본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 해당 논문에서 발췌한 것입니다. 이 자료들은 논문의 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원 논문을 참고하여 확인하시기 바랍니다.
이 글을 읽기전에 먼저 읽어보세요:
DDPM은 데이터에 가우시안 노이즈를 단계적으로 주입하는 전방 확산 $q$을 **고정**해 두고, 이를 제거하는 가우시안 역과정의 평균만 신경망으로 학습하는 생성모형이다. 전방 과정은
$$
q(x_t \mid x_{t-1}) = \mathcal{N}\!\bigl(\sqrt{1-\beta_t}\,x_{t-1}, \, \beta_t I\bigr)
$$
로 정의되며, 닫힌형식
$$
q(x_t \mid x_0) = \mathcal{N}\!\bigl(\sqrt{\bar{\alpha}_t}\,x_0,\,(1-\bar{\alpha}_t)I\bigr)
$$
을 통해 임의 시점의 노이즈 상태를 직접 샘플링·학습할 수 있다.
역과정은
$$
p_\theta(x_{t-1} \mid x_t) = \mathcal{N}\!\bigl(\mu_\theta(x_t,t),\, \sigma_t^2 I\bigr)
$$
로 두되, $\sigma_t^2$는 시간 의존 상수로 고정하고, 평균은 “노이즈 $\varepsilon$”를 예측하는 $\varepsilon$-파라미터화로 추정하여 예측 노이즈와 실제 노이즈의 MSE로 학습을 단순화한다.
이 구성은 변분하한(ELBO) 최소화에 기반하며, 다중 노이즈 수준의 denoising score matching 및 (어닐링된) 랑주뱅 동역학과의 연결을 통해 이론적 정당성을 갖춘다. 샘플링은
$$
x_T \sim \mathcal{N}(0,I)
$$
에서 시작해 $t = T \to 1$로 역으로 진행되며, 각 단계는 “가우시안 평균 + 표준편차 × 잡음” 형태의 갱신으로 점진적 디노이징을 수행한다.
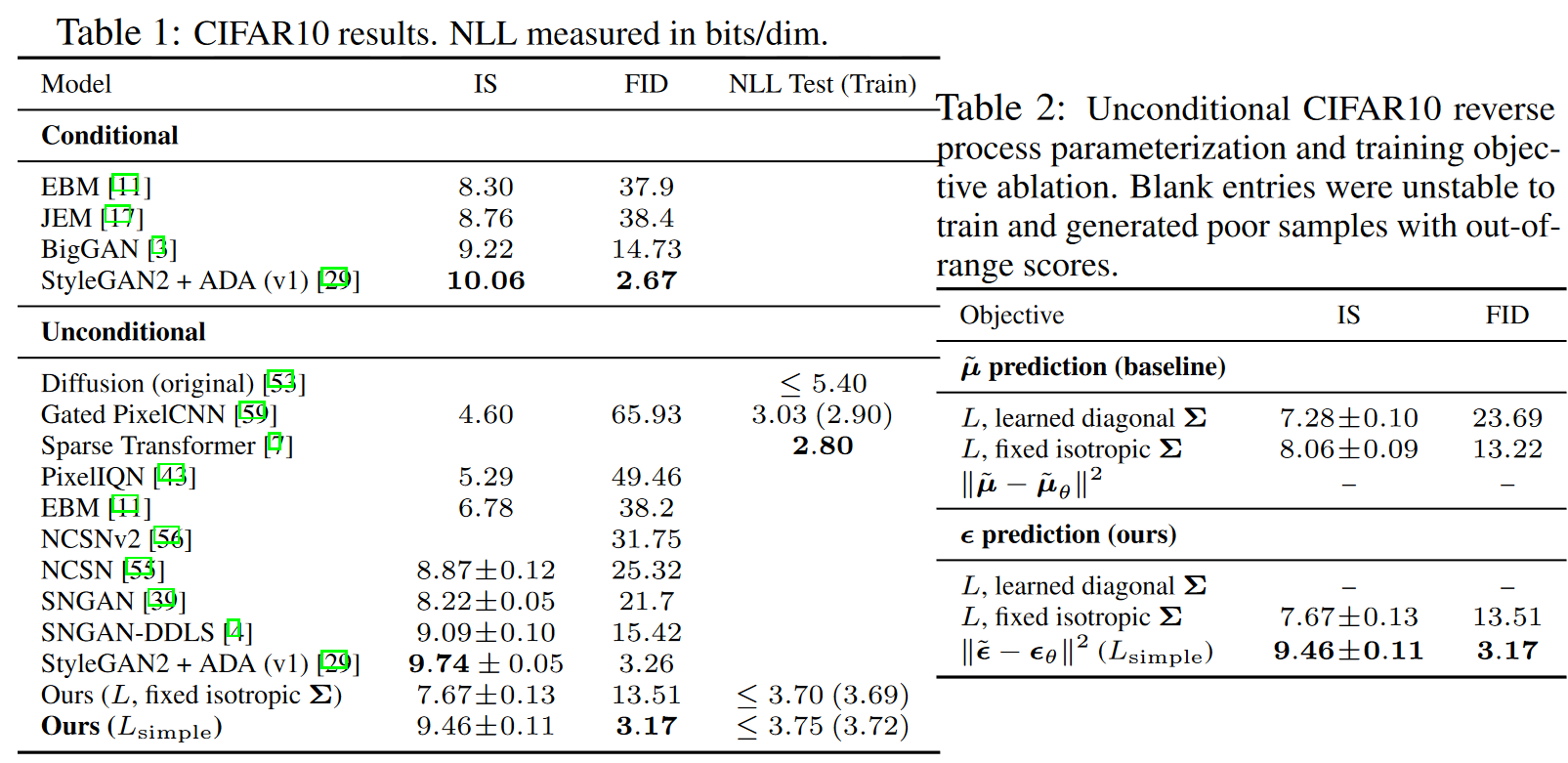
실험적으로 무조건 CIFAR-10에서 IS 9.46, FID 3.17을 달성했고, 256×256 LSUN에서는 ProgressiveGAN에 근접한 시각적 품질을 보였다. 결과적으로 DDPM은 분산 고정·평균 학습 + $\varepsilon$-예측(MSE)라는 단순한 설계로 안정적 학습과 고품질 샘플을 동시에 달성하는 확산계열의 표준 틀을 확립했다.
Abstract
이 논문은 비평형 열역학에서 영감을 받은 잠재 변수 모델인 확산 확률 모델을 사용하여 고품질 이미지를 합성하는 방법을 제시한다. 저자들은 확산 확률 모델과 잡음 제거 스코어 매칭, 그리고 랑제방 역학 간의 새로운 연결을 기반으로 설계된 가중 변분 경계를 활용하여 최고의 결과를 얻었다. 이 모델은 자기회귀 디코딩의 일반화로 해석할 수 있는 점진적 손실 압축 해제 방식을 자연스럽게 지원한다. 실험 결과, 무조건부 CIFAR10 데이터셋에서 9.46의 Inception score와 3.17의 최고 수준의 FID score를 달성했으며 , 256x256 LSUN에서는 ProgressiveGAN과 유사한 샘플 품질을 얻었다.
https://github.com/hojonathanho/diffusion
GitHub - hojonathanho/diffusion: Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models. Contribute to hojonathanho/diffusion development by creating an account on GitHub.
github.com
1. Instroduction
최근 다양한 종류의 심층 생성 모델들이 여러 데이터 양식에서 고품질의 샘플을 생성하는 데 성공했다. 특히, GANs, 자기회귀 모델(autoregressive models), flows, 그리고 변분 오토인코더(VAEs)는 인상적인 이미지와 오디오 샘플을 합성했다. 또한, GANs에 필적하는 이미지를 만들어내는 에너지 기반 모델링과 스코어 매칭 분야에서도 현저한 발전이 있었다.


이 논문은 확산 확률 모델을 개선한 연구를 제시한다. 확산 모델은 매개변수화된 Markov chain으로, 변분 추론을 이용해 훈련되며 유한한 시간 내에 데이터와 일치하는 샘플을 생성한다. 이 체인의 전이는 Markov chain인 확산 과정의 역을 학습하도록 설계되었다. 확산 과정은 신호가 사라질 때까지 샘플링의 반대 방향으로 데이터에 점진적으로 노이즈를 추가한다. 확산 과정이 소량의 가우시안 노이즈로 구성될 경우, 샘플링 체인 전이를 조건부 가우시안으로 설정하는 것으로 충분하며, 이는 매우 단순한 신경망 매개변수화를 가능하게 한다. 또한 확산 모델이 고품질의 샘플을 생성할 수 있음을 처음으로 보여준다. 기존에는 확산 모델이 정의하기 쉽고 훈련하기 효율적이라는 장점에도 불구하고, 고품질 샘플을 생성할 수 있는지에 대한 증명이 없었다. 저자들은 확산 모델이 다른 생성 모델들의 발표된 결과보다 더 나은 품질의 샘플을 생성할 수 있음을 입증했다. 특히, 이 논문의 주요 기여는 확산 모델의 특정 매개변수화가 훈련 과정에서는 다중 노이즈 수준에 대한 잡음 제거 스코어 매칭과, 샘플링 과정에서는 annealed Langevin dynamics과 동일한 효과를 낸다는 것을 밝힌 것이다. 이 매개변수화를 통해 가장 우수한 샘플 품질을 달성했기 때문에, 저자들은 이를 중요한 기여로 평가하고 있다. 확산 모델은 높은 샘플 품질을 달성했음에도 불구하고, 다른 가능도 기반 모델에 비해 경쟁력 있는 로그 가능도(log likelihoods)를 보이지 못한다. 다만, 에너지 기반 모델이나 스코어 매칭 모델이 AIS( AIS, Annealed Importance Sampling, 중요도 샘플링은 분포 차이가 크면 분산이 커져 비효율적이다. AIS는 온도 매개변수를 이용해 중간 분포를 단계적으로 거쳐 목표 분포에 도달함으로써 효율을 높인다)을 통해 얻은 추정치보다는 더 나은 로그 가능도를 기록했다. 저자들은 모델의 무손실 부호 길이(lossless codelengths)의 대부분이 사람의 눈에 보이지 않는 미세한 이미지 디테일을 묘사하는 데 사용된다는 점을 발견했다. 이를 손실 압축(lossy compression)의 관점에서 분석하여, 확산 모델의 샘플링 과정이 점진적 디코딩(progressive decoding)의 한 종류임을 보여준다. 이는 자기회귀 모델의 디코딩 방식을 크게 일반화한 것으로, 비트 순서에 따라 이미지를 점진적으로 생성하는 방식과 유사하다.
2. Background
확산 모델은 $p_\theta(x_0) := \int p_\theta(x_{0:T}) dx_{1:T}$ 형태의 잠재 변수 모델로, 여기서 $x_1,x_2,\cdots,x_t$는 데이터 $x_0 \sim q(x_0)$와 동일한 차원을 가진 잠재 변수들이다. 결합 분포 $p_\theta(x_{0:T})$는 역과정(reverse process)이라 불리며, $p(x_T) = \mathcal{N}(x_T; 0, I)$에서 시작하는 학습된 가우시안 전이(learned Gaussian transitions)를 가진 마르코프 체인으로 정의된다.
$$p_{\theta}(x_{0:T}) := p(x_{T})\prod_{t=1}^{T}p_{\theta}(x_{t-1}|x_{t}), \quad p_{\theta}(x_{t-1}|x_{t}) := \mathcal{N}(x_{t-1};\mu_{\theta}(x_{t},t),\Sigma_{\theta}(x_{t},t)) \tag{1}$$
확산 모델이 다른 잠재 변수 모델과 구별되는 점은 순방향 과정(forward process) 또는 확산 과정(diffusion process)이라고 불리는 특정 데이터 변환 과정이 학습되지 않고 고정되어 있다는 것이다. 이 과정은 마르코프 체인으로 정의된다. 이 마르코프 체인은 원본 데이터 $x_0$에 미리 정해진 분산 스케줄 $\beta_1, \cdots, \beta_T$에 따라 가우시안 노이즈를 점진적으로 추가하여, 최종적으로 완전한 노이즈($x_T$)로 변환한다. 각 단계 $t$에서 이전 상태 $x_{t-1}$에 노이즈를 추가해 다음 상태 $x_t$를 생성하는 확률 분포는 다음과 같은 가우시안 분포로 표현된다:
$$q(x_t|x_{t-1}):=\mathcal{N}(x_t; \sqrt{1-\beta_t}x_{t-1},\beta_tI) \tag{2}$$
이처럼 순방향 과정이 고정되어 있기 때문에, 모델은 이 과정을 되돌려 노이즈로부터 데이터를 생성하는 역과정을 학습하는 데 집중할 수 있다.
확산 모델의 훈련은 음의 로그 가능도($-\log p_{\theta}(x_0)$)에 대한 변분 경계(variational bound) $L$을 최적화하여 진행된다.
$$\mathbb{E}[-\log p_{\theta}(x_0)] \le \mathbb{E}_q\left[-\log \frac{p_{\theta}(x_{0:T})}{q(x_{1:T}|x_0)}\right] = \mathbb{E}_q\left[-\log p(x_T) - \sum_{t\ge1} \log \frac{p_{\theta}(x_{t-1}|x_t)}{q(x_t|x_{t-1})}\right] =: L \tag{3}$$이 경계는 모델의 역과정($p_{\theta}$)과 순방향 과정($q$) 간의 관계를 수식으로 정의한다. 훈련 과정에서 순방향 과정의 분산 $\beta_t$는 하이퍼파라미터로 상수로 고정하거나 재매개변수화(reparameterization) 기법을 통해 학습할 수 있다. 역과정의 표현력은 조건부 가우시안 분포의 선택을 통해 부분적으로 보장되는데, 이는 $\beta_t$ 값이 작을 때 역과정과 순방향 과정의 함수적 형태가 유사해지기 때문이다. 또한, 순방향 과정의 중요한 특징은 임의의 타임스텝 $t$에서 닫힌 형식(closed form)으로 $x_t$를 샘플링할 수 있다는 것이다. 이는 원본 데이터 $x_0$로부터 바로 $x_t$를 계산할 수 있음을 의미한다. 이를 위해 $\alpha_t := 1 - \beta_t$와 $\overline{\alpha}_t := \prod_{s=1}^{t}\alpha_s$라는 표기법을 사용하며, $x_t$의 분포는 다음과 같이 표현된다:
$$q(x_{t}|x_{0})=\mathcal{N}(x_{t};\sqrt{\overline{\alpha_{t}}}x_{0},(1-\overline{\alpha}_{t})I) \tag{4}$$
'닫힌 형식(closed form)'은 수학이나 컴퓨터 과학에서 어떤 문제를 유한한 개수의 잘 알려진 연산으로 명확하게 풀어낼 수 있는 형태를 의미한다.
닫힌 형식의 의미
수학에서 어떤 함수나 방정식이 '닫힌 형식'을 가진다는 것은, 그 해답을 덧셈, 뺄셈, 곱셈, 나눗셈, 거듭제곱, 로그, 삼각함수, 그리고 그 역함수와 같은 기본 함수들의 유한한 조합으로 표현할 수 있다는 뜻이다. 이는 무한한 합(급수)이나 복잡한 적분처럼 명확하게 표현하기 어려운 형태와 대비된다.
확산 모델에서 닫힌 형식의 중요성
논문에서 "닫힌 형식으로 $x_t$를 샘플링할 수 있다"는 것은, 원본 데이터 $x_0$에서 임의의 시간 $t$에 해당하는 노이즈 상태 $x_t$를 단계별로 노이즈를 추가하는 복잡한 반복 과정 없이도, 단 한 번의 계산으로 바로 구할 수 있다는 것을 의미한다. 일반적으로 $x_t$를 구하려면 $x_0 \to x_1 \to x_2 \to \cdots \to x_t$와 같이 매 단계마다 노이즈를 추가하는 계산을 반복해야 한다. 그러나 확산 모델의 순방향 과정은 이러한 반복 과정을 거치지 않고, $x_0$와 분산 스케줄($\overline{\alpha}_t$)을 이용해 $x_t$를 직접 계산하는 간편한 공식을 제공한다. 이러한 특성 덕분에 훈련 과정에서 특정 시점의 $x_t$를 효율적으로 계산할 수 있어 모델 학습의 효율성을 크게 높일 수 있다. 이 논문은 확률적 경사하강법을 이용하여 L의 임의 항을 최적화함으로써 확산 모델을 효율적으로 훈련하는 방법을 설명한다. 특히, 논문은 L을 재작성하여 분산을 줄이는 방법을 제시하며, 이 새로운 형태의 L은 다음과 같다:
$$L = \mathbb{E}_q[D_{KL}(q(x_T|x_0) \| p(x_T)) + \sum_{t>1} D_{KL}(q(x_{t-1}|x_t, x_0) \| p_\theta(x_{t-1}|x_t)) - \log p_\theta(x_0|x_1)] \tag{5}$$
수식 (5)를 자세히 살펴보면 확산 모델을 훈련시키기 위한 최종 목적 함수를 나타낸다. 이 수식은 모델이 이미지를 점진적으로 노이즈 제거하는 방법을 배우도록 설계되었으며, 전체 손실은 세 가지 주요 부분($L_T$, $L_{t-1}$, $L_0$)으로 나뉜다.
$L_T$: 최종 노이즈 단계
이 항은 노이즈 추가 과정(Forward Process)의 마지막 단계를 다룬다. $D_{KL}(q(x_T|x_0) \| p(x_T))$는 원본 이미지 $x_0$에 $T$ 단계에 걸쳐 노이즈를 추가했을 때의 최종 결과물 분포 $q(x_T|x_0)$와, 모델이 가정한 사전 분포(prior distribution)인 순수한 가우시안 노이즈 $p(x_T) = \mathcal{N}(x_T; 0, I)$ 사이의 KL 발산(KL Divergence)을 최소화하는 것을 목표로 한다. 논문에서는 $T$를 충분히 크게 설정하여 이 항이 훈련 중 상수가 되도록 만들어 사실상 무시할 수 있게 한다.
$L_{t-1}$: 중간 노이즈 제거 단계
이 항은 모델 학습의 핵심 부분으로, $\sum_{t>1}D_{KL}(q(x_{t-1}|x_t, x_0) \| p_\theta(x_{t-1}|x_t))$를 통해 모델이 한 단계씩 노이즈를 제거하는 방법을 배우도록 한다. 여기서 $p_\theta(x_{t-1}|x_t)$는 신경망 모델($\theta$)이 노이즈가 낀 이미지 $x_t$를 입력받아, 그보다 노이즈가 약간 덜 낀 이전 단계의 이미지 $x_{t-1}$의 분포를 예측하는 역방향 과정(Reverse Process)을 나타낸다. 반면, $q(x_{t-1}|x_t, x_0)$는 노이즈 낀 이미지 $x_t$와 원본 이미지 $x_0$를 모두 알고 있을 때의 이상적인 $x_{t-1}$의 분포에 해당하며, 이 분포는 수학적으로 깔끔하게 계산될 수 있다(tractable). 모델은 이 항을 최소화하여 예측이 정답 분포에 가까워지도록 훈련한다.
$L_0$: 최종 이미지 복원 단계
이 항은 노이즈 제거의 마지막 단계를 다룬다. $-\log p_\theta(x_0|x_1)$은 노이즈가 아주 약간 남은 이미지 $x_1$로부터 최종적으로 원본 이미지 $x_0$를 복원할 확률을 의미한다. 모델은 이 항을 통해 마지막 노이즈 제거 단계를 거쳐 최종적으로 선명하고 정확한 이미지를 생성하도록 학습한다.
결론적으로, 이 수식 (5)는 확산 모델이 (1) 최종 노이즈 상태를 순수 노이즈와 같게 만들고, (2) 각 중간 단계에서 정확하게 노이즈를 한 단계씩 제거하며, (3) 최종적으로 완벽한 이미지를 복원하도록 훈련시키는 정교한 목적 함수라고 할 수 있다.
추가로 원래의 변분 하한(Variational Lower Bound, VLB) 공식을 수학적으로 동일하게 변형한 결과다. 겉보기에는 달라 보이지만 본질은 같다. 그렇다면 왜 굳이 이렇게 복잡해 보이는 형태로 바꿨을까? 그 이유는 바로 학습의 안정성과 효율성 때문이다.
변분 하한(VLB)의 시작점
먼저, 이 모델의 가장 기본적인 변분 하한(VLB)은 다음과 같다.
$$L=\mathbb{E}_q[-\log\frac{p_{\theta}(x_{0:T})}{q(x_{1:T}|x_0)}]$$
이 식은 이론적으로는 맞지만, 실제 신경망을 학습시키기에는 두 가지 큰 문제가 있다.
- 높은 분산(High Variance): $p_{\theta}$와 $q$는 매우 긴 마르코프 연쇄(Markov chain)에 대한 확률 분포이다. 이 비율을 몬테카를로 샘플링으로 추정하면 분산이 매우 커져 학습이 불안정해진다.
- 계산의 어려움: 각 항을 직접 계산하기가 비효율적이다.
수식 (5)로의 변환: "더 쉬운 문제로 바꾸기"
저자들은 이 문제를 해결하기 위해 원래의 변분 하한을 수학적 트릭(주로 베이즈 정리)을 사용해 재구성했다. 이 과정은 논문의 부록 A에 자세히 설명되어 있다.핵심 아이디어는 각 스텝의 손실(loss)을 두 확률분포 사이의 거리(KL Divergence)로 표현하는 것이다. 이렇게 변환하면 다음과 같은 엄청난 이점을 얻게 된다.
1. 목표가 명확해진다.
수식 (5)의 핵심 항인 $D_{KL}(q(x_{t-1}|x_t, x_0) \| p_\theta(x_{t-1}|x_t))$를 다시 보자.
* $p_\theta(x_{t-1}|x_t)$: 우리 모델이 $x_t$를 보고 예측한 "이전 단계"의 모습이다.
* $q(x_{t-1}|x_t, x_0)$: 정답에 해당하는 "이전 단계"의 실제 모습이다.
즉, 원래의 복잡했던 VLB 수식이 "모델의 예측($p_\theta$)이 정답($q$)과 얼마나 다른가?"라는 직관적이고 명확한 문제로 바뀐다.
2. 계산이 매우 쉬워진다.
가장 중요한 부분이다. $p_\theta$와 $q$는 모두 가우시안 분포(Gaussian distribution)이다. 두 가우시안 분포 사이의 KL Divergence는 샘플링 없이 닫힌 형식(closed-form)의 간단한 공식으로 바로 계산할 수 있다. 이는 마치 복잡한 적분을 푸는 대신, 간단한 덧셈과 뺄셈으로 답을 구하는 것과 같다. 이 덕분에 분산이 크게 줄어들고(variance reduction) 학습이 매우 안정적이고 빨라진다. 저들은 변분 하한을 최소화하는 가장 똑똑하고 실용적인 방법으로 3개의 항을 최소화하는 것이 적합하다고 생각한 것으로 보인다.
확산 모델의 손실 함수 $L$이 수식 (3)에서 수식 (5)로 유도되는 과정은 논문 부록 A에 자세히 설명되어 있다. 핵심은 베이즈 정리(Bayes' theorem)를 활용해 수식을 재구성함으로써, 계산하기 쉬운 KL 발산(KL Divergence)의 합으로 만드는 것이다.
시작: 수식 (3) - 기본적인 변분 하한(VLB)
우리의 출발점은 음의 로그 가능도에 대한 변분 하한인 다음 수식에서 비롯된다:
$$L = \mathbb{E}_{q}[-\log\frac{p_{\theta}(x_{0:T})}{q(x_{1:T}|x_{0})}]$$
로그의 성질에 따라 이 식은 아래와 같이 분리할 수 있다.
$$L = \mathbb{E}_q[-\log p_{\theta}(x_{0:T}) + \log q(x_{1:T}|x_{0})]$$
1단계: 마르코프 연쇄 속성을 이용한 전개
확산 모델의 순방향 과정($q$)과 역방향 과정($p_\theta$)은 모두 마르코프 연쇄이다. 따라서 각 결합 확률(joint probability)을 조건부 확률의 곱으로 분해할 수 있다.
$$p_{\theta}(x_{0:T}) = p(x_T)\prod_{t=1}^{T}p_{\theta}(x_{t-1}|x_t)$$
$$q(x_{1:T}|x_0) = \prod_{t=1}^{T}q(x_t|x_{t-1})$$
이것을 위 식에 대입하면 다음과 같다.
$$L = \mathbb{E}_q\left[-\log p(x_T) - \sum_{t=1}^{T}\log p_\theta(x_{t-1}|x_t) + \sum_{t=1}^{T}\log q(x_t|x_{t-1})\right]$$
2단계: 항 재배열 및 분리
이제 수식의 항들을 재정렬하여 원하는 형태로 만들어간다. $t=1$일 때와 $t>1$일 때를 분리하고, 각 항을 짝지어 준다.
$$L = \mathbb{E}_q\left[-\log p(x_T) - \sum_{t=2}^{T}\log \frac{p_\theta(x_{t-1}|x_t)}{q(x_t|x_{t-1})} - \log \frac{p_\theta(x_0|x_1)}{q(x_1|x_0)}\right]$$
3단계: 핵심 트릭 - 베이즈 정리를 이용한 항 변환
여기서 가장 중요한 변환이 일어난다. 현재 분모에 있는 $q(x_t | x_{t-1})$는 우리가 원하는 목표 분포가 아니다. 우리는 계산 가능한(tractable) 순방향 과정의 사후 확률(posterior)인 $q(x_{t-1}|x_t, x_0)$를 수식에 등장시키고자 한다.
이를 위해 베이즈 정리를 이용하는데, 이 관계식은 확률론의 기본 원리들을 통해 다음과 같이 유도된다.
베이즈 정리 유도 과정
1. 조건부 확률의 기본 정의 적용
먼저, 조건부 확률의 기본 정의 $P(A|B) = \frac{P(A,B)}{P(B)}$를 $q(x_{t-1}|x_t, x_0)$에 적용한다.
$$q(x_{t-1}|x_t, x_0) = \frac{q(x_{t-1}, x_t|x_0)}{q(x_t|x_0)}$$
2. 분자의 결합 확률 분해 (곱셈 법칙)
다음으로, 1단계에서 얻은 분자 항 $q(x_{t-1}, x_t|x_0)$를 확률의 곱셈 법칙 $P(A,B) = P(A|B)P(B)$를 이용해 분해한다.
$$q(x_{t-1}, x_t|x_0) = q(x_t|x_{t-1}, x_0) \cdot q(x_{t-1}|x_0)$$
3. 종합하여 공식 유도
마지막으로, 2단계에서 분해한 분자를 1단계의 식에 다시 대입하면 최종 공식이 완성된다.
$$q(x_{t-1}|x_t, x_0) = \frac{q(x_t|x_{t-1}, x_0)q(x_{t-1}|x_0)}{q(x_t|x_0)}$$
이제 위 유도 과정을 통해 얻은 공식을, 우리가 바꾸고 싶었던 $q(x_t|x_{t-1})$에 대해 정리하면 다음과 같다. (이때 순방향 과정의 마르코프 속성에 의해 $q(x_t|x_{t-1}, x_0) = q(x_t|x_{t-1})$임을 이용한다.)
$$q(x_t|x_{t-1}) = q(x_{t-1}|x_t, x_0)\frac{q(x_t|x_0)}{q(x_{t-1}|x_0)}$$
이 결과를 2단계의 식에 있는 $\sum$ 내부의 $q(x_t|x_{t-1})$에 대입하면, 손실 함수는 다음과 같이 변환된다.
$$L = \mathbb{E}_q\left[-\log p(x_T) - \sum_{t=2}^{T}\log \frac{p_\theta(x_{t-1}|x_t)}{q(x_{t-1}|x_t, x_0) \frac{q(x_t|x_0)}{q(x_{t-1}|x_0)}} - \log \frac{p_\theta(x_0|x_1)}{q(x_1|x_0)}\right]$$
4단계: 소거 및 최종 정리
로그 내부의 곱셈을 덧셈으로 분리하고 정리하면, $\log \frac{q(x_t|x_0)}{q(x_{t-1}|x_0)}$ 형태의 합이 나타난다. 이 합은 망원 급수(telescoping sum)처럼 중간 항들이 모두 소거되고 처음과 끝 항만 남게 된다
$$\sum_{t=2}^{T}\log\frac{q(x_t|x_0)}{q(x_{t-1}|x_0)}=\log\frac{q(x_T|x_0)}{q(x_1|x_0)}$$
이 소거된 결과를 원래 식의 다른 항들과 합쳐서 정리하면 다음과 같은 깔끔한 형태가 된다.
$$L = \mathbb{E}_q\left[-\log\frac{p(x_T)}{q(x_T|x_0)} - \sum_{t=2}^{T}\log \frac{p_\theta(x_{t-1}|x_t)}{q(x_{t-1}|x_t, x_0)} - \log p_\theta(x_0|x_1)\right]$$
5단계: KL 발산 형태로 변환
이제 마지막 단계이다. KL 발산의 정의는 $D_{KL}(Q\|P) = \mathbb{E}_Q[\log\frac{Q(x)}{P(x)}]$이다. 위 식의 각 항은 정확히 이 KL 발산의 형태를 띠고 있다.
$$\mathbb{E}_q\left[-\log\frac{p(x_T)}{q(x_T|x_0)}\right] = \mathbb{E}_q\left[\log\frac{q(x_T|x_0)}{p(x_T)}\right] = D_{KL}(q(x_T|x_0)\|p(x_T))$$
$$\mathbb{E}_q\left[-\log\frac{p_\theta(x_{t-1}|x_t)}{q(x_{t-1}|x_t, x_0)}\right] = \mathbb{E}_q\left[\log\frac{q(x_{t-1}|x_t, x_0)}{p_\theta(x_{t-1}|x_t)}\right] = D_{KL}(q(x_{t-1}|x_t, x_0)\|p_\theta(x_{t-1}|x_t))$$
이를 적용하면 최종적으로 우리가 원하던 수식 (5)가 유도된다.
$$L = \mathbb{E}_q\left[D_{KL}(q(x_T|x_0)\|p(x_T)) + \sum_{t>1}D_{KL}(q(x_{t-1}|x_t, x_0)\|p_\theta(x_{t-1}|x_t)) - \log p_\theta(x_0|x_1)\right]$$
이 식은 KL 발산을 사용하여 순방향 과정 사후 분포 $q(x_{t-1}|x_t, x_0)$와 모델의 역과정 $p_\theta(x_{t-1}|x_t)$를 직접적으로 비교한다. 이 순방향 과정 사후 분포는 $x_0$가 주어졌을 때 다음과 같이 가우시안 분포로 표현되므로 계산이 용이하다:
$$q(x_{t-1}|x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t I) \tag{6}$$
$$where \;\ \tilde{\mu}_t(x_t, x_0) := \frac{\sqrt{\overline{\alpha}_{t-1}}\beta_t}{1-\overline{\alpha}_t}x_0 + \frac{\sqrt{\alpha_t}(1-\overline{\alpha}_{t-1})}{1-\overline{\alpha}_t}x_t \quad \text{and} \quad \tilde{\beta}_t := \frac{1-\overline{\alpha}_{t-1}}{1-\overline{\alpha}_t}\beta_t \tag{7}$$
모든 KL 발산 항이 가우시안 분포들의 비교로 이루어져 있기 때문에, 이들은 높은 분산을 갖는 몬테카를로 추정 방식 대신, 닫힌 형식 표현을 사용한 Rao-Blackwellized 방식으로 효율적으로 계산될 수 있다. 이로써 훈련 효율성이 크게 향상된다.
3. Diffusion models and denoising autoencoders
이 절은 확산 모델을 설계할 때 필요한 주요 선택 사항들(노이즈 분산, 모델 구조 등)을 제시한다. 이러한 설계를 위해 저자들은 확산 모델을 '디노이징 스코어 매칭'과 연결하여, 더 단순하고 효율적인 새로운 학습 목표 함수를 만들었다고 설명한다.결론적으로 이 모델의 우수성은 단순함과 좋은 실험 결과로 증명된다고 강조한다.
3.1 Forward process and $L_T$
먼저 모델 설계의 중요한 단순화 과정을 설명한다. 저자들은 노이즈를 추가하는 순방향 과정(forward process)의 분산($\beta_t$)을 학습시키는 대신, 미리 정해진 상수로 고정했다. 이 결정 덕분에 순방향 과정은 학습할 부분이 없어졌고, 결과적으로 전체 학습 목표에서 해당 부분($L_T$)을 제외하여 학습을 더 간단하게 만들 수 있었다.더 정확히 말하면, $L_T$가 학습과 무관한 상수(constant)가 되기 때문이다. 이 부분을 좀 더 자세히 풀어보겠다.
$L_T$가 0이 아닌 이유
$L_T = D_{KL}(q(x_T|x_0) \| p(x_T))$는 두 분포의 차이를 의미한다. 여기서 $p(x_T)$는 모델이 가정한 사전 분포로, 아무 정보도 없는 순수한 가우시안 노이즈($\mathcal{N}(0,I)$)이다. 반면, $q(x_T|x_0)$는 원본 이미지 $x_0$에 $T$ 단계의 노이즈를 추가한 결과로, 여전히 $x_0$에 대한 희미한 정보를 담고 있다. 따라서 두 분포는 완전히 같지 않으므로, KL 발산 값은 0이 아니다. 논문에 따르면 약 $10^{-5}$ bits/dim 정도로 0에 매우 가깝긴 하지만 0은 아니다.
'상수'이기에 무시하는 이유
그렇다면 왜 $L_T$를 무시할 수 있을까? 바로 학습 가능한 파라미터 $\theta$가 없기 때문이다. $L_T$를 결정하는 순방향 과정 $q$의 동작 방식은 오직 분산 값들인 $\beta_t$에 의해서만 결정된다. 저자들은 이 $\beta_t$ 값을 학습을 통해 찾는 대신, 미리 정해진 상수로 고정했다. 그 결과, 순방향 과정 $q$에는 학습을 통해 변하는 부분이 전혀 없게 된다. $L_T$ 값은 학습이 시작되기 전에 이미 고정된 값, 즉 상수가 된다. 우리가 모델을 학습시키는 목표는 손실 함수 $L$을 최소화하는 파라미터 $\theta$를 찾는 것이다. 이는 경사 하강법(gradient descent)을 통해 손실 함수를 $\theta$에 대해 미분하여 그래디언트를 계산함으로써 이루어진다.
$$\nabla_\theta L = \nabla_\theta(L_T + L_{t-1} + L_0)$$
여기서 $L_T$는 $\theta$와 무관한 상수이므로, 미분하면 0이 된다($\nabla_\theta L_T=0$). 따라서 $L_T$는 파라미터 업데이트에 아무런 영향을 주지 않으므로, 학습 과정에서 무시할 수 있는 것이다.
3.2 Reverse process and $L_{1:T-1}$
먼저 역방향 과정(노이즈 제거 과정)의 분산($\Sigma_{\theta}$)을 어떻게 설정할지에 대한 내용이다. 저자들은 분산을 복잡하게 학습시키는 대신, 미리 정해진 간단한 상수(학습시키지 않고, 시간에만 의존하는 상수인 $\sigma_t^2 I = \beta_t$)로 고정하는 방식을 택했다. 이 상수를 정하는 두 가지 방식($\beta_t$와 $\tilde{\beta}_t$)을 실험해 본 결과 성능이 비슷했으며, 이 두 방식은 각각 이론적으로 가능한 양 극단(데이터가 완전한 노이즈이거나, 하나의 점일 경우)에 최적화된 선택지여서 이론적 타당성도 갖추고 있다고 설명한다.
$$p_{\theta}(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_t, t), \Sigma_{\theta}(x_t, t))$$
두번째, 노이즈 제거 단계에서 신경망이 무엇을 예측하도록 만들 것인가에 대한 핵심 아이디어를 제시한다.가장 간단한 방법은 손실 함수(수식 8)를 살펴보면, 신경망의 예측값($\mu_{\theta}$)이 정답($\tilde{\mu}_t$)과 비슷해져야 함을 알 수 있다. 따라서 가장 쉬운 방법은 신경망이 정답인 $\tilde{\mu}_t$ 자체를 직접 예측하도록 학습시키는 것이다.하지만 저자들은 수식을 더 전개하여 $\tilde{\mu}_t$ 가 결국 노이즈가 낀 이미지 $x_t$'와 '원본 노이즈 $\epsilon$'으로 구성됨을 보였다(수식 10). 이를 통해, 복잡한 $\tilde{\mu}_t$ 를 통째로 예측하는 대신, 훨씬 간단한 '원본 노이즈 $\epsilon$ '만을 예측하도록 모델을 설계하는 것이 더 효과적일 수 있다는 새로운 방향을 제시한다.
$$L_{t-1}=\mathbb{E}_{q}\left[\frac{1}{2\sigma_t^2}||\tilde{\mu}_t(x_t,x_0)-\mu_{\theta}(x_t,t)||^2\right]+C \tag{8}$$
이는 곧 재매개변수화(reparameterization) 트릭**과 연결된다. 확산 모델에서 다음 분포를 다룬다.
$$
q(x_t \mid x_0) = \mathcal N\!\big(x_t;\,\sqrt{\bar{\alpha}_t}\,x_0,\,(1-\bar{\alpha}_t)I\big).
$$
여기서
평균(Mean):
$$
\mu = \sqrt{\bar{\alpha}_t}\,x_0,
$$
분산(Variance):
$$
\sigma^2 = (1-\bar{\alpha}_t),
$$
표준편차(Standard Deviation):
$$
\sigma = \sqrt{1-\bar{\alpha}_t}.
$$
이때 단순히 “분포에서 샘플링한다”라고 하면 미분이 불가능하지만, 재매개변수화 트릭을 적용하면 이를 결정론적 함수로 바꿀 수 있다. 즉,
$$
x_t(x_0,\epsilon) = \sqrt{\bar{\alpha}_t}\,x_0 + \sqrt{1-\bar{\alpha}_t}\,\epsilon,
\qquad \epsilon \sim \mathcal N(0,I).
$$
이 식은 원래의 확률적 샘플링 과정을 고정된 표준정규분포에서 뽑은 노이즈 $\epsilon$과 결정론적 선형 변환으로 다시 쓴 것이다.
따라서 학습 과정에서 신경망이 복잡한 평균 $\tilde{\mu}_t$ 전체를 직접 예측하는 대신, 단순히 $\epsilon$을 추정하도록 만들 수 있다. 이 접근은 두 가지 장점을 가진다. 첫째, 손실 함수가 평균 제곱 오차(MSE) 형태로 단순화되어 안정적 학습이 가능하다. 둘째, $\epsilon$은 표준정규분포에서 항상 동일한 통계적 성질을 가지므로, 모델이 보다 일반화된 방식으로 노이즈를 제거하는 학습을 수행할 수 있다.
결국, 확산 모델의 핵심은 노이즈 제거 문제를 평균 예측 문제가 아닌 단순한 노이즈 추정 문제로 전환하는 것이며, 이는 재매개변수화 트릭을 통해 실현된다.
KL 발산이 평균 제곱 오차(MSE)로 단순화되는 과정
확률적 모델 학습에서 중요한 손실 함수로는 Kullback–Leibler 발산(KL divergence)이 있다. KL 발산은 두 확률 분포 간의 차이를 정량적으로 측정하는데, 확산 모델(Diffusion Model)의 경우 이를 직접 계산하면 매우 복잡한 형태가 된다. 그러나 여기서 비교되는 두 분포가 모두 가우시안 분포라는 특수성이 핵심적인 단순화를 가능하게 한다.
우선 비교되는 두 분포는 다음과 같다. 첫째, 참값 분포는 $q(x_{t-1} \mid x_t, x_0)$이며 이는 평균이 $\tilde{\mu}_t(x_t, x_0)$, 분산이 $\tilde{\beta}_t I$인 가우시안 분포이다. 둘째, 모델이 예측하는 분포는 $p_\theta(x_{t-1} \mid x_t)$ 이며 이는 평균이 $\mu_\theta(x_t, t)$, 분산이 $\Sigma_\theta(x_t, t)$인 가우시안 분포이다. 논문에서 중요한 가정은 모델의 분산 $\Sigma_\theta$를 학습시키지 않고, 고정된 상수로 두는 것이다. 즉, 분산 항은 학습 파라미터 $\theta$와 무관하며 KL 발산을 계산할 때 상수항으로만 작용한다. 따라서 학습 과정에서 최적화되는 유일한 부분은 평균에 관한 항이며, 분산 관련 항은 단순히 무시할 수 있는 상수 $C$로 묶인다. 이와 같은 가정 하에서 두 가우시안 분포의 KL 발산은 다음과 같이 단순화된다.
$$
D_{KL}\big(q \parallel p_\theta\big)
= \frac{1}{2\sigma_t^2} \lVert \tilde{\mu}_t - \mu_\theta \rVert^2 + C
$$
여기서 남는 것은 두 분포의 평균 벡터 간 제곱 거리(norm squared)뿐이며, 이는 평균 제곱 오차(MSE)의 형태와 동일하다. 따라서 원래 복잡한 KL 발산 최소화 문제는 단순히 정답 평균 $\tilde{\mu}_t$와 모델이 예측한 평균 $\mu_\theta$ 사이의 MSE를 최소화하는 문제로 귀결된다. 결국 학습의 본질은 모델이 예측한 평균이 정답 평균에 최대한 가깝도록 만드는 과정이며, 이러한 수학적 성질 덕분에 KL 발산이 MSE 손실 함수로 치환될 수 있다.
가우시안–가우시안 사이의 KL 발산 일반식을 처음부터 유도하라. 또한 공분산을 고정(특히 동일)한다고 가정할 때 MSE 형태로 단순화되는 이유를 알아보자.
1. 설정
차원 $d$에서 $q(x)=\mathcal N(x;\mu_q,\Sigma_q),\qquad p(x)=\mathcal N(x;\mu_p,\Sigma_p)$ 로 두고, $D_{\mathrm{KL}}(q\|p)=\mathbb E_{x\sim q}\big[\log q(x)-\log p(x)\big]$ 를 계산한다.
가우시안 분포의 로그밀도는 확률밀도함수(PDF)의 정의에서 자연스럽게 도출된다. 다변량 가우시안 분포를 고려하면, 어떤 벡터 $x \in \mathbb{R}^d$에 대한 확률밀도는 다음과 같이 주어진다. 먼저 분포의 정의는
$$
p(x) = \frac{1}{(2\pi)^{d/2} |\Sigma|^{1/2}}
\exp\!\Big(-\tfrac{1}{2}(x-\mu)^\top \Sigma^{-1}(x-\mu)\Big)
$$
이다. 여기서 $\mu$는 평균 벡터, $\Sigma$는 공분산 행렬, $|\Sigma|$는 행렬식, $\Sigma^{-1}$은 역행렬이다. 이 확률밀도의 로그를 취하면 지수 부분이 선형적으로 전개되면서 세 가지 주요 항으로 분리된다. 첫째, $(2\pi)^{d/2}$에서 비롯된 $-\frac{d}{2}\log(2\pi)$ 항이다. 이는 모든 가우시안 분포에 공통적으로 나타나는 정규화 상수의 로그 값이다. 둘째, 공분산 행렬의 행렬식 $|\Sigma|$에서 나오는 $-\frac{1}{2}\log|\Sigma|$ 항이다. 이는 데이터가 퍼져 있는 정도, 즉 분포의 스케일을 반영한다. 셋째, 평균과의 차이를 측정하는 항으로, $-(1/2)(x-\mu)^\top \Sigma^{-1}(x-\mu)$이 있다. 이는 $x$가 평균 $\mu$에서 얼마나 떨어져 있는지를 공분산 구조에 따라 가중하여 측정한 이차형(quadratic form)이다. 따라서 가우시안 분포의 로그밀도는 다음과 같이 정리된다.
$$
\log p(x)
= -\frac{d}{2}\log(2\pi) - \frac{1}{2}\log|\Sigma|
- \frac{1}{2}(x-\mu)^\top \Sigma^{-1}(x-\mu).
$$ 결국, 로그밀도는 \*\*정규화 항(상수 부분)\*\*과 **분산·공분산에 따른 항**, 그리고 **평균과의 거리 항** 세 부분으로 나뉘며, 이로 인해 가우시안 로그밀도는 항상 선형항 없이 “이차형” 형태를 띠게 된다.
즉 가우시안의 로그밀도는
$$\log \mathcal N(x;\mu,\Sigma) =-\frac12\Big(d\log(2\pi)+\log|\Sigma|+(x-\mu)^\top\Sigma^{-1}(x-\mu)\Big).
$$
로 기술할 수 있다.
2. 기본 전개
위 식을 대입하면
$$
\begin{aligned}
D_{\mathrm{KL}}(q\|p)
&=\mathbb E_q[\log q(x)]-\mathbb E_q[\log p(x)]\\
&=\frac12\Big(\log|\Sigma_p|-\log|\Sigma_q|\Big)
+\frac12\Big(
\mathbb E_q[(x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p)]
-\mathbb E_q[(x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q)]
\Big).
\end{aligned}
$$
따라서 두 개의 이차형 기대값을 계산하면 된다.
3. 보조정리(이차형 기대값)
$x\sim\mathcal N(\mu_q,\Sigma_q)$, 대칭행렬 $A$에 대해
$$
\mathbb E_q\big[(x-\mu_p)^\top A (x-\mu_p)\big]
=\mathrm{tr}(A\Sigma_q)+(\mu_q-\mu_p)^\top A(\mu_q-\mu_p).
$$
증명은 $x-\mu_p=(x-\mu_q)+(\mu_q-\mu_p)$로 두고 전개하면, 교차항의 기대값이 0이 되어 바로 얻어진다.
이를 적용하면
$$
\mathbb E_q[(x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q)]
=\mathrm{tr}(\Sigma_q^{-1}\Sigma_q)=\mathrm{tr}(I_d)=d,
$$
$$
\mathbb E_q[(x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p)]
=\mathrm{tr}(\Sigma_p^{-1}\Sigma_q)+(\mu_q-\mu_p)^\top\Sigma_p^{-1}(\mu_q-\mu_p).
$$
4. 최종식
위 결과를 2절의 전개식에 대입하면
$$
\boxed{
D_{\mathrm{KL}}(q\|p)
=\frac12\Big(
\log\frac{|\Sigma_p|}{|\Sigma_q|}
-d+\mathrm{tr}(\Sigma_p^{-1}\Sigma_q)
+(\mu_p-\mu_q)^\top\Sigma_p^{-1}(\mu_p-\mu_q)
\Big).
}
$$
5. 중요한 특수형
1. 공분산이 동일한 경우 $\Sigma_p=\Sigma_q=\Sigma$:
$$
D_{\mathrm{KL}}(q\|p)=\frac12(\mu_p-\mu_q)^\top\Sigma^{-1}(\mu_p-\mu_q).
$$
2. 등방 가우시안 $\Sigma=\sigma^2 I$:
$$
D_{\mathrm{KL}}(q\|p)=\frac{1}{2\sigma^2}\,\|\mu_p-\mu_q\|_2^2.
$$
(특히 분산을 고정하면 최적화 시 $\mu_p$가 예측 평균 $\mu_\theta$인 경우, KL의 $\theta$-의존항은 정확히 평균 간 제곱거리(가중 MSE)로 귀결된다.)
$$
L_{t-1} - C
= \mathbb{E}_{x_0, \epsilon} \left[
\frac{1}{2\sigma_t^2} \,
\Big\| \,
\tilde{\mu}_t \Big( x_t(x_0,\epsilon), \; \frac{1}{\sqrt{\bar{\alpha}_t}} \big( x_t(x_0,\epsilon) - \sqrt{1-\bar{\alpha}_t}\,\epsilon \big) \Big)
- \mu_\theta(x_t(x_0,\epsilon), t)
\Big\|^2
\right]
\tag{9}$$
$$
= \mathbb{E}_{x_0, \epsilon} \left[
\frac{1}{2\sigma_t^2} \,
\Big\| \,
\frac{1}{\sqrt{\alpha_t}} \Big( x_t(x_0,\epsilon) - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \,\epsilon \Big)
- \mu_\theta(x_t(x_0,\epsilon), t)
\Big\|^2
\right]
\tag{10}$$
우선, 식 (10)은 다음과 같은 사실을 보여준다. 모델이 출력해야 할 평균 $\mu_\theta$는 단순히
$$
\mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha_t}}\Big(x_t - \beta_t \frac{1}{\sqrt{1-\bar{\alpha}_t}} \,\epsilon \Big)
$$
형태를 가져야 한다. 즉, 주어진 입력 $x_t$와 노이즈 $\epsilon$을 통해 간단히 표현된다. 여기서 핵심 아이디어는 $x_t$ 자체가 모델의 입력으로 주어지므로, 모델이 복잡한 $\tilde{\mu}_t$를 직접 맞출 필요가 없다는 것이다. 대신, $\epsilon$을 직접 예측하는 방식으로 파라미터화를 바꿀 수 있다. 이를 통해 새로운 식 (11)이 정의된다:
$$
\mu_\theta(x_t, t) = \tilde{\mu}_t \Big(x_t, \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \sqrt{1-\bar{\alpha}_t}\,\epsilon_\theta(x_t,t))\Big)
= \frac{1}{\sqrt{\alpha_t}}\Big(x_t - \beta_t \frac{1}{\sqrt{1-\bar{\alpha}_t}} \,\epsilon_\theta(x_t,t)\Big),
\tag{11}$$
여기서 $\epsilon_\theta(x_t,t)$는 신경망을 통해 $x_t$로부터 노이즈 $\epsilon$을 근사하는 함수이다. 이 파라미터화 하에서 역과정 샘플링은 다음과 같이 단순화된다.
$$
x_{t-1} = \frac{1}{\sqrt{\alpha_t}}\Big(x_t - \beta_t \frac{1}{\sqrt{1-\bar{\alpha}_t}} \,\epsilon_\theta(x_t,t)\Big) + \sigma_t z,
\quad z \sim \mathcal{N}(0,I).
$$
즉, $x_t$를 입력받아 신경망이 예측한 $\epsilon_\theta(x_t,t)$를 이용해 $x_{t-1}$을 계산하고, 여기에 새로운 노이즈 $z$를 추가하는 방식이다. 이는 마치 Langevin dynamics의 형태와 유사하며, $\epsilon_\theta$는 데이터 밀도의 기울기를 근사하는 역할을 한다. 더 나아가, 이러한 파라미터화를 적용하면 손실 함수 (10)는 놀랍게도 다음과 같은 단순한 형태로 바뀐다:
$$
\mathbb{E}_{x_0, \epsilon} \Bigg[ \frac{\beta_t^2}{2\sigma_t^2 \alpha_t(1-\bar{\alpha}_t)} \, \| \epsilon - \epsilon_\theta(\sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon, t)\|^2 \Bigg]. \tag{12}
$$
이는 식 (12)에 해당한다. 결국, 모델 학습은 다중 스케일의 노이즈 수준 $t$에서 원본 노이즈 $\epsilon$을 복원하는 문제와 동일해지며, 이는 곧 Denoising Score Matching과 같은 구조를 갖는다. 따라서 변분경계(variational bound)를 최적화하는 문제는, 여러 단계의 노이즈가 섞인 샘플에 대해 원본 노이즈를 정확히 예측하도록 모델을 훈련하는 문제와 동등하다. 이 단락은 결국 모델의 역방향 과정(노이즈 제거)을 어떻게 설계할 것인가에 대한 두 가지 핵심 전략을 요약하고, 저자들의 선택을 정당화한다.
- 전략 1 (기본 접근): 신경망이 디노이징된 이미지의 평균 $\tilde{\mu}_t$를 직접 예측하도록 학습한다.
- 전략 2 (저자들의 제안): 신경망이 원본 노이즈 $\epsilon$을 예측하도록 학습한다.
저자들은 전략 2, 즉 노이즈 예측 방식이 더 우월하다고 주장한다. 그 근거는 다음과 같다. 첫째, 이 방식은 Langevin dynamics 및 Denoising Score Matching과 이론적으로 깊은 연관성을 가지며, 따라서 확률적 역과정의 성격을 더 잘 반영한다. 둘째, 손실 함수가 단순한 평균 제곱 오차(MSE) 형태로 귀결되어 학습이 안정적이고 구현이 용이하다. 그러나 저자들은 단순히 이러한 이론적 우아함에만 의존하지 않는다. 실제로 제안된 방식이 기존 평균 예측 접근보다 실질적으로 더 나은 성능을 발휘하는지 확인하기 위해, 4장에서 두 전략을 직접 비교하는 실험을 제시할 것임을 예고한다.

3.3 Data scaling, reverse process decoder, and $L_0$
저자들은 먼저 이미지 데이터를 $\{0,1,\dots,255\}$ 범위의 정수값으로 가정한 후, 이를 선형적으로 $[-1,1]$ 구간에 스케일링한다. 이렇게 하면 역방향 과정(reverse process)을 수행하는 신경망이 항상 동일한 스케일의 입력을 다룰 수 있으며, 이는 표준 정규분포 $p(x_T)$로부터 시작하는 일관된 처리 과정을 보장한다.이산적 로그 가능도(discrete log-likelihood)를 얻기 위해, 역과정의 마지막 항을 독립적인 이산 디코더(discrete decoder)로 정의한다. 이 디코더는 가우시안 분포
$$
N\!\big(x_0;\,\mu_\theta(x_1,1),\,\sigma_1^2 I\big)
$$
에서 유도되며, 전체 확률은 좌표별 곱으로 표현된다.
$$
p_\theta(x_0 \mid x_1)
= \prod_{i=1}^D \int_{\delta^-(x_i^0)}^{\delta^+(x_i^0)}
N\!\big(x;\,\mu^i_\theta(x_1,1),\,\sigma_1^2\big)\, dx,
\tag{13}$$
여기서 $D$는 데이터 차원(픽셀 수), 윗첨자 $i$는 해당 좌표를 의미한다. 경계 구간은 다음과 같이 정의된다.
$$
\delta^+(x) =
\begin{cases}
\infty & \text{if } x=1, \\
x + \tfrac{1}{255} & \text{if } x<1,
\end{cases}
\qquad
\delta^-(x) =
\begin{cases}
-\infty & \text{if } x=-1, \\
x - \tfrac{1}{255} & \text{if } x>-1.
\end{cases}
$$
즉, 각 이산 값 $x_i^0$는 해당 픽셀 주변의 구간 $[\delta^-(x_i^0),\, \delta^+(x_i^0)]$로 확장되고, 그 구간에서 가우시안 분포의 확률질량을 적분해 이산적 확률을 얻는다. 이 접근법은 변분 오토인코더(VAE) 디코더 및 자회귀 모델에서 사용되는 이산화된 연속 분포(discretized continuous distribution)와 유사하다. 이를 통해 데이터에 인위적으로 노이즈를 추가하거나 스케일링 변환의 야코비안(Jacobian)을 로그 가능도에 반영하지 않고도, 변분경계(variational bound)가 실제 이산 데이터의 손실 없는 부호화 길이(lossless codelength)와 일치하게 된다. 마지막으로, 샘플링이 완료되면 결과는 잡음을 제거한(noiseless) 형태의 $\mu_\theta(x_1,1)$으로 출력된다.
3.4 Simplified training objective
앞서 정의한 역방향 과정과 디코더를 기반으로 하면, 변분경계(variational bound)는 식 (12)와 (13)에서 유도된 항들의 합으로 표현되며, 이는 파라미터 $\theta$에 대해 명백히 미분 가능하다. 따라서 이를 그대로 훈련에 사용할 수 있다. 그러나 저자들은 **샘플 품질을 높이고 구현을 단순화**하기 위해 변분경계의 변형된 형태를 사용하는 것이 더 유리하다고 보고, 다음과 같은 단순화된 목적함수를 제안한다.
$$
L_{\text{simple}}(\theta) := \mathbb{E}_{t, x_0, \epsilon}
\Big[ \, \| \, \epsilon - \epsilon_\theta\big(\sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\,\epsilon,\, t\big) \|^2 \, \Big],
\tag{14}
$$
여기서 $t$는 $\{1, \dots, T\}$ 사이에서 균등하게 샘플링된다.
- $t=1$인 경우: 이는 $L_0$와 동일하며, 이때 식 (13)에서의 이산 디코더 적분은 가우시안 확률밀도함수(PDF)에 bin 폭을 곱하는 방식으로 근사된다. 이 과정에서 $\sigma_1^2$ 및 경계 효과(edge effect)는 무시된다.
- $t>1$인 경우: 이는 식 (12)의 **가중치가 제거된(unweighted)** 버전에 해당한다. 이는 NCSN(Noise Conditional Score Network)에서 사용된 디노이징 스코어 매칭 손실의 가중치 방식과 유사하다.
여기서 중요한 점은, $\beta_t$는 고정된 forward process 분산이므로 $L_T$ 항은 나타나지 않는다는 것이다. 저자들은 이러한 단순화된 목적식 $L_{\text{simple}}$이 표준 변분경계와는 달리 손실 항목을 다르게 강조한다는 점을 지적한다. 특히, 본 논문에서 정의된 확산 과정은 작은 $t$에 해당하는 손실 항을 상대적으로 \*\*다운웨이트(down-weight)\*\*하게 되는데, 이는 작은 양의 노이즈만 제거하는 쉬운 작업보다, 더 큰 $t$에서의 어려운 디노이징 작업에 모델이 집중할 수 있도록 하기 위함이다. 실험 결과에서 확인되듯, 이러한 재가중(reweighting) 방식은 실제로 **더 나은 샘플 품질**을 만들어내는 데 도움이 된다.
4 Experiments
제안된 모델의 모든 실험에서 확산 단계 수를 $T = 1000$으로 설정하였다. 이는 샘플링 과정에서 필요한 신경망 평가 횟수를 기존 연구와 동일하게 맞추기 위함이다. Forward process의 분산은 $\beta_1 = 10^{-4}$에서 $\beta_T = 0.02$까지 선형적으로 증가하는 상수로 설정하였다. 이러한 값들은 데이터가 $[-1,1]$ 구간으로 스케일링되었을 때 충분히 작은 값이 되도록 선택되었으며, 그 결과 역과정(reverse process)과 정방향 과정(forward process)이 거의 같은 함수적 형태를 갖도록 한다. 동시에, 최종 시점 $x_T$에서의 신호 대 잡음비(SNR)가 가능한 낮아지도록 하여, 실제 실험에서는 $L_T = D_{\mathrm{KL}}(q(x_T|x_0)\,\|\,\mathcal{N}(0,I)) \approx 10^{-5}$ 비트/차원 수준으로 유지되었다. 역과정을 표현하는 모델로는 U-Net 백본(backbone)을 사용했으며, 이는 마스크되지 않은 PixelCNN++과 유사한 구조에 그룹 정규화(group normalization)를 전 구간에 적용한 형태이다. 네트워크의 파라미터는 시간축 전반에 걸쳐 공유되며, 시간 정보는 Transformer의 사인파 위치 임베딩(sinusoidal position embedding)을 통해 네트워크에 주어진다. 또한 16×16 해상도의 feature map 단계에서 self-attention 메커니즘을 적용하여 장거리 의존성을 모델링한다. 즉, 이 부분은 실험 설정(확산 단계 수, 분산 스케줄)과 신경망 아키텍처(U-Net 기반, self-attention 포함)를 설명하며, 모델이 안정적이고 효율적으로 학습될 수 있도록 한 설계상의 선택을 정리한 것이다.
4.1 Sample quality
또한 CIFAR-10 데이터셋에 대해 Inception Score, FID Score, 그리고 음의 로그 가능도(즉, 손실 없는 부호화 길이)를 비교하였다. 실험 결과, 제안된 비조건부(unconditional) 모델은 FID 점수 3.17을 기록하여, 기존 문헌에 보고된 대부분의 모델(심지어 클래스 조건부 모델까지 포함하여)보다 더 높은 샘플 품질을 달성하였다. 이 FID는 관례에 따라 학습 집합에 대해 계산된 값이다. 테스트 집합에 대해 계산했을 때는 5.24를 기록했으며, 이 값 역시 문헌에서 보고된 많은 학습 집합 기준 FID 점수보다 우수하다. 또한, 변분경계(true variational bound)에 기초해 모델을 학습했을 때는 더 나은 부호화 길이(codelength)를 얻을 수 있었으나, 단순화된 목적식(simplified objective)을 사용했을 때는 샘플 품질이 가장 높아졌다. 저자들은 이러한 결과를 CIFAR-10과 CelebA-HQ $256\times256$ 샘플(Fig. 1), LSUN $256\times256$ 샘플(Fig. 3 및 Fig. 4)에서 시각적으로 제시하였으며, 추가적인 결과는 부록 D에 포함하였다. 정리하면 본 결과는 단순화된 목적식이 부호화 효율에서는 다소 불리할 수 있으나 샘플 품질을 극대화하는 데 유리하다는 점을 실험적으로 보여준다.

4.2 Reverse process parameterization and training objective ablation
이들은 표 2에서 역방향 과정의 파라미터화 방식과 학습 목표에 따른 샘플 품질 차이를 비교하였다. 먼저, 기본 접근법인 $\tilde{\mu}$를 직접 예측하는 방법은 단순화된 목적식(평균제곱오차, 식 (14)와 유사한 형태)에서는 성능이 떨어지고, 반드시 진짜 변분경계(variational bound)\로 학습했을 때만 좋은 결과를 보였다. 또한, 역방향 과정의 분산을 학습하기 위해 파라미터화된 대각 행렬 $\Sigma_\theta(x_t)$를 변분경계에 포함시키는 경우를 실험했는데, 이는 학습을 불안정하게 만들었고 오히려 샘플 품질을 저하시켰다. 반면, 저자들이 제안한 노이즈 $\epsilon$ 예측 방식은 변분경계와 고정 분산으로 학습했을 때 $\tilde{\mu}$ 예측과 비슷한 성능을 보였으며, 단순화된 목적식으로 학습했을 때는 $\tilde{\mu}$ 예측보다 훨씬 우수한 성능을 달성하였다.
4.3 Progressive coding
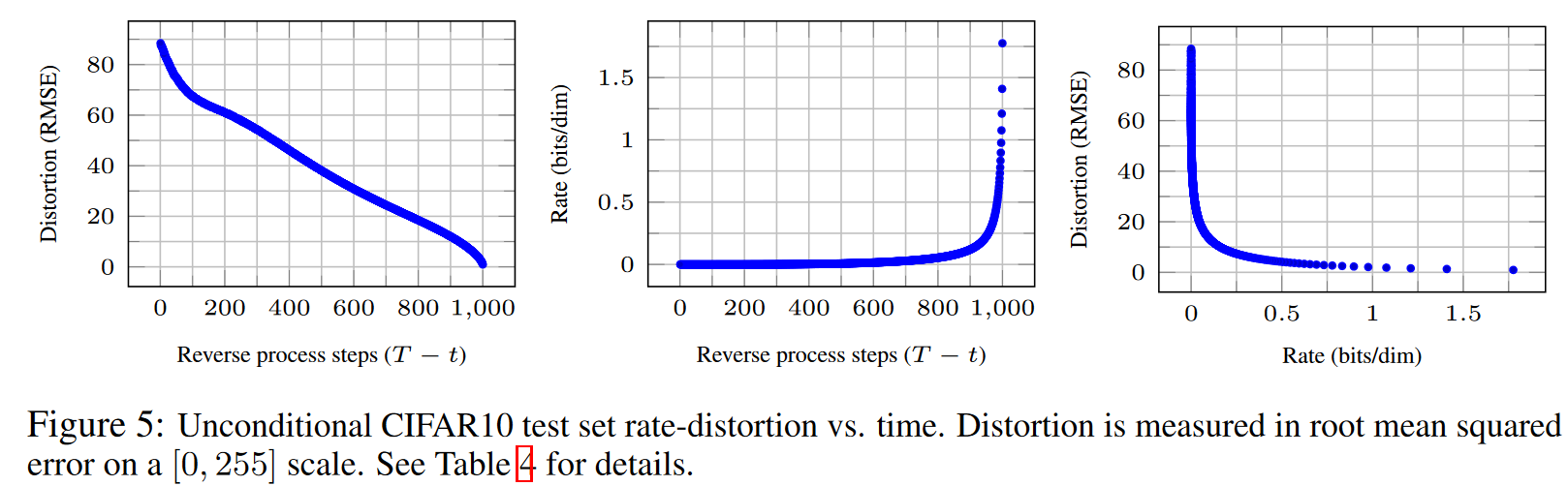
저자들은 CIFAR-10 모델의 부호화 길이(codelength)를 분석하였다. 실험 결과, 학습 데이터와 테스트 데이터 사이의 차이는 최대 0.03 비트/차원에 불과했으며, 이는 다른 가능도 기반 모델들과 유사한 수준으로, 제안된 확산 모델이 과적합을 일으키지 않음을 보여준다. 다만, 손실 없는 부호화 길이(lossless codelength)는 에너지 기반 모델이나 점수 매칭(score matching) 기법보다 우수했으나, 다른 가능도 기반 생성 모델들에 비해서는 경쟁력이 떨어졌다. 그럼에도 불구하고 샘플 품질이 매우 높았기 때문에, 저자들은 확산 모델이 우수한 손실 압축기(lossy compressor)로 작용하는 귀납적 편향(inductive bias)을 지닌다고 결론 내린다. 이를 더 구체적으로 보면, 변분경계 항 중 $L_1+\cdots+L_T$를 rate, $L_0$를 distortion으로 해석할 수 있다. CIFAR-10에서 가장 높은 샘플 품질을 보인 모델은 rate가 1.78 비트/차원, distortion이 1.97 비트/차원으로, 이는 0–255 스케일에서 RMSE(root mean squared error)가 0.95에 해당한다. 주목할 점은, 손실 없는 부호화 길이의 절반 이상이 지각적으로 구분 불가능한 왜곡(imperceptible distortion)을 기술하는 데 쓰였다는 것이다. 저자들은 이러한 특성을 더 탐구하기 위해 점진적 손실 압축(progressive lossy compression)을 제안하였다. 이는 Eq. (5)를 기반으로 하며, 최소 무작위 부호화(minimal random coding)와 같은 절차를 이용해 $x_T, \ldots, x_0$를 순차적으로 전송한다. 이때 수신자는 중간 단계 $x_t$까지의 정보를 받아들여 원본을
$$
\hat{x}_0 = \frac{x_t - \sqrt{1-\bar{\alpha}_t}\,\epsilon_\theta(x_t)}{\sqrt{\bar{\alpha}_t}}
\tag{15}
$$
로 점진적으로 추정할 수 있다. 실험에서 얻은 rate–distortion 곡선은 낮은 rate 구간에서 distortion이 급격히 감소함을 보여주었는데, 이는 대부분의 비트가 실제로는 지각 불가능한 왜곡을 기술한다는 사실을 뒷받침한다. 또한, 저자들은 점진적 생성(progressive generation)도 수행하였다. 이는 무작위 비트에서 점진적으로 복호화하면서 역과정을 따르는 방식으로, $x_0$를 점차 복원한다. 그 결과, 역과정이 진행됨에 따라 이미지의 대규모 구조가 먼저 나타나고 세부 요소가 나중에 채워지는 현상을 확인하였다. 이는 일종의 개념적 압축(conceptual compression)의 힌트를 제공한다. 마지막으로, 변분경계 식 (5)은 다음과 같이 다시 쓸 수 있다.
$$
L = D_{\mathrm{KL}}(q(x_T)\|p(x_T)) + \mathbb{E}_q \Big[ \sum_{t \ge 1} D_{\mathrm{KL}}(q(x_{t-1}|x_t)\|p_\theta(x_{t-1}|x_t)) \Big] + H(x_0).
\tag{16}
$$
여기서 만약 $T$를 데이터 차원에 맞추고, forward process가 각 단계에서 좌표를 하나씩 마스킹하도록 정의하며, $p_\theta$가 충분히 표현력이 있는 조건부 분포라고 가정하면, 학습은 결국 자기회귀 모델(autoregressive model)을 훈련하는 것과 동일해진다. 따라서 가우시안 확산 모델은 데이터를 단순 재배열하는 방식으로는 얻을 수 없는, 보다 일반화된 자기회귀적 구조를 갖는다고 볼 수 있다. 기존 연구가 좌표 재배열만으로도 샘플 품질에 큰 영향을 주는 inductive bias를 도입할 수 있음을 보였듯이, 가우시안 확산 또한 유사하거나 더 강력한 inductive bias를 제공하며, 특히 이미지에 가우시안 노이즈를 추가하는 것이 마스킹 노이즈보다 자연스럽다는 점에서 더욱 효과적일 수 있다고 저자들은 주장한다. 또한, 가우시안 확산의 길이 $T$는 데이터 차원과 동일할 필요가 없으므로, 저자들은 실험에서 $T=1000$을 사용했으며, 이는 CIFAR-10 (32×32×3)이나 CelebA-HQ (256×256×3) 이미지의 차원보다 훨씬 작다. 따라서 짧은 $T$는 빠른 샘플링을, 긴 $T$는 더 높은 모델 표현력을 가능하게 한다. 즉, 이 부분은 확산 모델이 손실 압축기로서의 귀납적 편향을 지니며, 동시에 자기회귀 모델과도 연결될 수 있는 이론적 해석을 제공함을 보여준다.

4.4 Interpolation
연구에서는 잠재공간(latent space) 보간(interpolation)을 통해 이미지 속성 변화를 탐구하였다. 구체적으로, 원본 이미지 $x_0, x'_0 \sim q(x_0)$를 확률적 인코더 $q(x_t|x_0)$에 통과시켜 $x_t, x'_t$를 얻은 뒤, 이를 선형 보간하여
$$
\bar{x}_t = (1-\lambda)x_t + \lambda x'_t
$$
를 구성한다. 이후 역과정(reverse process)을 통해 이를 이미지 공간으로 복원하면
$$
\bar{x}_0 \sim p(x_0|\bar{x}_t)
$$
이 된다. 이 과정은 단순 선형 보간으로 인해 발생하는 잡음을 제거하고, 자연스러운 이미지를 생성하는 역할을 한다. 실험에서는 CelebA-HQ $256 \times 256$ 데이터셋을 사용하였으며, 보간 계수 $\lambda$를 달리하더라도 $x_t, x'_t$가 동일하게 유지되도록 노이즈를 고정하였다. $t=500$에서 얻어진 결과(Fig. 8, 오른쪽)는 원본 이미지의 복원뿐 아니라, 자세(pose), 피부 톤, 헤어스타일, 표정, 배경 등 다양한 속성이 매끄럽게 변화하는 그럴듯한 보간 이미지를 생성하였다. 다만 안경(eyewear)과 같은 일부 속성은 변화하지 않았다. 또한, $t$ 값이 커질수록 보간은 더 거칠고 다양해지며, $t=1000$에서는 전혀 새로운 샘플이 생성되는 모습도 확인할 수 있었다. 이로써 확산 모델의 역과정을 이용한 보간은 단순한 선형 보간의 한계를 넘어, 자연스럽고 고품질의 속성 변화 이미지를 생성할 수 있는 강력한 도구임이 입증되었다.
5 Related Work
저자들은 확산 모델이 비슷해 보이는 다른 생성 모델들―흐름 기반 모델(flow)이나 VAE―과의 차이를 강조한다. 확산 모델은 $q$에 학습 가능한 파라미터가 없고, 최상위 잠재변수 $x_T$가 원본 데이터 $x_0$와 거의 상호정보량이 0이 되도록 설계된다. 또한, 저자들이 제안한 노이즈 $\epsilon$ 예측 기반의 역과정 파라미터화는 확산 모델과 디노이징 스코어 매칭(denoising score matching)을 여러 노이즈 수준에서 수행하는 것, 나아가 샘플링 시 어닐링된 랑주뱅 동역학(annealed Langevin dynamics)과 연결됨을 보여준다. 다른 점은, 확산 모델은 로그 가능도를 직접 계산할 수 있고, 훈련 과정 자체가 변분추론을 통해 랑주뱅 샘플러를 명시적으로 학습한다는 것이다. 역으로 말하면, 특정 가중치가 적용된 디노이징 스코어 매칭은 곧 변분추론을 통해 랑주뱅 기반 샘플러를 학습하는 것과 동등하다. 이와 관련된 다른 마르코프 체인 전이 연산자 학습 방법으로는 infusion training, variational walkback, generative stochastic networks 등이 있으며, 스코어 매칭과 에너지 기반 모델(EBM) 간의 잘 알려진 연결 덕분에 본 연구는 최근의 EBM 연구에도 시사점을 제공한다. 마지막으로, 저자들은 rate–distortion 곡선을 변분경계 평가 한 번으로 시간축을 따라 계산하는 방식을 사용했는데, 이는 어닐링 중요도 샘플링(annealed importance sampling)에서 왜곡 패널티(distortion penalty)를 통해 곡선을 얻는 방법과 유사하다. 또한 제안된 점진적 디코딩(progressive decoding) 논리는 Convolutional DRAW 및 관련 모델과 연결되며, 자기회귀 모델의 부분 스케일 순서(subscale ordering)나 새로운 샘플링 전략 설계로 확장될 가능성도 있다. 결론적으로 이 단락은 확산 모델이 스코어 매칭·EBM·VAE·플로우·자기회귀 모델 등 다양한 생성 기법과 가지는 이론적 연결고리를 정리하면서, 제안된 접근이 갖는 확장 가능성과 응용 가능성을 강조한다.
6 Conclusion
이 논문을 통해 확산 모델을 통해 고품질의 이미지 샘플을 생성할 수 있음을 보였다. 또한 확산 모델이 변분추론을 통한 마르코프 체인 학습, 디노이징 스코어 매칭, 어닐링된 랑주뱅 동역학(및 에너지 기반 모델), 자기회귀 모델, 점진적 손실 압축과 이론적으로 연결됨을 밝혔다. 나아가, 확산 모델이 이미지 데이터에 대해 강력한 귀납적 편향(inductive bias)을 갖는다는 점을 강조하며, 향후 다른 데이터 유형과 다양한 생성 모델 및 기계학습 시스템의 구성 요소로서 그 활용 가능성을 탐구할 계획임을 제시하였다.