2.4 Discrete Distributions -THE BINOMIAL DISTRIBUTION
* 본 블로그 포스트에서 사용된 표, 이미지 및 기타 관련 자료는 "PROBABILITY AND STATISTICAL INFERENCE 9th Edition"에서 발췌한 것입니다. 이 자료들은 내용을 요약하고 이해를 돕기 위한 참고용으로 제공됩니다. 또한, 해석 과정에서 일부 오류가 있을 수 있으니 원본을 참고하여 확인하시기 바랍니다.
이항분포의 기본 가정 (Basic Assumptions of Binomial Distribution)
1. 독립 시행 (Independent Trials):
- 각 시행은 다른 시행의 결과에 영향을 받지 않습니다.
2. 고정된 시행 횟수 (Fixed Number of Trials):
- 시행 횟수 \( n \)은 미리 정해져 있습니다.
3. 두 가지 결과 (Two Possible Outcomes):
- 각 시행의 결과는 성공(success) 또는 실패(failure)로 구분됩니다.
4. 일정한 성공 확률 (Constant Success Probability):
- 각 시행에서 성공할 확률 \( p \)는 동일합니다.
이항분포 정의 (Definition of Binomial Distribution)
이항분포는 고정된 시행 횟수 \( n \)과 각 시행에서 성공할 확률 \( p \)에 의해 정의됩니다. 성공 횟수를 나타내는 확률 질량 함수(PMF)는 다음과 같습니다:
\[P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}\]
- \( X \): 성공 횟수를 나타내는 확률 변수.
- \( \binom{n}{k} \): 조합의 수, \( \binom{n}{k} = \frac{n!}{k!(n-k)!} \).
- \( k \): 성공 횟수 (\( k = 0, 1, 2, \dots, n \)).
이항분포의 성질 (Properties of Binomial Distribution)
1. 기대값 (Mean): \( E[X] = np \)
2. 분산 (Variance): \( \text{Var}[X] = np(1-p) \)
3. 표준편차 (Standard Deviation): \( \sigma = \sqrt{np(1-p)} \)
이항분포의 모멘트 생성 함수 (MGF of Binomial Distribution)
모멘트 생성 함수(MGF)는 분포의 특성을 요약하고, 기대값과 분산을 포함한 모멘트를 도출하는 데 유용합니다.
이항분포 \( X \sim b(n, p) \)의 MGF는 다음과 같습니다:
\[M_X(t) = \left[ p e^t + (1-p) \right]^n\]
- \( M_X(t) \): 모멘트 생성 함수.
- MGF를 이용하여 \( E[X] \)와 \( \text{Var}[X] \)를 계산할 수 있습니다.
표본 추출과 이항분포의 관계 (Relation to Sampling Methods)
1. 복원 추출 (Sampling with Replacement):
- 각 공을 추출한 후 다시 항아리에 넣는 경우.
- 성공 확률 \( p = \frac{N_1}{N_1 + N_2} \)에서 성공 횟수 \( X \)는 이항분포 \( b(n, p) \)를 따릅니다.
2. 비복원 추출 (Sampling without Replacement):
- 각 공을 추출한 후 다시 넣지 않는 경우.
- 성공 횟수 \( X \)는 초기하분포(Hypergeometric Distribution)를 따릅니다.
- 초기하분포의 확률 질량 함수(PMF)는 다음과 같습니다:
\[f(x) = \frac{\binom{N_1}{x} \binom{N_2}{n-x}}{\binom{N_1 + N_2}{n}}\]
- 여기서 \( x \): 성공 횟수, \( x \leq n, x \leq N_1, n-x \leq N_2 \).
3. 큰 모집단과 작은 표본 (Large Population and Small Sample):
- \( N_1 + N_2 \)가 매우 크고 \( n \)이 상대적으로 작을 경우, 복원/비복원 추출의 차이가 거의 없으며, 이항분포로 근사 가능.
그래프 비교 (Graphical Comparison)
- 하기 그래프에서는 복원 추출과 비복원 추출의 확률 분포를 비교합니다.
- \( N_1 + N_2 \)가 클수록 두 분포가 유사하며, 이는 복원 추출을 이항분포로 근사할 수 있음을 보여줍니다.
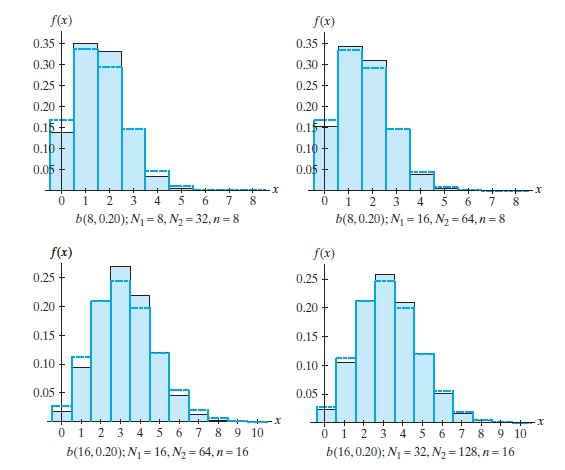
예제 (Examples)
1. 복원 추출 예제 (Example of Sampling with Replacement):
- 성공 공이 5개, 실패 공이 10개 있는 항아리에서 복원하여 8번 추출.
- 성공 확률 \( p = \frac{5}{15} = 1/3 \).
- 성공 횟수 \( X \)는 \( b(8, 1/3) \)를 따릅니다.
- 예: \( P(X = 3) = \binom{8}{3} (1/3)^3 (2/3)^5 \).
2. 비복원 추출 예제 (Example of Sampling without Replacement):
- 성공 공이 5개, 실패 공이 10개 있는 항아리에서 비복원하여 8번 추출.
- 성공 횟수 \( X \)는 초기하분포를 따릅니다:
\[P(X = 3) = \frac{\binom{5}{3} \binom{10}{5}}{\binom{15}{8}}\]
연습문제 (Exercises)
1. \( n = 10 \), \( p = 0.3 \)일 때, \( X = 4 \)의 확률을 계산하시오.
2. \( N_1 = 7 \), \( N_2 = 13 \), \( n = 5 \)일 때, 비복원 추출에서 성공 횟수 \( X = 2 \)의 확률을 계산하시오.
3. 복원 추출과 비복원 추출의 차이가 감소하는 조건을 설명하시오.
이항분포의 MGF 증명
MGF란 무엇인가요?
모멘트 생성 함수(MGF)는 확률 변수의 성질을 요약하는 도구입니다.
확률 변수 \( X \)에 대해 MGF는 다음과 같이 정의됩니다:
\[M_X(t) = E[e^{tX}]\]
- \( e^{tX} \): 확률 변수 \( X \)에 \( t \)라는 값을 곱한 뒤 지수 함수에 넣은 값.
- \( E[\cdot] \): 기대값을 계산하는 과정. \( X \)의 각 값에 대한 평균을 계산합니다.
1단계: 이항분포를 이해하기
1. 이항분포의 기본:
- \( X \): 성공 횟수 (0, 1, 2, ..., \( n \)).
- 성공 확률: \( p \), 실패 확률: \( 1-p \).
- 확률 질량 함수(PMF):
\[
P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}
\]
\( \binom{n}{k} = \frac{n!}{k!(n-k)!} \): \( n \)번 중 \( k \)번 성공하는 경우의 수.
2단계: MGF 정의 대입하기
MGF를 계산하려면 정의 \( M_X(t) = E[e^{tX}] \)를 사용합니다.
\[M_X(t) = \sum_{k=0}^{n} e^{tk} P(X = k)\]
여기서, \( P(X = k) \)를 이항분포의 PMF로 대체합니다:
\[M_X(t) = \sum_{k=0}^{n} e^{tk} \binom{n}{k} p^k (1-p)^{n-k}\]
3단계: 수식 간소화
이 식을 간단히 해봅시다:
1. \( e^{tk} \), \( p^k \), \( (1-p)^{n-k} \)를 묶습니다.
2. \(\binom{n}{k}\)는 조합의 수입니다.
\[M_X(t) = \sum_{k=0}^{n} \binom{n}{k} \left(p e^t\right)^k \left(1-p\right)^{n-k}\]
4단계: 이항 정리를 사용하기
이 식은 이항 정리를 떠올리게 합니다.
이항 정리에 따르면:
\[(a + b)^n = \sum_{k=0}^{n} \binom{n}{k} a^k b^{n-k}\]
우리의 식에서 \( a = p e^t \), \( b = 1-p \)로 볼 수 있습니다.
이 공식을 대입하면:
\[M_X(t) = \left(p e^t + (1-p)\right)^n\]
결론
모멘트 생성 함수는 다음과 같이 증명됩니다:
\[M_X(t) = \left[ p e^t + (1-p) \right]^n\]
쉽게 비유하자면:
1. \( p e^t \)는 "성공 확률에 성공 효과(\( e^t \))를 곱한 것"을 나타냅니다.
2. \( (1-p) \)는 "실패 확률"을 나타냅니다.
3. 이 두 가지를 \( n \)번 곱하는 것은 성공과 실패가 섞이는 모든 경우를 합친 것입니다.
\[(p e^t + (1-p))^n\]
이 식은 "모든 경우의 확률 효과를 모아둔 것"이라고 생각하면 됩니다!
연습문제 풀이
문제 1: \( n = 10 \), \( p = 0.3 \), \( X = 4 \)의 확률 계산
이항분포의 확률 질량 함수(PMF)를 사용하여 \( P(X = 4) \)를 계산합니다:
\[P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}\]
여기서:
- \( n = 10 \),
- \( k = 4 \),
- \( p = 0.3 \),
- \( 1-p = 0.7 \).
계산:
1. 조합 계산:
\[\binom{10}{4} = \frac{10!}{4!(10-4)!} = \frac{10 \cdot 9 \cdot 8 \cdot 7}{4 \cdot 3 \cdot 2 \cdot 1} = 210\]
2. 확률 계산:
\[P(X = 4) = 210 \cdot (0.3)^4 \cdot (0.7)^6\]
3. 세부 계산:
- \( (0.3)^4 = 0.0081 \),
- \( (0.7)^6 = 0.117649 \),
- \( P(X = 4) = 210 \cdot 0.0081 \cdot 0.117649 = 0.20012 \).
답:
\[P(X = 4) \approx 0.200\]
# R 코드
# Parameters
n <- 10
p <- 0.3
k <- 4
# Binomial Probability
P_X_equals_4 <- dbinom(k, size = n, prob = p)
print(P_X_equals_4)# Python 코드
from scipy.stats import binom
# Parameters
n = 10
p = 0.3
k = 4
# Binomial Probability
P_X_equals_4 = binom.pmf(k, n, p)
print(P_X_equals_4)
문제 2: \( N_1 = 7 \), \( N_2 = 13 \), \( n = 5 \), \( X = 2 \)의 확률 계산
이 경우는 초기하분포를 따릅니다. 초기하분포의 PMF는 다음과 같습니다:
\[P(X = x) = \frac{\binom{N_1}{x} \binom{N_2}{n-x}}{\binom{N_1 + N_2}{n}}\]
여기서:
- \( N_1 = 7 \), \( N_2 = 13 \), \( n = 5 \), \( x = 2 \),
- \( N_1 + N_2 = 20 \).
계산:
1. 분자 계산:
- \( \binom{N_1}{x} = \binom{7}{2} = \frac{7 \cdot 6}{2 \cdot 1} = 21 \),
- \( \binom{N_2}{n-x} = \binom{13}{3} = \frac{13 \cdot 12 \cdot 11}{3 \cdot 2 \cdot 1} = 286 \).
2. 분모 계산:
- \( \binom{N_1 + N_2}{n} = \binom{20}{5} = \frac{20 \cdot 19 \cdot 18 \cdot 17 \cdot 16}{5 \cdot 4 \cdot 3 \cdot 2 \cdot 1} = 15504 \).
3. 확률 계산:
\[P(X = 2) = \frac{\binom{7}{2} \binom{13}{3}}{\binom{20}{5}} = \frac{21 \cdot 286}{15504} = \frac{6006}{15504}\approx 0.3874\]
답:
\[P(X = 2) \approx 0.387\]
# R 코드
# Parameters
N1 <- 7
N2 <- 13
n <- 5
x <- 2
# Hypergeometric Probability
P_X_equals_2 <- dhyper(x, m = N1, n = N2, k = n)
print(P_X_equals_2)# Python 코드
from scipy.stats import hypergeom
# Parameters
N1 = 7
N2 = 13
n = 5
x = 2
total_population = N1 + N2
# Hypergeometric Probability
P_X_equals_2 = hypergeom.pmf(x, total_population, N1, n)
print(P_X_equals_2)
문제 3: 복원 추출과 비복원 추출의 차이가 감소하는 조건
복원 추출과 비복원 추출의 차이가 감소하는 조건은 다음과 같습니다:
1. 모집단 크기(\( N \))가 매우 클 때:
- 모집단 크기 \( N = N_1 + N_2 \)가 매우 크면, 각 샘플 추출 시 성공 확률 \( p = \frac{N_1}{N} \)이 거의 변하지 않으므로 두 방법 간 차이가 줄어듭니다.
2. 표본 크기(\( n \))가 모집단 크기 대비 작을 때:
- \( n \)이 \( N \)에 비해 작을수록 샘플링 후 성공 공의 비율 변화가 작아 비복원 추출이 복원 추출과 비슷해집니다.
3. 성공/실패 공의 비율이 비슷할 때:
- \( p \)와 \( 1-p \)가 균등할수록(예: \( p = 0.5 \)) 복원/비복원 추출의 차이가 더 적습니다.
답:
- 모집단 크기가 크고, 표본 크기가 작을수록 복원과 비복원의 차이가 감소합니다.
# R 코드
# Simulating probabilities for large population
N1 <- 1000 # Number of success balls
N2 <- 9000 # Number of failure balls
n <- 10 # Sample size
x <- 3 # Number of successes
# Hypergeometric
P_hyper <- dhyper(x, m = N1, n = N2, k = n)
# Binomial approximation
p <- N1 / (N1 + N2)
P_binomial <- dbinom(x, size = n, prob = p)
# Difference
difference <- abs(P_hyper - P_binomial)
print(c(P_hyper, P_binomial, difference))# Python 코드
from scipy.stats import hypergeom, binom
# Parameters
N1 = 1000 # Number of success balls
N2 = 9000 # Number of failure balls
n = 10 # Sample size
x = 3 # Number of successes
# Hypergeometric Probability
total_population = N1 + N2
P_hyper = hypergeom.pmf(x, total_population, N1, n)
# Binomial Approximation
p = N1 / total_population
P_binomial = binom.pmf(x, n, p)
# Difference
difference = abs(P_hyper - P_binomial)
print(f"Hypergeometric: {P_hyper}, Binomial: {P_binomial}, Difference: {difference}")