연구가 필요하다. 또한 더 다양한 자세를 포함한 데이터셋 확장과, VR/AR 트레이닝·프로스포츠·일상 활동 감시 등으로 응용 분야를 넓힐 계획이다.
7. Conclusion
GTA-Net은 3D 포즈 추정과 IoT 기술을 유기적으로 결합해 역동적인 스포츠 자세를 실시간으로 정밀 교정하는 시스템이다. 국소·전역 그래프 컨볼루션과 계층적 어텐션 강화 TCN의 조합으로 복잡한 동작에서도 높은 정확도를 유지하며, 분산 IoT 처리로 즉각적인 자세 피드백을 제공한다. 리소스 제약 환경에서도 적용 가능한 이 시스템은 향후 지능형 스포츠 모니터링, 부상 예방, 맞춤형 훈련 가이드 분야에 핵심 기술로 자리매김할 잠재력을 지닌다.
# GPT 가 알려준 간단한 샘플 코드
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
# ------------------------
# 1) 인접행렬 정규화 함수 (식 (2)–(3))
# Ā = D^{−1/2}(A + I)D^{−1/2}
# ------------------------
def normalize_adj(A):
N = A.shape[0]
A_prime = A + torch.eye(N, device=A.device) # 자기 연결 추가 (식 (2))
deg = A_prime.sum(dim=1) # D_ii = Σ_j A'_{ij}
D_inv_sqrt = torch.diag(deg.pow(-0.5))
return D_inv_sqrt @ A_prime @ D_inv_sqrt # 식 (3)
# ------------------------
# 2) IoT 스트리밍 시뮬레이터
# ------------------------
def iot_stream(batch_size, num_joints, num_bones):
"""매 100ms마다 2D 키포인트 + 3D GT 스트리밍"""
while True:
H0_j = torch.rand(batch_size, num_joints, 2) # 2D 관절
H0_b = torch.rand(batch_size, num_bones, 2) # 2D 뼈대
target_3d = torch.rand(batch_size, num_joints, 3) # 3D 정답
yield H0_j, H0_b, target_3d
time.sleep(0.1)
# ------------------------
# 3) GraphConv & GCNBlock: 논문 식 (1)–(4)
# ------------------------
class GraphConv(nn.Module):
def __init__(self, in_feats, out_feats):
super().__init__()
# W^(l) 에 해당하는 선형 변환
self.linear = nn.Linear(in_feats, out_feats, bias=False)
def forward(self, A_norm, H):
# Z = Ā H W (식 (4))
return self.linear(A_norm @ H)
class GCNBlock(nn.Module):
def __init__(self, in_feats, out_feats):
super().__init__()
self.gc = GraphConv(in_feats, out_feats)
self.bn = nn.BatchNorm1d(out_feats)
# 입력/출력 차원 다르면 residual 맞춤
self.residual = nn.Linear(in_feats, out_feats, bias=False) \
if in_feats != out_feats else nn.Identity()
def forward(self, A_norm, H):
# H^{(l+1)} = σ( Ā H^{(l)} W^{(l)} ) (식 (1))
out = self.gc(A_norm, H)
out = self.bn(out)
out = F.relu(out)
return out + self.residual(H) # 잔차 연결
# ------------------------
# 4) JointGCN / BoneGCN: 3개 레이어
# JointGCN = 국소 관절 그래프, BoneGCN = 전역 뼈대 그래프
# ------------------------
class JointGCN(nn.Module):
def __init__(self, in_feats, hidden_feats, n_layers=3):
super().__init__()
layers = [GCNBlock(in_feats, hidden_feats)]
for _ in range(n_layers - 1):
layers.append(GCNBlock(hidden_feats, hidden_feats))
self.net = nn.ModuleList(layers)
def forward(self, A_norm, H0):
H = H0
for layer in self.net:
H = layer(A_norm, H)
return H
class BoneGCN(nn.Module):
def __init__(self, in_feats, hidden_feats, n_layers=3):
super().__init__()
layers = [GCNBlock(in_feats, hidden_feats)]
for _ in range(n_layers - 1):
layers.append(GCNBlock(hidden_feats, hidden_feats))
self.net = nn.ModuleList(layers)
def forward(self, A_norm_bone, B0):
B = B0
for layer in self.net:
B = layer(A_norm_bone, B)
return B
# ------------------------
# 5) AttentionAugmentedTCN: 논문 식 (6)–(10) 개요
# - Causal Convolution (식 (6))
# - Dilated Convolution (식 (7))
# - Residual Connection (식 (9))
# - MSE Loss (식 (10))
# - Hierarchical Attention 간략화 (식 (11)–(15))
# ------------------------
class TemporalAttention(nn.Module):
def __init__(self, feat_dim):
super().__init__()
self.q = nn.Linear(feat_dim, feat_dim)
self.k = nn.Linear(feat_dim, feat_dim)
self.v = nn.Linear(feat_dim, feat_dim)
def forward(self, X):
# X: [T, B, N, D]
Q, K, V = self.q(X), self.k(X), self.v(X)
# e_{ij} = Q_i·K_j / sqrt(dk) (식 (12))
scores = torch.einsum('tbnd,sbnd->tbsn', Q, K) / (Q.size(-1)**0.5)
# α = softmax(e) (식 (13))
alpha = F.softmax(scores, dim=-1)
# out = Σ_j α_{ij} V_j (식 (14))
out = torch.einsum('tbsn,sbnd->tbnd', alpha, V)
return out
class DilatedConvBlock(nn.Module):
def __init__(self, in_c, out_c, kernel_size=3, dilation=1):
super().__init__()
padding = (kernel_size-1)//2 * dilation
self.conv = nn.Conv1d(in_c, out_c,
kernel_size,
padding=padding,
dilation=dilation)
self.bn = nn.BatchNorm1d(out_c)
def forward(self, x):
# x: [B, C, T]
out = self.conv(x)
out = self.bn(out)
return F.relu(out)
class AttentionAugmentedTCN(nn.Module):
def __init__(self, feat_dim, num_layers=4, kernel=3, dilation_base=2):
super().__init__()
self.tcn = nn.ModuleList()
for i in range(num_layers):
d = dilation_base ** i
self.tcn.append(DilatedConvBlock(feat_dim, feat_dim,
kernel, d))
self.attn = TemporalAttention(feat_dim)
def forward(self, X):
# X: [B, N, T, D]
B, N, T, D = X.shape
x = X.permute(0,2,1,3).reshape(B, N*D, T)
# 식 (6),(7),(9): layer-by-layer causal/dilated + residual
for layer in self.tcn:
out = layer(x)
x = out + x
# 시계열 재구성 후 어텐션 (식 (11)–(15))
out = x.view(B, N, D, T).permute(3,0,1,2) # [T,B,N,D]
out = self.attn(out)
return out[-1] # 마지막 시점
# ------------------------
# 6) GTANet: JointGCN + BoneGCN → TCN → 3D 좌표 (논문 전체 요약)
# ------------------------
class GTANet(nn.Module):
def __init__(self, num_joints, num_bones, in_dim=2, hid_dim=64):
super().__init__()
self.joint_gcn = JointGCN(in_dim, hid_dim)
self.bone_gcn = BoneGCN(in_dim, hid_dim)
self.tcn = AttentionAugmentedTCN(hid_dim*2)
self.fc_out = nn.Linear(hid_dim*2, 3) # 3D 예측
def forward(self, A_j, H0_j, A_b, H0_b):
# 1) 인접행렬 정규화 (식 3)
Ā_j = normalize_adj(A_j)
Ā_b = normalize_adj(A_b)
# 2) Joint-GCN 스트림 → 국소 관절 특징
J = self.joint_gcn(Ā_j, H0_j) # [B, N_j, hid_dim]
# 3) Bone-GCN 스트림 → 전역 뼈대 특징
Bf= self.bone_gcn(Ā_b, H0_b) # [B, N_b, hid_dim]
# 4) 결합 후 T=1 차원 추가 → TCN 준비
feat = torch.cat([J, Bf], dim=-1).unsqueeze(2) # [B, nodes, T, 2*hid]
# 5) TCN + Attention 처리 → 최종 시점 특징 획득
out = self.tcn(feat) # [B, nodes, 2*hid]
# 6) 3D 좌표 예측 (식 10: MSE loss)
return self.fc_out(out) # [B, nodes, 3]
# ------------------------
# 7) 학습 루프: IoT 스트리밍 + MSE loss (식 10) + EarlyStopping
# ------------------------
def train_model(model, iot_gen, A_j, A_b,
lr=1e-3, max_epochs=100, patience=10):
optimizer = torch.optim.Adam(model.parameters(),
lr=lr, weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.5, patience=5)
best_loss, wait = float('inf'), 0
for epoch in range(1, max_epochs+1):
model.train()
H0_j, H0_b, target = next(iot_gen)
pred = model(A_j, H0_j, A_b, H0_b)
loss = F.mse_loss(pred, target) # 식 (10)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step(loss)
print(f"Epoch {epoch:03d} | MSE: {loss.item():.4f}")
if loss.item() < best_loss:
best_loss = loss.item()
torch.save(model.state_dict(), 'best.pth')
wait = 0
else:
wait += 1
if wait >= patience:
print("Early stopping.")
break
if __name__ == '__main__':
B, N_j, N_b = 8, 17, 16
# 임의 대칭 인접행렬 생성 (실제론 관절 구조)
A_j = torch.randint(0,2,(N_j,N_j)).float().triu(1)
A_j = A_j + A_j.T
A_b = torch.randint(0,2,(N_b,N_b)).float().triu(1)
A_b = A_b + A_b.T
model = GTANet(N_j, N_b)
gen = iot_stream(B, N_j, N_b)
train_model(model, gen, A_j, A_b,
lr=1e-3, max_epochs=200, patience=10)